Cybersecurity researchers have uncovered a novel malware marketing campaign that leverages Google Sheets as a command-and-control (C2) mechanism.
The exercise, detected by Proofpoint beginning August 5, 2024, impersonates tax authorities from governments in Europe, Asia, and the U.S., with the purpose of focusing on over 70 organizations worldwide by way of a bespoke device referred to as Voldemort that is geared up to assemble data and ship extra payloads.
The suspected cyber espionage marketing campaign has not been attributed to a selected named risk actor. As many as 20,000 e-mail messages have been despatched as a part of the assaults.
These emails declare to be from tax authorities within the U.S., the U.Okay., France, Germany, Italy, India, and Japan, alerting recipients about modifications to their tax filings and urging them to click on on Google AMP Cache URLs that redirect customers to an intermediate touchdown web page.
What the web page does is examine the Person-Agent string to find out if the working system is Home windows, and in that case, leverage the search-ms: URI protocol handler to show a Home windows shortcut (LNK) file that makes use of an Adobe Acrobat Reader to masquerade as a PDF file in an try and trick the sufferer into launching it.
“If the LNK is executed, it’s going to invoke PowerShell to run Python.exe from a 3rd WebDAV share on the identical tunnel (library), passing a Python script on a fourth share (useful resource) on the identical host as an argument,” Proofpoint researchers Tommy Madjar, Pim Trouerbach, and Selena Larson mentioned.
“This causes Python to run the script with out downloading any information to the pc, with dependencies being loaded instantly from the WebDAV share.”
The Python script is designed to assemble system data and ship the info within the type of a Base64-encoded string to an actor-controlled area, after which it reveals a decoy PDF to the person and downloads a password-protected ZIP file from OpenDrive.
The ZIP archive, for its half, accommodates two information, a reliable executable “CiscoCollabHost.exe” that is prone to DLL side-loading and a malicious DLL “CiscoSparkLauncher.dll” (i.e., Voldemort) file that is sideloaded.
Voldemort is a customized backdoor written in C that comes with capabilities for data gathering and loading next-stage payloads, with the malware using Google Sheets for C2, information exfiltration, and executing instructions from the operators.
Proofpoint described the exercise as aligned to superior persistent threats (APT) however carrying “cybercrime vibes” owing to the usage of methods widespread within the e-crime panorama.
“Menace actors abuse file schema URIs to entry exterior file sharing assets for malware staging, particularly WebDAV and Server Message Block (SMB). That is achieved through the use of the schema ‘file://’ and pointing to a distant server internet hosting the malicious content material,” the researchers mentioned.
Moreover, Proofpoint mentioned it was capable of learn the contents of the Google Sheet, figuring out a complete of six victims, together with one which’s believed to be both a sandbox or a “identified researcher.”
The marketing campaign has been branded uncommon, elevating the chance that the risk actors forged a large web earlier than zeroing in on a small pool of targets. It is also potential that the attackers, possible with various ranges of technical experience, deliberate to contaminate a number of organizations.
“Whereas most of the marketing campaign traits align with cybercriminal risk exercise, we assess that is possible espionage exercise performed to help as but unknown last aims,” the researchers mentioned.
“The Frankensteinian amalgamation of intelligent and complicated capabilities, paired with very primary methods and performance, makes it tough to evaluate the extent of the risk actor’s functionality and decide with excessive confidence the final word objectives of the marketing campaign.”
The event comes as Netskope Menace Labs uncovered an up to date model of the Latrodectus (model 1.4) that comes with a brand new C2 endpoint and provides two new backdoor instructions that permit it to obtain shellcode from a specified server and retrieve arbitrary information from a distant location.
“Latrodectus has been evolving fairly quick, including new options to its payload,” safety researcher Leandro Fróes mentioned. “The understanding of the updates utilized to its payload permits defenders to maintain automated pipelines correctly set in addition to use the data for additional trying to find new variants.”
Discovered this text fascinating? Comply with us on Twitter and LinkedIn to learn extra unique content material we submit.
Retrieval-Augmented Era methods are progressive fashions throughout the fields of pure language processing since they combine the parts of each retrieval and era fashions. On this respect, RAG methods show to be versatile when the scale and number of duties which can be being executed by LLMs improve, LLMs present extra environment friendly options to fine-tune by use case. Therefore, when the RAG methods re-iterate an externally listed data through the era course of, it’s able to producing extra correct contextual and related contemporary data response. However, real-world purposes of RAG methods supply some difficulties, which could have an effect on their performances, though the potentials are evident. This text focuses on these key challenges and discusses measures which may be taken to enhance efficiency of RAG methods. That is primarily based on a latest discuss given by Dipanjan (DJ) on Enhancing Actual-World RAG Techniques: Key Challenges & Sensible Options, within the DataHack Summit 2024.
Understanding RAG Techniques
RAG methods mix retrieval mechanisms with giant language fashions to generate responses leveraging exterior information.
The core parts of a RAG system embody:
Retrieval: This part includes use of 1 or a number of queries to seek for paperwork, or items of knowledge in a database, or every other supply of information outdoors the system. Retrieval is the method by which an acceptable quantity of related data is fetched in order to assist in the formulation of a extra correct and contextually related response.
LLM Response Era: As soon as the related paperwork are retrieved, they’re fed right into a giant language mannequin (LLM). The LLM then makes use of this data to generate a response that’s not solely coherent but additionally knowledgeable by the retrieved information. This exterior data integration permits the LLM to offer solutions grounded in real-time information, slightly than relying solely on pre-existing data.
Fusion Mechanism: In some superior RAG methods, a fusion mechanism could also be used to mix a number of retrieved paperwork earlier than producing a response. This mechanism ensures that the LLM has entry to a extra complete context, enabling it to provide extra correct and nuanced solutions.
Suggestions Loop: Trendy RAG methods typically embody a suggestions loop the place the standard of the generated responses is assessed and used to enhance the system over time. This iterative course of can contain fine-tuning the retriever, adjusting the LLM, or refining the retrieval and era methods.
Advantages of RAG Techniques
RAG methods supply a number of benefits over conventional strategies like fine-tuning language fashions. Advantageous-tuning includes adjusting a mannequin’s parameters primarily based on a selected dataset, which may be resource-intensive and restrict the mannequin’s means to adapt to new data with out further retraining. In distinction, RAG methods supply:
Dynamic Adaptation: RAG methods enable fashions to dynamically entry and incorporate up-to-date data from exterior sources, avoiding the necessity for frequent retraining. Because of this the mannequin can stay related and correct at the same time as new data emerges.
Broad Data Entry: By retrieving data from a wide selection of sources, RAG methods can deal with a broader vary of matters and questions with out requiring in depth modifications to the mannequin itself.
Effectivity: Leveraging exterior retrieval mechanisms may be extra environment friendly than fine-tuning as a result of it reduces the necessity for large-scale mannequin updates and retraining, focusing as a substitute on integrating present and related data into the response era course of.
Typical Workflow of a RAG System
A typical RAG system operates via the next workflow:
Question Era: The method begins with the era of a question primarily based on the consumer’s enter or context. This question is crafted to elicit related data that may help in crafting a response.
Retrieval: The generated question is then used to go looking exterior databases or data sources. The retrieval part identifies and fetches paperwork or information which can be most related to the question.
Context Era: The retrieved paperwork are processed to create a coherent context. This context offers the mandatory background and particulars that may inform the language mannequin’s response.
LLM Response: Lastly, the language mannequin makes use of the context generated from the retrieved paperwork to provide a response. This response is predicted to be well-informed, related, and correct, leveraging the most recent data retrieved.
Key Challenges in Actual-World RAG Techniques
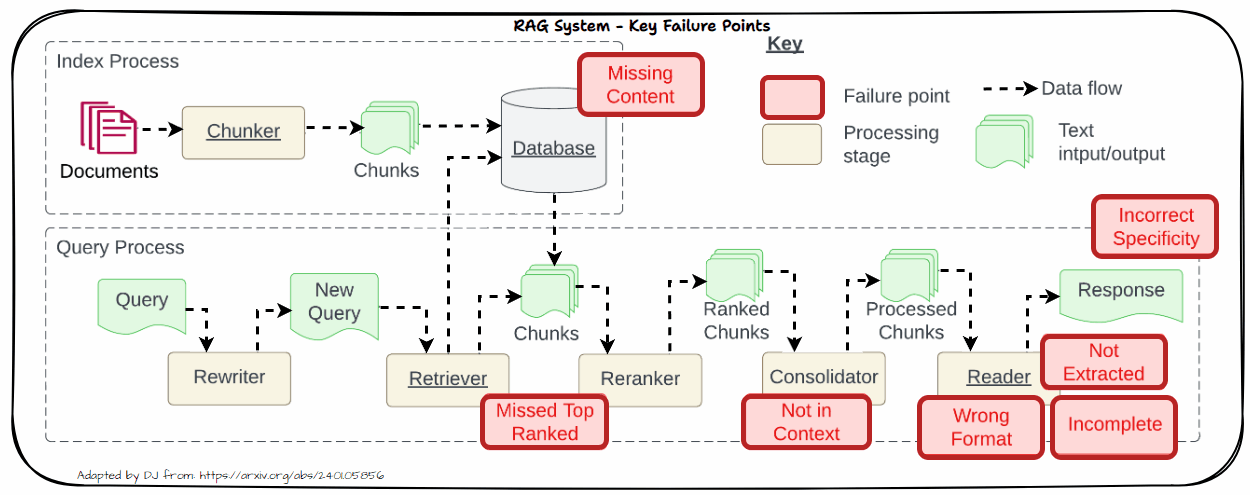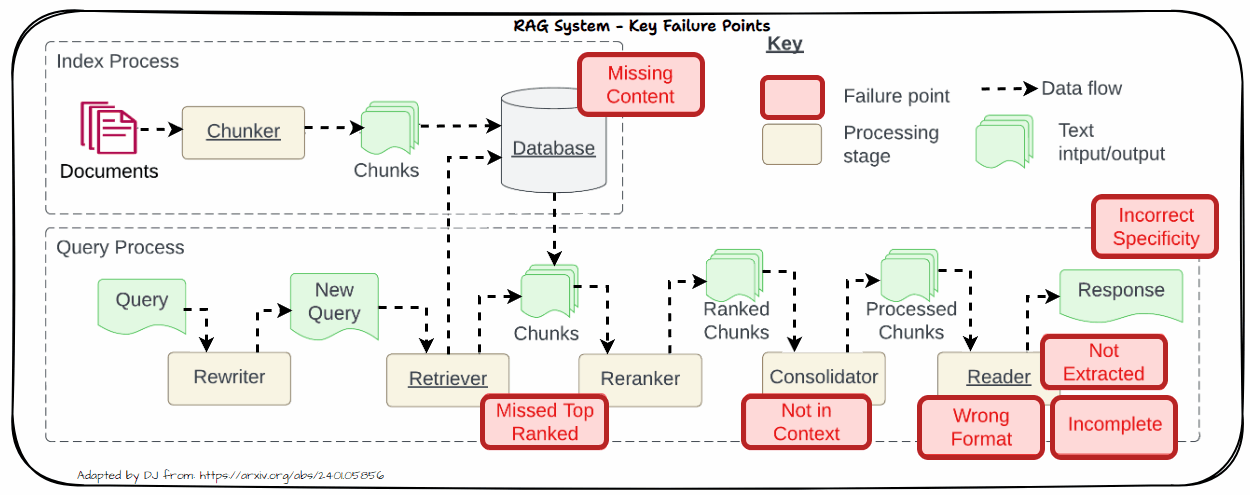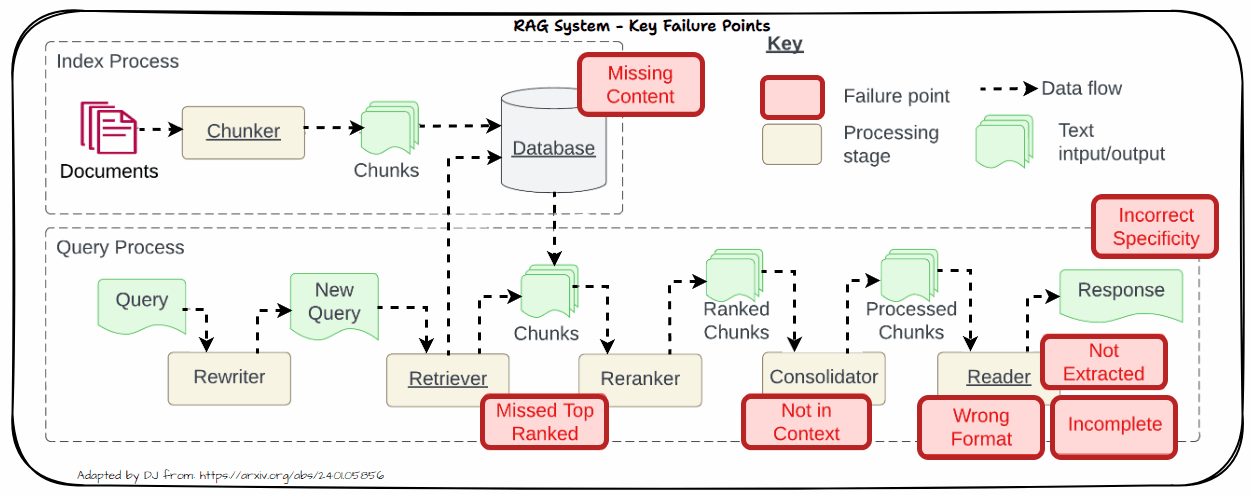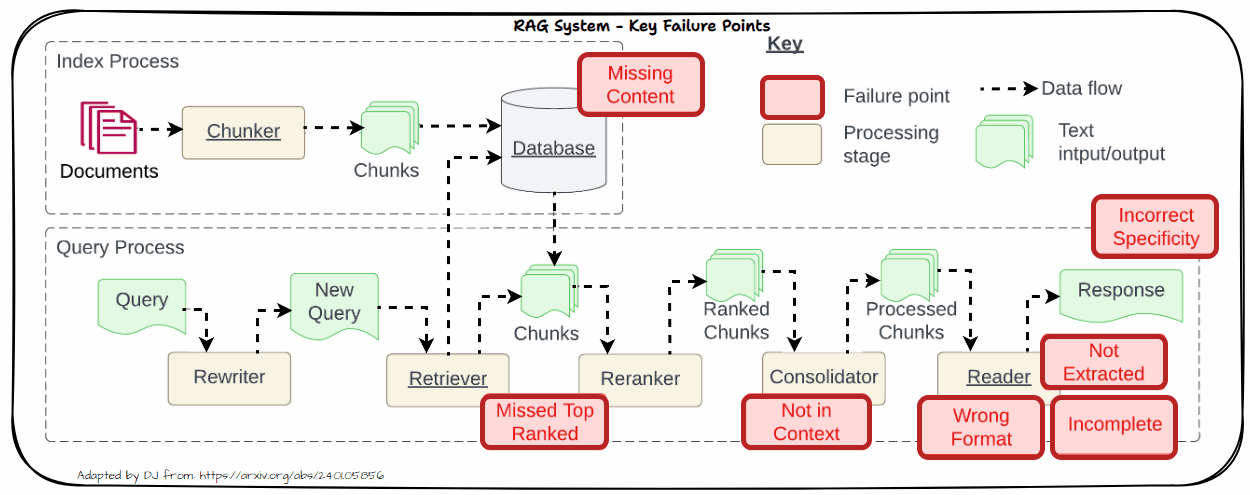
Allow us to now look into the important thing challenges in real-world methods. That is impressed by the well-known paper “Seven Failure Factors When Engineering a Retrieval Augmented Era System” by Barnett et al. as depicted within the following determine. We’ll dive into every of those issues in additional element within the following part with sensible options to sort out these challenges.
Lacking Content material
One important problem in RAG methods is coping with lacking content material. This downside arises when the retrieved paperwork don’t include adequate or related data to adequately deal with the consumer’s question. When related data is absent from the retrieved paperwork, it may possibly result in a number of points like Affect on Accuracy and Relevance.
The absence of essential content material can severely impression the accuracy and relevance of the language mannequin’s response. With out the mandatory data, the mannequin might generate solutions which can be incomplete, incorrect, or lack depth. This not solely impacts the standard of the responses but additionally diminishes the general reliability of the RAG system.
Options for Lacking Content material
These are the approaches we are able to take to sort out challenges with lacking content material.
Commonly updating and sustaining the data base ensures that it comprises correct and complete data. This may cut back the probability of lacking content material by offering the retrieval part with a richer set of paperwork.
Crafting particular and assertive prompts with clear constraints can information the language mannequin to generate extra exact and related responses. This helps in narrowing down the main focus and enhancing the response’s accuracy.
Implementing RAG methods with agentic capabilities permits the system to actively search and incorporate exterior sources of knowledge. This strategy helps deal with lacking content material by increasing the vary of sources and enhancing the relevance of the retrieved information.
You’ll be able to try this pocket book for extra particulars with hands-on examples!
Missed High Ranked
When paperwork that must be top-ranked fail to seem within the retrieval outcomes, the system struggles to offer correct responses. This downside, referred to as “Missed High Ranked,” happens when vital context paperwork should not prioritized within the retrieval course of. In consequence, the mannequin might not have entry to essential data wanted to reply the query successfully.
Regardless of the presence of related paperwork, poor retrieval methods can forestall these paperwork from being retrieved. Consequently, the mannequin might generate responses which can be incomplete or inaccurate because of the lack of important context. Addressing this concern includes enhancing the retrieval technique to make sure that probably the most related paperwork are recognized and included within the context.
Not in Context
The “Not in Context” concern arises when paperwork containing the reply are current through the preliminary retrieval however don’t make it into the ultimate context used for producing a response. This downside typically outcomes from ineffective retrieval, reranking, or consolidation methods. Regardless of the presence of related paperwork, flaws in these processes can forestall the paperwork from being included within the last context.
Consequently, the mannequin might lack the mandatory data to generate a exact and correct reply. Enhancing retrieval algorithms, reranking strategies, and consolidation methods is important to make sure that all pertinent paperwork are correctly built-in into the context, thereby enhancing the standard of the generated responses.
The “Not Extracted” concern happens when the LLM struggles to extract the right reply from the offered context, despite the fact that the reply is current. This downside arises when the context comprises an excessive amount of pointless data, noise, or contradictory particulars. The abundance of irrelevant or conflicting data can overwhelm the mannequin, making it tough to pinpoint the correct reply.
To handle this concern, it’s essential to enhance context administration by lowering noise and guaranteeing that the knowledge offered is related and constant. This may assist the LLM concentrate on extracting exact solutions from the context.
Incorrect Specificity
When the output response is simply too obscure and lacks element or specificity, it typically outcomes from obscure or generic queries that fail to retrieve the correct context. Moreover, points with chunking or poor retrieval methods can exacerbate this downside. Obscure queries won’t present sufficient course for the retrieval system to fetch probably the most related paperwork, whereas improper chunking can dilute the context, making it difficult for the LLM to generate an in depth response. To handle this, refine queries to be extra particular and enhance chunking and retrieval strategies to make sure that the context offered is each related and complete.
Options for Missed High Ranked, Not in Context, Not Extracted and Incorrect Specificity
Use Higher Chunking Methods
Hyperparameter Tuning – Chunking & Retrieval
Use Higher Embedder Fashions
Use Superior Retrieval Methods
Use Context Compression Methods
Use Higher Reranker Fashions
You’ll be able to try this pocket book for extra particulars with hands-on examples!
Experiment with varied Chunking Methods
You’ll be able to discover and experiment with varied chunking methods within the given desk:
Hyperparameter Tuning – Chunking & Retrieval
Hyperparameter tuning performs a important function in optimizing RAG methods for higher efficiency. Two key areas the place hyperparameter tuning could make a big impression are chunking and retrieval.
Chunking
Within the context of RAG methods, chunking refers back to the technique of dividing giant paperwork into smaller, extra manageable segments. This enables the retriever to concentrate on extra related sections of the doc, enhancing the standard of the retrieved context. Nevertheless, figuring out the optimum chunk dimension is a fragile steadiness—chunks which can be too small would possibly miss vital context, whereas chunks which can be too giant would possibly dilute relevance. Hyperparameter tuning helps to find the correct chunk dimension that maximizes retrieval accuracy with out overwhelming the LLM.
Retrieval
The retrieval part includes a number of hyperparameters that may affect the effectiveness of the retrieval course of. As an example, you may fine-tune the variety of retrieved paperwork, the brink for relevance scoring, and the embedding mannequin used to enhance the standard of the context offered to the LLM. Hyperparameter tuning in retrieval ensures that the system is persistently fetching probably the most related paperwork, thus enhancing the general efficiency of the RAG system.
Higher Embedder Fashions
Embedder fashions assist in changing your textual content into vectors that are utilizing throughout retrieval and search. Don’t ignore embedder fashions as utilizing the improper one can value your RAG System’s efficiency dearly.
Newer Embedder Fashions shall be educated on extra information and sometimes higher. Don’t simply go by benchmarks, use and experiment in your information. Don’t use business fashions if information privateness is vital. There are a number of embedder fashions accessible, do try the Large Textual content Embedding Benchmark (MTEB) leaderboard to get an thought of the possibly good and present embedder fashions on the market.
Higher Reranker Fashions
Rerankers are fine-tuned cross-encoder transformer fashions. These fashions absorb a pair of paperwork (Question, Doc) and return again a relevance rating.
Fashions fine-tuned on extra pairs and launched just lately will often be higher so do try for the most recent reranker fashions and experiment with them.
Superior Retrieval Methods
To handle the restrictions and ache factors in conventional RAG methods, researchers and builders are more and more implementing superior retrieval methods. These methods purpose to boost the accuracy and relevance of the retrieved paperwork, thereby enhancing the general system efficiency.
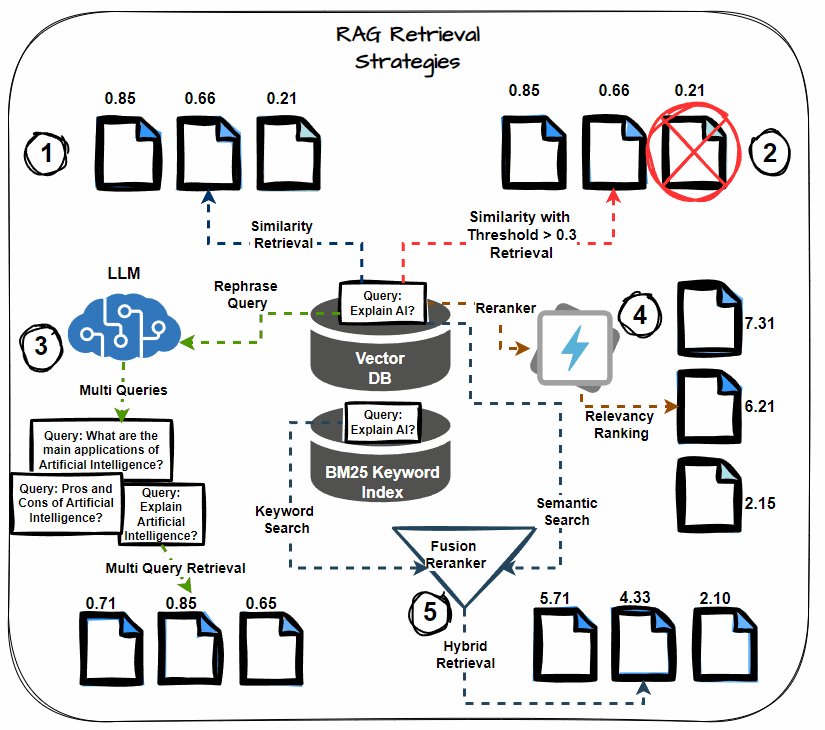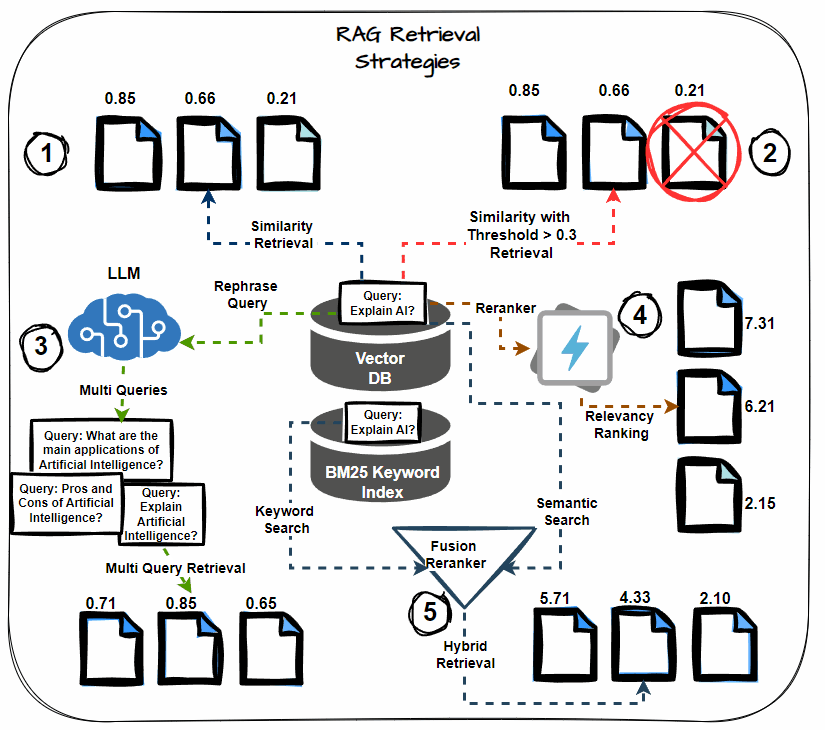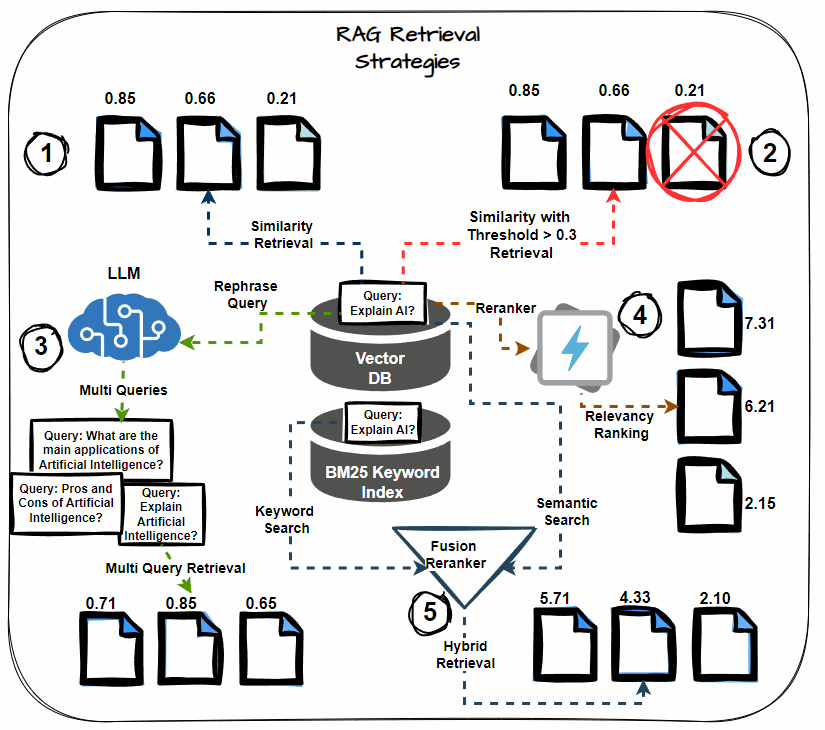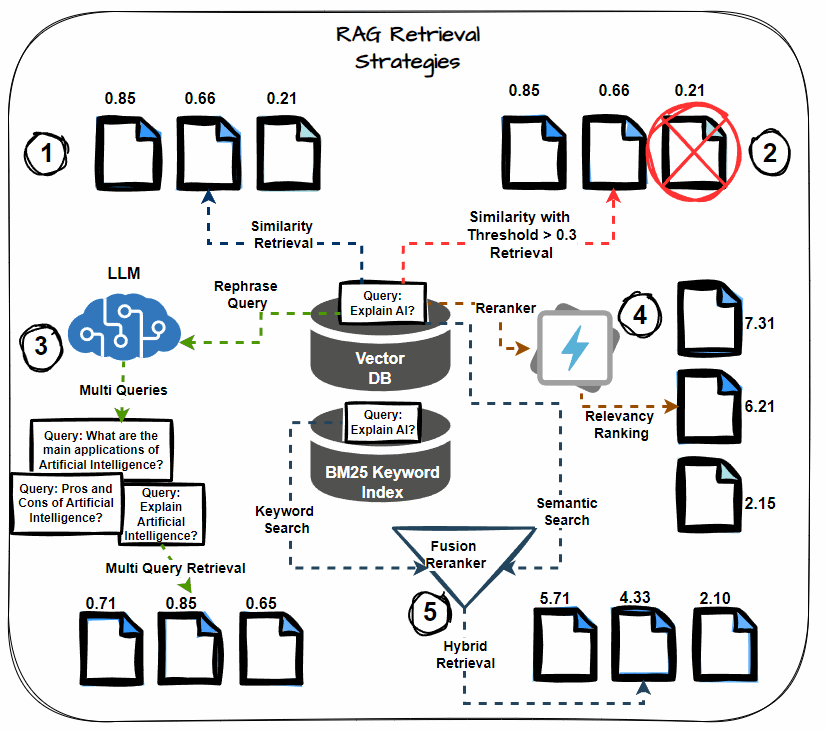
Semantic Similarity Thresholding
This system includes setting a threshold for the semantic similarity rating through the retrieval course of. Think about solely paperwork that exceed this threshold as related, together with them within the context for LLM processing. Prioritize probably the most semantically related paperwork, lowering noise within the retrieved context.
Multi-query Retrieval
As a substitute of counting on a single question to retrieve paperwork, multi-query retrieval generates a number of variations of the question. Every variation targets completely different elements of the knowledge want, thereby rising the probability of retrieving all related paperwork. This technique helps mitigate the danger of lacking important data.
Hybrid Search (Key phrase + Semantic)
A hybrid search strategy combines keyword-based retrieval with semantic search. Key phrase-based search retrieves paperwork containing particular phrases, whereas semantic search captures paperwork contextually associated to the question. This twin strategy maximizes the probabilities of retrieving all related data.
Reranking
After retrieving the preliminary set of paperwork, apply reranking methods to reorder them primarily based on their relevance to the question. Use extra refined fashions or further options to refine the order, guaranteeing that probably the most related paperwork obtain larger precedence.
Chained Retrieval
Chained retrieval breaks down the retrieval course of into a number of levels, with every stage additional refining the outcomes. The preliminary retrieval fetches a broad set of paperwork. Then, subsequent levels refine these paperwork primarily based on further standards, comparable to relevance or specificity. This technique permits for extra focused and correct doc retrieval.
Context Compression Strategies
Context compression is a vital method for refining RAG methods. It ensures that probably the most related data is prioritized, resulting in correct and concise responses. On this part, we’ll discover two major strategies of context compression: prompt-based compression and filtering. We may also look at their impression on enhancing the efficiency of real-world RAG methods.
Immediate-Based mostly Compression
Immediate-based compression includes utilizing language fashions to establish and summarize probably the most related components of retrieved paperwork. This system goals to distill the important data and current it in a concise format that’s most helpful for producing a response. Advantages of this strategy embody:
Improved Relevance: By specializing in probably the most pertinent data, prompt-based compression enhances the relevance of the generated response.
Limitations: Nevertheless, this technique can also have limitations, comparable to the danger of oversimplifying complicated data or dropping vital nuances throughout summarization.
Filtering
Filtering includes eradicating whole paperwork from the context primarily based on their relevance scores or different standards. This system helps handle the quantity of knowledge and be certain that solely probably the most related paperwork are thought-about. Potential trade-offs embody:
Decreased Context Quantity: Filtering can result in a discount within the quantity of context accessible, which could have an effect on the mannequin’s means to generate detailed responses.
Elevated Focus: However, filtering helps preserve concentrate on probably the most related data, enhancing the general high quality and relevance of the response.
Fallacious Format
The “Fallacious Format” downside happens when an LLM fails to return a response within the specified format, comparable to JSON. This concern arises when the mannequin deviates from the required construction, producing output that’s improperly formatted or unusable. As an example, if you happen to anticipate a JSON format however the LLM offers plain textual content or one other format, it disrupts downstream processing and integration. This downside highlights the necessity for cautious instruction and validation to make sure that the LLM’s output meets the required formatting necessities.
Options for Fallacious Format
Highly effective LLMs have native help for response codecs e.g OpenAI helps JSON outputs.
Higher Prompting and Output Parsers
Structured Output Frameworks
You’ll be able to try this pocket book for extra particulars with hands-on examples!
For instance fashions like GPT-4o have native output parsing help like JSON which you’ll allow as proven within the following code snapshot.
Incomplete
The “Incomplete” downside arises when the generated response lacks important data, making it incomplete. This concern typically outcomes from poorly worded questions that don’t clearly convey the required data, insufficient context retrieved for the response, or ineffective reasoning by the mannequin.
Incomplete responses can stem from quite a lot of sources, together with ambiguous queries that fail to specify the mandatory particulars, retrieval mechanisms that don’t fetch complete data, or reasoning processes that miss key components. Addressing this downside includes refining query formulation, enhancing context retrieval methods, and enhancing the mannequin’s reasoning capabilities to make sure that responses are each full and informative.
Answer for Incomplete
Use Higher LLMs like GPT-4o, Claude 3.5 or Gemini 1.5
Use Superior Prompting Strategies like Chain-of-Thought, Self-Consistency
Construct Agentic Techniques with Software Use if essential
Rewrite Consumer Question and Enhance Retrieval – HyDE
HyDE is an fascinating strategy the place the concept is to generate a Hypothetical reply to the given query which is probably not factually completely appropriate however would have related textual content components which may help retrieve the extra related paperwork from the vector database as in comparison with retrieving utilizing simply the query as depicted within the following workflow.
Different Enhancements from Latest Analysis Papers
Allow us to now look onto few enhancements from latest analysis papers which have really labored.
RAG vs. Lengthy Context LLMs
Lengthy-context LLMs typically ship superior efficiency in comparison with Retrieval-Augmented Era (RAG) methods attributable to their means to deal with actually lengthy paperwork and generate detailed responses with out worrying about all the information pre-processing wanted for RAG methods. Nevertheless, they arrive with excessive computing and value calls for, making them much less sensible for some purposes. A hybrid strategy presents an answer by leveraging the strengths of each fashions. On this technique, you first use a RAG system to offer a response primarily based on the retrieved context. Then, you may make use of a long-context LLM to evaluation and refine the RAG-generated reply if wanted. This technique means that you can steadiness effectivity and value whereas guaranteeing high-quality, detailed responses when essential as talked about within the paper, Retrieval Augmented Era or Lengthy-Context LLMs? A Complete Examine and Hybrid Strategy, Zhuowan Li et al.
RAG vs Lengthy Context LLMs – Self-Router RAG
Let’s have a look at a sensible workflow of how one can implement the answer proposed within the above paper. In a typical RAG circulation, the method begins with retrieving context paperwork from a vector database primarily based on a consumer question. The RAG system then makes use of these paperwork to generate a solution whereas adhering to the offered data. If the answerability of the question is unsure, an LLM decide immediate determines if the question is answerable or unanswerable primarily based on the context. For circumstances the place the question can’t be answered satisfactorily with the retrieved context, the system employs a long-context LLM. This LLM makes use of the whole context paperwork to offer an in depth response, guaranteeing that the reply relies solely on the offered data.
Agentic Corrective RAG
Agentic Corrective RAG attracts inspiration from the paper, Corrective Retrieval Augmented Era, Shi-Qi Yan et al. the place the concept is to first do a traditional retrieval from a vector database in your context paperwork primarily based on a consumer question. Then as a substitute of the usual RAG circulation, we assess how related are the retrieved paperwork to reply the consumer question utilizing an LLM-as-Decide circulation and if there are some irrelevant paperwork or no related paperwork, we do an online search to get dwell data from the online for the consumer question earlier than following the traditional RAG circulation as depicted within the following determine.
First, retrieve context paperwork from the vector database primarily based on the enter question. Then, use an LLM to evaluate the relevance of those paperwork to the query. If all paperwork are related, proceed with out additional motion. If some paperwork are ambiguous or incorrect, rephrase the question and search the online for higher context. Lastly, ship the rephrased question together with the up to date context to the LLM for producing the response. That is proven intimately within the following sensible workflow illustration.
Agentic Self-Reflection RAG
Agentic Self-Reflection RAG (SELF-RAG) introduces a novel strategy that enhances giant language fashions (LLMs) by integrating retrieval with self-reflection. This framework permits LLMs to dynamically retrieve related passages and mirror on their very own responses utilizing particular reflection tokens, enhancing accuracy and adaptableness. Experiments exhibit that SELF-RAG surpasses conventional fashions like ChatGPT and Llama2-chat in duties comparable to open-domain QA and reality verification, considerably boosting factuality and quotation precision. This was proposed within the paper Self-RAG: Studying to Retrieve, Generate, and Critique via Self-Reflection, Akari Asai et al.
A sensible implementation of this workflow is depicted within the following illustration the place we do a traditional RAG retrieval, then use an LLM-as-Decide grader to evaluate doc related, do net searches or question rewriting and retrieval if wanted to get extra related context paperwork. The following step includes producing the response and once more utilizing LLM-as-Decide to mirror on the generated reply and ensure it solutions the query and isn’t having any hallucinations.
Conclusion
Enhancing real-world RAG methods requires addressing a number of key challenges, together with lacking content material, retrieval issues, and response era points. Implementing sensible options, comparable to enriching the data base and using superior retrieval methods, can considerably improve the efficiency of RAG methods. Moreover, refining context compression strategies additional contributes to enhancing system effectiveness. Steady enchancment and adaptation are essential as these methods evolve to fulfill the rising calls for of assorted purposes. Key takeaways from the discuss may be summarized within the following determine.
Future analysis and improvement efforts ought to concentrate on enhancing retrieval methods, discover the above talked about methodologies. Moreover, exploring new approaches like Agentic AI may help optimize RAG methods for even higher effectivity and accuracy.
Q1. What are Retrieval-Augmented Era (RAG) methods?
A. RAG methods mix retrieval mechanisms with giant language fashions to generate responses primarily based on exterior information.
Q2. What’s the principal good thing about utilizing RAG methods?
A. They permit fashions to dynamically incorporate up-to-date data from exterior sources with out frequent retraining.
Q3. What are frequent challenges in RAG methods?
A. Widespread challenges embody lacking content material, retrieval issues, response specificity, context overload, and system latency.
This autumn. How can lacking content material points be addressed in RAG methods?
A. Options embody higher information cleansing, assertive prompting, and leveraging agentic RAG methods for dwell data.
Q5. What are some superior retrieval methods for RAG methods?
A. Methods embody semantic similarity thresholding, multi-query retrieval, hybrid search, reranking, and chained retrieval.
My title is Ayushi Trivedi. I’m a B. Tech graduate. I’ve 3 years of expertise working as an educator and content material editor. I’ve labored with varied python libraries, like numpy, pandas, seaborn, matplotlib, scikit, imblearn, linear regression and lots of extra. I’m additionally an writer. My first e book named #turning25 has been printed and is accessible on amazon and flipkart. Right here, I’m technical content material editor at Analytics Vidhya. I really feel proud and blissful to be AVian. I’ve an awesome group to work with. I like constructing the bridge between the know-how and the learner.
Blasphemous and Blasphemous II are Metroidvania action-adventure video games developed by the Spanish studio, The Recreation Kitchen. The video games have a shocking, distinctive pixel artwork model and atmospheric world which is impressed by Spanish folklore and spiritual themes. They’re identified for his or her difficult fight and complicated degree design.
David Erosa is the Lead Producer and Dani Márquez is a Senior Programmer on Blasphemous II. David and Dani be part of the present at the moment to speak about designing the sport methods, the sport’s growth framework, engineering character motion, console optimizations, and far more.
Joe Nash is a developer, educator, and award-winning group builder, who has labored at firms together with GitHub, Twilio, Unity, and PayPal. Joe bought his begin in software program growth by creating mods and operating servers for Garry’s Mod, and sport growth stays his favourite method to expertise and discover new applied sciences and ideas.
Sponsors
As a listener of Software program Engineering Every day you perceive the impression of generative AI. On the podcast, we’ve lined many thrilling points of GenAI applied sciences, in addition to the brand new vulnerabilities and dangers they convey.
HackerOne’s AI pink teaming addresses the novel challenges of AI security and safety for companies launching new AI deployments. Their method includes stress-testing AI fashions and deployments to verify they’ll’t be tricked into offering info past their supposed use, and that safety flaws can’t be exploited to entry confidential knowledge or methods. Throughout the HackerOne group, over 750 energetic hackers concentrate on immediate hacking and different AI safety and security testing.
In a single current engagement, a staff of 18 HackerOne hackers shortly recognized 26 legitimate findings throughout the preliminary 24 hours and collected over 100 legitimate findings within the two-week engagement. HackerOne presents strategic flexibility, speedy deployment, and a hybrid expertise technique. Be taught extra at Hackerone.com/ai.
GitBook combines highly effective docs with AI-powered search and insights to provide technical groups a single supply of reality for his or her information. Effortlessly create, floor and enhance public and inner documentation that your customers and groups will love.
WorkOS is a contemporary id platform constructed for B2B SaaS. It offers seamless APIs for authentication, person id, and complicated enterprise options like SSO and SCIM provisioning. It’s a drop-in substitute for Auth0 (auth-zero) and helps as much as 1 million month-to-month energetic customers at no cost.
It’s good for B2B SaaS firms annoyed with excessive prices, opaque pricing, and lack of enterprise capabilities supported by legacy auth distributors. The APIs are versatile and simple to make use of, designed to supply an easy expertise out of your first person all the way in which to your largest enterprise buyer.
Right now, tons of of high-growth scale-ups are already powered by WorkOS, together with ones you most likely know, like Vercel, Webflow, and Loom. Try workos.com/SED to be taught extra.
Researchers on the College of Washington developed small robotic units that may change how they transfer by the air by “snapping” right into a folded place throughout their descent. Proven here’s a timelapse picture of the “microflier” falling in its unfolded state, which makes it tumble chaotically and unfold outward within the wind. Photograph by Mark Stone/College of Washington
By Roger Van Scyoc
On a cool afternoon on the coronary heart of the College of Washington’s campus, autumn, for just a few fleeting moments, seems to have arrived early. Tiny golden squares resembling leaves flutter then fall, switching from a frenzied tumble to a sleek descent with a snap.
Aptly named “microfliers” and impressed by Miura-fold origami, these small robotic units can fold closed throughout their descent after being dropped from a drone. This “snapping” motion modifications the best way they disperse and will, sooner or later, assist change the best way scientists examine agriculture, meteorology, local weather change and extra.
“In nature, you see leaves and seeds disperse in only one method,” mentioned Kyle Johnson, an Allen College Ph.D. pupil and a primary co-author of the paper on the topic revealed in Science Robotics. “What we had been in a position to obtain was a construction that may really act in two other ways.”
When open flat, the units tumble chaotically, mimicking the descent of an elm leaf. When folded closed, they drop in a extra steady method, mirroring how a maple leaf falls from a department. By way of plenty of strategies — onboard strain sensor, timer or a Bluetooth sign — the researchers can management when the units transition from open to closed, and in doing so, manipulate how far they disperse by the air.
How may they obtain this? By studying between the strains.
“The Miura-ori origami fold, impressed by geometric patterns present in leaves, allows the creation of buildings that may ‘snap’ between a flat and extra folded state,” mentioned co-senior creator Vikram Iyer, an Allen College professor and co-director of the Computing for the Setting (CS4Env) initiative. “As a result of it solely takes vitality to change between the states, we started exploring this as an vitality environment friendly option to change floor space in mid-air, with the instinct that opening or closing a parachute will change how briskly an object falls.”
That vitality effectivity is vital to having the ability to function with out batteries and scale down the fliers’ dimension and weight. Fitted with a battery-free actuator and a photo voltaic power-harvesting circuit, microfliers boast energy-saving options not seen in bigger and heavier battery-powered counterparts reminiscent of drones. But they’re strong sufficient to hold sensors for plenty of metrics, together with temperature, strain, humidity and altitude. Past measuring atmospheric circumstances, the researchers say a community of those units may assist paint an image of crop development on farmland or detect fuel leaks close to inhabitants facilities.
“This strategy opens up a brand new design house for microfliers by utilizing origami,” mentioned Shyam Gollakota, the Thomas J. Cable Endowed Professor within the Allen College and director of the varsity’s Cell Intelligence Lab who was additionally a co-senior creator. “We hope this work is step one in direction of a future imaginative and prescient for creating a brand new class of fliers and flight modalities.”
Weighing lower than half a gram, microfliers require much less materials and price lower than drones. Additionally they supply the flexibility to go the place it’s too harmful for a human to set foot.
As an illustration, Johnson mentioned, microfliers could possibly be deployed when monitoring forest fires. Presently, firefighting groups generally rappel right down to the place a hearth is spreading. Microfliers may help in mapping the place a hearth could also be heading and the place finest to drop a payload of water. Moreover, the crew is engaged on making extra elements of the system biodegradable within the case that they’ll’t be recovered after being launched.
“There’s a superb quantity of labor towards making these circuits extra sustainable,” mentioned Vicente Arroyos, one other Allen College Ph.D. pupil and first co-author on the paper. “We will leverage our work on biodegradable supplies to make these extra sustainable.”
Apart from bettering sustainability, the researchers additionally tackled challenges regarding the construction of the system itself. Early prototypes lacked the carbon fiber roots that present the rigidity wanted to stop unintended transitions between states.
The analysis crew took inspiration from elm and maple leaves in designing the microfliers. When open flat, the units tumble chaotically, just like how an elm leaf falls from a department. When they’re “snapped” right into a folded place, as proven right here, they descend in a extra steady, straight downward method like a maple leaf. Photograph by Mark Stone/College of Washington
Gathering maple and elm leaves from exterior their lab, the researchers seen that whereas their origami buildings exhibited the bistability required to vary between states, they flexed too simply and didn’t have the venation seen within the discovered foliage. To realize extra fine-grained management, they took one other cue from the setting.
“We seemed once more to nature to make the faces of the origami flat and inflexible, including a vein-like sample to the construction utilizing carbon fiber,” Johnson mentioned. “After that modification, we not noticed numerous the vitality that we enter dissipate over the origami’s faces.”
In whole, the researchers estimate that the event of their design took about two years. There’s nonetheless room to develop, they added, noting that the present microfliers can solely transition from open to closed. They mentioned newer designs, by providing the flexibility to change backwards and forwards between states, might supply extra precision and adaptability in the place and the way they’re used.
Throughout testing, when dropped from an altitude of 40 meters, as an illustration, the microfliers may disperse as much as distances of 98 meters in a light-weight breeze. Additional refinements may improve the world of protection, permitting them to observe extra exact trajectories by accounting for variables reminiscent of wind and inclement circumstances.
Associated to their earlier work with dandelion-inspired sensors, the origami microfliers construct upon the researchers’ bigger purpose of making the web of bio-inspired issues. Whereas the dandelion-inspired units featured passive flight, reflecting the style by which dandelion seeds disperse by the wind, the origami microfliers operate as full robotic techniques that embody actuation to vary their form, energetic and bi-directional wi-fi transmission through an onboard radio, and onboard computing and sensing to autonomously set off form modifications upon reaching a goal altitude.
“This design also can accommodate extra sensors and payload on account of its dimension and energy harvesting capabilities,” Arroyos mentioned. “It’s thrilling to consider the untapped potential for these units.”
The longer term, in different phrases, is rapidly taking form.
“Origami is impressed by nature,” Johnson added, smiling. “These patterns are throughout us. We simply need to look in the suitable place.”
The mission was an interdisciplinary work by an all-UW crew. The paper’s co-authors additionally included Amélie Ferran, a Ph.D. pupil within the mechanical engineering division, in addition to Raul Villanueva, Dennis Yin and Tilboon Elberier, who contributed as undergraduate college students finding out electrical and laptop engineering, and mechanical engineering professors Alberto Aliseda and Sawyer Fuller.
Beneath is my code for fetching the mails from IMAPSession. I’m calling the under technique with startingAt=0 and I need to fetch mails in batches of 25, however when i get error(errror.code == 3) then I need to fetch 1 by 1.
Right here is the working When this perform is named we attempt to fetch a batch of 25, nevertheless it fails as a result of it will get error. So then it enter the if block and the subsequent worth is ready to fetching mails to 1 by 1 by recurively calling the identical perform. When it’s known as recursively then it set the batch to 1 mail after which the recursive name will get ended and batch once more turns into 25 after which once more enter the getMessageHeadersForUids with batch of 25.
- (void)fetchMessageHeadersForUids:(NSArray*)uids inFolder:(NSString*)folder startingAt:(NSUInteger)begin {
@strive {
NSUInteger initialBatchSize = INITIAL_MESSAGE_BATCH_SIZE; //InitialBatchSize = 25
// international var errorBatchSize = 25 (Initialized above)
if (begin >= initialBatchSize) {
begin = begin + initialBatchSize;
}
__block NSUInteger newStart = begin;
NSLog(@"MessageData Preliminary begin==> %ld", begin);
NSLog(@"MessageData Preliminary newSstart==> %ld", newStart);
NSLog(@"MessageData Preliminary errorBatchSize==> %ld", errorBatchSize);
NSLog(@"MessageData Preliminary errorBatchSize==> %@", folder);
NSUInteger batchSize = newStart + errorBatchSize > [uids count] ? [uids count] - begin : errorBatchSize;
NSArray* batch = [uids subarrayWithRange:NSMakeRange(newStart,batchSize)];
NSLog(@"MessageData Initial2 begin ==> %ld", begin);
NSLog(@"MessageData Initial2 newstart ==> %ld", newStart);
NSLog(@"MessageData Initial2 batchSize ==> %ld", batchSize);
NSLog(@"MessageData Initial2 batch ==> %@", batch);
if (batchSize > 0) {
double progress = (double) begin / (double) [uids count];
bool cancelOperation = NO;
REPORT_REFRESH_PROGRESS(RefreshStateFetchMessageHeaders, @(progress), &cancelOperation);
if (cancelOperation) {
COMPLETE_REFRESH_CANCEL;
COMPLETE_REFRESH_SUCCESS;
}
[[self imap] getMessageHeadersForUids:batch inFolder:folder completion:^(NSError* error, NSArray* messages, MCOIndexSet* vanishedMessages) {
NSLog(@"MessageData BatchSize after perform execution ==> %@", batch);
NSLog(@"Fetching just one folder %@" , folder);
if (error.code == 3){
NSLog(@"MessageData Error fetching knowledge once more from the server %@", error);
NSLog(@"MessageData Error earlier than begin==> %ld", begin);
NSLog(@"MessageData Error earlier than errorBatchSize==> %ld", begin);
NSUInteger subsequent = 0;
if(errorBatchSize - begin == 0){
subsequent = begin + 1;
NSLog(@"IF block executedd");
NSLog(@"Subsequent and begin worth to be fetched throughout worth change might be %ld %ld" , subsequent, begin);
NSLog(@"MessageData Error in IF block Subsequent And Begin ==> %ld %ld",subsequent, begin);
}else{
errorBatchSize = 1;
subsequent = newStart;
newStart++;
NSLog(@"ELSE block executedd");
NSLog(@"MessageData Error in ELSE block errorBatchSize , Subsequent And Begin ==> %ld %ld %ld",errorBatchSize, subsequent, newStart);
}
@strive {
[self fetchMessageHeadersForUids:uids inFolder:folder startingAt:next];
NSLog(@"Dispatch Ended");
NSLog(@"MessageData BatchSize ========> %@", batch);
}
@catch (NSException *exception) {
NSLog(@"MessageData Catch exception");
NSLog(@"MailMessageManager:fetchMessageHeadersForUids failed with %@", exception.motive);
NSError* exceptionError = MAIL_MANAGER_ERROR(MMErrorGeneric, exception.motive);
COMPLETE_ON_REFRESH_ERROR(exceptionError, RefreshStateFetchMessageHeaders);
}
}
COMPLETE_ON_REFRESH_ERROR(error, RefreshStateFetchMessageHeaders);
@strive {
NSLog(@"MessageData Success earlier than begin==> %ld", begin);
NSLog(@"MessageData Success earlier than errorBatch==> %ld", errorBatchSize);
// pump the messages into the info retailer
MailMessageDataManager* dataManager = [MailMessageDataManager mailMessageDataManager];
[dataManager addMessages:_accountId folderName:folder messages:messages checkIfExist:YES];
// attempt to go for an additional batch
NSUInteger subsequent = newStart + initialBatchSize;
NSLog(@"MessageData Success Subsequent==> %ld", subsequent);
NSLog(@"MessageData Success begin==> %ld", begin);
NSLog(@"MessageData Success neeStart==> %ld", newStart);
NSLog(@"MessageData Success errorBatch==> %ld", errorBatchSize);
[self fetchMessageHeadersForUids:uids inFolder:folder startingAt:next];
}
@catch (NSException* exception) {
NSLog(@"MessageData Catch exception");
NSLog(@"MailMessageManager:fetchMessageHeadersForUids failed with %@", exception.motive);
NSError* exceptionError = MAIL_MANAGER_ERROR(MMErrorGeneric, exception.motive);
COMPLETE_ON_REFRESH_ERROR(exceptionError, RefreshStateFetchMessageHeaders);
}
}];
} else {
// we're all executed. Buh bye
NSLog(@"MessageData executed");
_isFetchInprogress = NO;
bool cancelOperation = NO;
REPORT_REFRESH_PROGRESS(RefreshStateFetchMessageHeadersComplete, @1.0, &cancelOperation);
[[NSNotificationCenter defaultCenter] postNotificationName:@"updateBadgeCount" object:nil];
COMPLETE_REFRESH_SUCCESS;
}
}
@catch (NSException* exception) {
NSLog(@"MessageData final catch ");
NSLog(@"MailMessageManager:fetchMessageHeadersForUids failed with %@", exception.motive);
NSError* exceptionError = MAIL_MANAGER_ERROR(MMErrorGeneric, exception.motive);
COMPLETE_ON_REFRESH_ERROR_DELAYED(exceptionError, RefreshStateFetchMessageHeaders);
}
}
I need that this getMessageHeadersForUids func is ready to 1 whereas we get error.Please somebody look into this