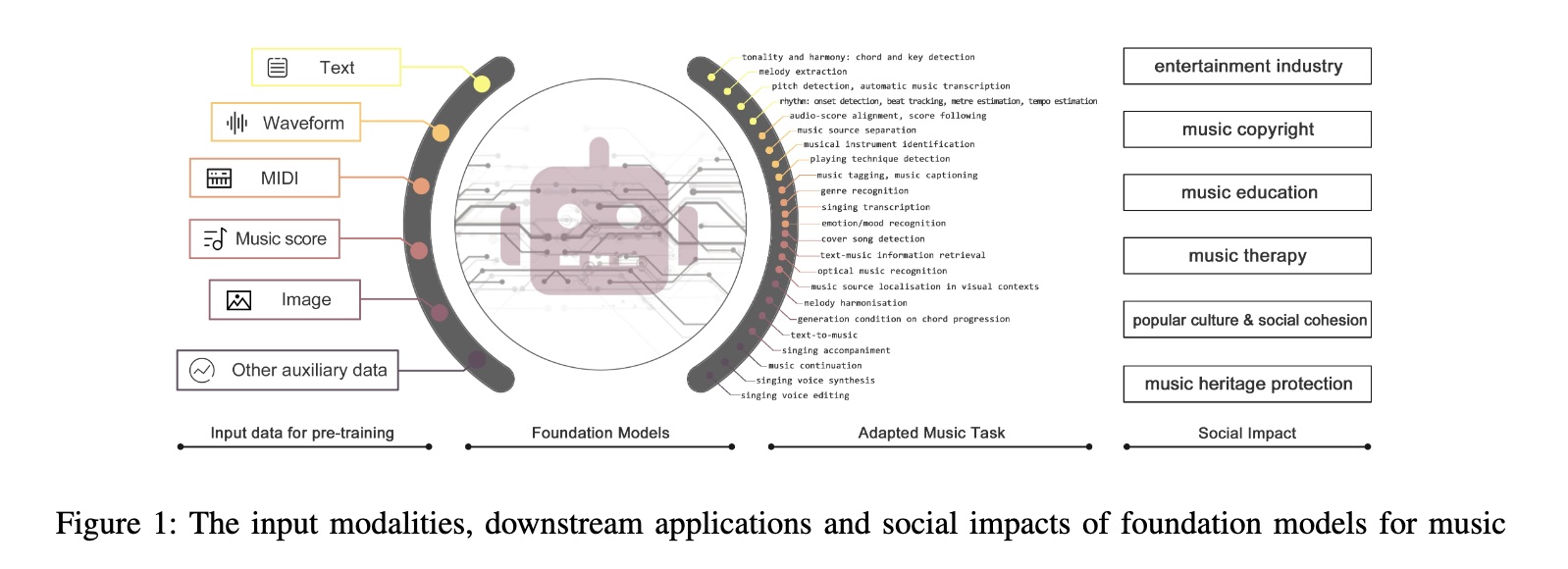
Music info retrieval (MIR) has turn into more and more important because the digitalization of music has exploded. MIR entails the event of algorithms that may analyze and course of music knowledge to acknowledge patterns, classify genres, and even generate new music compositions. This multidisciplinary area blends components of music principle, machine studying, and audio processing, aiming to create instruments that may perceive music in a significant approach to people and machines. The developments in MIR are paving the best way for extra refined music advice techniques, automated music transcription, and modern functions within the music business.
A serious problem dealing with the MIR group is the necessity for standardized benchmarks and analysis protocols. This lack of consistency makes it troublesome for researchers to match completely different fashions’ performances throughout numerous duties. The variety of music itself additional exacerbates the issue—spanning a number of genres, cultures, and types—making it practically unimaginable to create a common analysis system that applies to all forms of music. With no unified framework, progress within the area is gradual, as improvements can’t be reliably measured or in contrast, resulting in a fragmented panorama the place developments in a single space could not translate properly to others.
At the moment, MIR duties are evaluated utilizing quite a lot of datasets and metrics, every tailor-made to particular duties equivalent to music transcription, chord estimation, and melody extraction. Nevertheless, these instruments and benchmarks are sometimes restricted in scope and don’t enable for complete efficiency evaluations throughout completely different duties. For example, chord estimation and melody extraction may use utterly completely different datasets and analysis metrics, making it difficult to gauge a mannequin’s general effectiveness. Additional, the instruments used are usually designed for Western tonal music, leaving a spot in evaluating non-Western or people music traditions. This fragmented method has led to inconsistent outcomes and a scarcity of clear path in MIR analysis, hindering the event of extra common options.
To deal with these points, researchers have launched MARBLE, a novel benchmark that goals to standardize the analysis of music audio representations throughout numerous hierarchical ranges. MARBLE, developed by researchers from Queen Mary College of London and Carnegie Mellon College, seeks to offer a complete framework for assessing music understanding fashions. This benchmark covers a variety of duties, from high-level style classification and emotion recognition to extra detailed duties equivalent to pitch monitoring, beat monitoring, and melody extraction. By categorizing these duties into completely different ranges of complexity, MARBLE permits for a extra structured and constant analysis course of, enabling researchers to match fashions extra successfully and to determine areas that require additional enchancment.
MARBLE’s methodology ensures that fashions are evaluated comprehensively and pretty throughout completely different duties. The benchmark consists of duties that contain high-level descriptions, equivalent to style classification and music tagging, in addition to extra intricate duties like pitch and beat monitoring, melody extraction, and lyrics transcription. Moreover, MARBLE incorporates performance-level duties, equivalent to decoration and approach detection, and acoustic-level duties, together with singer identification and instrument classification. This hierarchical method addresses the range of music duties and promotes consistency in analysis, enabling a extra correct comparability of fashions. The benchmark additionally features a unified protocol that standardizes the enter and output codecs for these duties, additional enhancing the reliability of the evaluations. Furthermore, MARBLE’s complete method considers components like robustness, security, and alignment with human preferences, guaranteeing that the fashions are technically proficient and relevant in real-world eventualities.
The analysis utilizing the MARBLE benchmark highlighted the numerous efficiency of the fashions throughout completely different duties. The outcomes indicated sturdy efficiency in style classification and music tagging duties, the place the fashions confirmed constant accuracy. Nevertheless, the fashions confronted challenges in additional advanced features like pitch monitoring and melody extraction, revealing areas the place additional refinement is required. The outcomes underscored the fashions’ effectiveness in sure points of music understanding whereas figuring out gaps, notably in dealing with numerous and non-Western musical contexts.
In conclusion, the introduction of the MARBLE benchmark represents a major development within the area of music info retrieval. By offering a standardized and complete analysis framework, MARBLE addresses a vital hole within the area, enabling extra constant and dependable comparisons of music understanding fashions. This benchmark not solely highlights the areas the place present fashions excel but in addition identifies the challenges that have to be overcome to advance the state of music info retrieval. The work carried out by the researchers from Queen Mary College of London and Carnegie Mellon College paves the best way for extra strong and universally relevant music evaluation instruments, in the end contributing to the evolution of the music business within the digital age.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
It’s predicted that by 2030, over 1 million cell robots will likely be within the subject. Nonetheless, implementation continues to be advanced and the price of robotic downtime is estimated to vary from $1,000 to $10,000 per minute. With AI and SLAM techniques combating real-world variability, what are the actual challenges in understanding the overall value of possession?
For cell robots to be possible and enhance operational effectivity, prospects want efficiency in real-world environments at an appropriate value. By specializing in decreasing the invoice of supplies (BoM), groups are making trade-off choices on efficiency, whereas concurrently incurring silent prices that aren’t measured or managed.
At RoboBusiness, which takes place Oct. 16-17 in Santa Clara, Calif., Opteran will focus on why Whole Price of Possession (TCO) must be the main focus to assist make the best choices. Jack Pearson, industrial director of Opteran, mentioned BoM is only one necessary half in a life cycle of prices required to develop, arrange, keep and replace an autonomy resolution. But typically it’s the important or solely value issue thought-about in buying choices.
Pearson is giving a chat on Oct. 16 from 2:45 PM to three:30 PM known as “Past BoM: Autonomy Challenges in Cell Robots.” He mentioned that whereas understanding and measuring TCO is hard, doing so creates a path to long-term, scalable income and a extra aggressive product. His speak will clarify why autonomy is on the coronary heart of TCO, what prices are secretly undermining margin and buyer expertise, and how one can measure and clear up these points.
Opteran is a U.Okay.-based firm based in 2019. Opteran just lately commercialized its vision-based method to robotic autonomy by releasing Opteran Thoughts. It mentioned its algorithms don’t require coaching, intensive infrastructure, or connectivity for notion and navigation. Opteran gained a 2024 RBR50 Robotics Innovation Award for this work.
State of the Trade Panel with ABB, DHL, NVIDIA, Teradyne Robotics Ventures
Rodney Brooks, co-founder and chief expertise officer at Sturdy AI, in addition to co-founder of iRobot and Rethink Robotics
Sergey Levine, co-founder of Bodily Intelligence and an affiliate professor at UC Berkeley
Claire Delaunay, chief expertise officer at farm-ng
Torrey Smith, co-founder and CEO of Endiatx
RoboBusiness will likely be co-located with DeviceTalks West, which focuses on the design and improvement of medical gadgets. Hundreds of robotics practitioners from all over the world will convene on the Santa Clara Conference Middle, so register now to make sure your spot!
For details about sponsorship and exhibition alternatives, obtain the prospectus. Questions concerning sponsorship alternatives must be directed to Colleen Sepich at csepich[AT]wtwhmedia.com.
Apple Music and YouTube Music each now help the switch of music playlists.
On the corresponding help web page, each firms shared the method of transferring playlists.
At the moment, the switch is supported throughout these music streaming companies solely.
Apple Music and Google’s YouTube Music have partnered to supply their customers a hassle-free expertise, together with the flexibility to switch saved playlists throughout music streaming platforms.
Beforehand, transferring playlists from one streaming platform to a different wasn’t that handy, because it concerned third-party apps like Soundiiz and Tune My Music. Such apps additionally required a price to switch songs/ playlists with none restrictions. It would quickly change with the newly introduced capability for Apple Music and YouTube Music customers (by way of MacRumors).
Customers who want to switch their playlists from Apple Music to YouTube Music or vice versa can now accomplish that, as each streaming giants have shared the respective step-by-step course of by means of their help pages. Apple account holders can head to their Knowledge and Privateness web page and request to “Switch a duplicate of your information.” Customers can then choose Apple Music playlists to be transferred to YouTube Music.
Likewise, YouTube Music customers shall be capable of switch their playlists by means of the Google Takeout characteristic. They’ll equally observe the onscreen directions to switch playlists from YouTube Music to Apple Music. Whereas the method seems hassle-free, there are some things to bear in mind earlier than transferring.
(Picture credit score: Andrew Myrick / Android Central)
To make playlist switch extra swift, customers will need to have an lively subscription to the aforementioned music streaming platforms. Whereas playlists are transferred rapidly, they will not be deleted as soon as the switch is completed. Additionally, transfers are solely doable between Apple Music and YouTube Music, not even Spotify. Customers would nonetheless should depend on the above-mentioned third-party companies for any music switch.
The newest transferring characteristic would not help different songs within the library besides from the playlists. It’s also depending on track availability throughout each platforms, which means that when a track from a playlist is not accessible on the opposite platform that’s being shared, customers can nonetheless be out of luck.
Whereas it’s an thrilling begin to see transferring music to an extent between Apple Music and YouTube Music, will probably be extra helpful if different main gamers within the music streaming trade additionally collaborate with one another to carry customers a unified expertise and simple switching between streaming platforms.
Get the most recent information from Android Central, your trusted companion on this planet of Android
Everyone knows that an Apple patent doesn’t a product or characteristic make, however that does not imply that we will not take a look at what the corporate has been engaged on and extrapolate what that might sooner or later imply. And within the case of the most recent patent, it implies that a future iPhone case may have Contact ID and help for capacitive buttons constructed proper in.
Amid ongoing rumors that the iPhone 16 lineup will characteristic a capacitive Seize Button, a brand new Apple patent suggests the corporate has plans for a case that may work with such a button. What’s extra, there’s help for basically passing a Contact ID sign via the case and onto the iPhone button beneath it, too.
Such a characteristic has apparent implications, not least the truth that any future Contact ID-powered iPhone would nonetheless be shielded from iPhone droppers all over the place whereas nonetheless offering help for what remains to be among the finest biometric safety techniques we have ever seen.
Getting all touchy-feely
The patent in query, first spied by Patently Apple, pertains to each the iPhone and the iPad.
At present, placing a case on a button that has Contact ID in-built renders it ineffective. An analogous situation can befall capacitive buttons that have to sense a consumer’s contact — and the stress with which it is being touched — which is prone to be a problem for the rumored Seize Button.
The patent understands that circumstances may by accident set off actions and has an answer to that — by constructing new capacitive buttons into the case itself. Such buttons may theoretically additionally help swipes and different gestures for adjusting media playback quantity and extra, too.
It’s, as ever, vital to keep in mind that Apple patents nearly the whole lot its engineers provide you with which suggests there is no such thing as a assure these case concepts will ever see the sunshine of an Apple Retailer. Nevertheless it would not damage to marvel, proper?
iMore provides spot-on recommendation and steerage from our crew of specialists, with many years of Apple gadget expertise to lean on. Study extra with iMore!
Streaming knowledge adoption continues to speed up with over 80% of Fortune 100 corporations already utilizing Apache Kafka to place knowledge to make use of in actual time. Streaming knowledge typically sinks to real-time search and analytics databases which act as a serving layer to be used circumstances together with fraud detection in fintech, real-time statistics in esports, personalization in eCommerce and extra. These use circumstances are latency delicate with even milliseconds of knowledge delays leading to income loss or threat to the enterprise.
In consequence, prospects ask in regards to the end-to-end latency they’ll obtain on Rockset or the time from when knowledge is generated to when it’s made obtainable for queries. As of at present, Rockset releases a benchmark that achieves 70 ms of knowledge latency on 20 MB/s of throughput on streaming knowledge.
Rockset’s capacity to ingest and index knowledge inside 70ms is a large achievement that many giant enterprise prospects have been struggling to achieve for his or her mission-critical functions. With this benchmark, Rockset provides confidence to enterprises constructing next-generation functions on real-time streaming knowledge from Apache Kafka, Confluent Cloud, Amazon Kinesis and extra.
A number of current product enhancements led Rockset to attain millisecond-latency streaming ingestion:
Compute-compute separation: Rockset separates streaming ingest compute, question compute and storage for effectivity within the cloud. The brand new structure additionally reduces the CPU overhead of writes by eliminating duplicative ingestion duties.
RocksDB: Rockset is constructed on RocksDB, a high-performance embedded storage engine. Rockset lately upgraded to RocksDB 7.8.0+ which presents a number of enhancements that decrease write amplification.
Information Parsing: Rockset has schemaless ingest and helps open knowledge codecs and deeply nested knowledge in JSON, Parquet, Avro codecs and extra. To run complicated analytics over this knowledge, Rockset converts the info at ingest time into a normal proprietary format utilizing environment friendly, custom-built knowledge parsers.
On this weblog, we describe the testing configuration, outcomes and efficiency enhancements that led to Rockset attaining 70 ms knowledge latency on 20 MB/s of throughput.
Efficiency Benchmarking for Actual-Time Search and Analytics
There are two defining traits of real-time search and analytics databases: knowledge latency and question latency.
Information latency measures the time from when knowledge is generated to when it’s queryable within the database. For real-time eventualities, each millisecond issues as it may possibly make the distinction between catching fraudsters of their tracks, protecting avid gamers engaged with adaptive gameplay and surfacing personalised merchandise based mostly on on-line exercise and extra.
Question latency measures the time to execute a question and return a outcome. Purposes need to decrease question latency to create snappy, responsive experiences that preserve customers engaged. Rockset has benchmarked question latency on the Star Schema Benchmark, an industry-standard benchmark for analytical functions, and was capable of beat each ClickHouse and Druid, delivering question latencies as little as 17 ms.
On this weblog, we benchmarked knowledge latency at completely different ingestion charges utilizing Rockbench. Information latency has more and more develop into a manufacturing requirement as an increasing number of enterprises construct functions on real-time streaming knowledge. We’ve discovered from buyer conversations that many different knowledge methods wrestle below the load of excessive throughput and can’t obtain predictable, performant knowledge ingestion for his or her functions. The difficulty is a scarcity of (a) purpose-built methods for streaming ingest (b) methods that may scale ingestion to have the ability to course of knowledge whilst throughput from occasion streams will increase quickly.
The purpose of this benchmark is to showcase that it’s potential to construct low-latency search and analytical functions on streaming knowledge.
Utilizing RockBench for Measuring Throughput and Latency
We evaluated Rockset’s streaming ingest efficiency utilizing RockBench, a benchmark which measures the throughput and end-to-end latency of databases.
RockBench has two elements: a knowledge generator and a metrics evaluator. The info generator writes occasions to the database each second; the metrics evaluator measures the throughput and end-to-end latency.
RockBench Information Generator
The info generator creates 1.25KB paperwork with every doc representing a single occasion. This interprets to eight,000 writes being the equal of 10 MB/s.
To reflect semi-structured occasions in real looking eventualities, every doc has 60 fields with nested objects and arrays. The doc additionally comprises a number of fields which might be used to calculate the end-to-end latency:
_id: The distinctive identifier of the doc
_event_time: Displays the clock time of the generator machine
generator_identifier: 64-bit random quantity
The _event_time of every doc is then subtracted from the present time of the machine to reach on the knowledge latency for every doc. This measurement additionally consists of round-trip latency—the time required to run the question and get outcomes from the database. This metric is revealed to a Prometheus server and the p50, p95 and p99 latencies are calculated throughout all evaluators.
On this efficiency analysis, the info generator inserts new paperwork to the database and doesn’t replace any present paperwork.
Rockset Configuration and Outcomes
All databases make tradeoffs between throughput and latency when ingesting streaming knowledge with greater throughput incurring latency penalties and vice versa.
We lately benchmarked Rockset’s efficiency towards Elasticsearch at most throughput and Rockset achieved as much as 4x quicker streaming knowledge ingestion. For this benchmark, we minimized knowledge latency to show how Rockset performs to be used circumstances demanding the freshest knowledge potential.
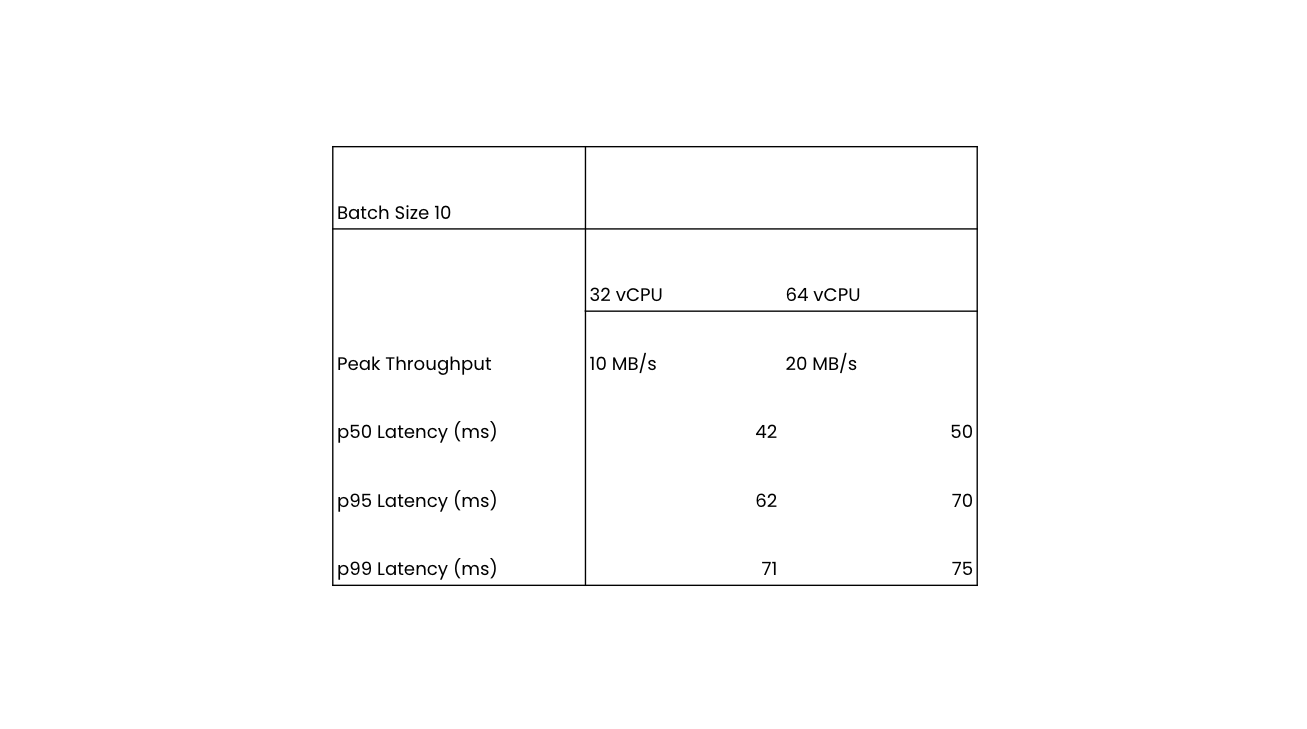
We ran the benchmark utilizing a batch dimension of 10 paperwork per write request on a beginning Rockset assortment dimension of 300 GB. The benchmark held the ingestion throughput fixed at 10 MB/s and 20 MB/s and recorded the p50, p95 and p99 knowledge latencies.
The benchmark was run on XL and 2XL digital situations or devoted allocations of compute and reminiscence sources. The XL digital occasion has 32 vCPU and 256 GB reminiscence and the 2XL has 64 vCPU and 512 GB reminiscence.
Listed below are the abstract outcomes of the benchmark at p50, p95 and p99 latencies on Rockset:
Outcomes Desk
Outcomes Bar Chart
At p95 knowledge latency, Rockset was capable of obtain 70 ms on 20 MB/s throughput. The efficiency outcomes present that as throughput scales and the scale of the digital occasion will increase, Rockset is ready to keep comparable knowledge latencies. Moreover, the info latencies for the p95 and p99 averages are clustered shut collectively exhibiting predictable efficiency.
Rockset Efficiency Enhancements
There are a number of efficiency enhancements that allow Rockset to attain millisecond knowledge latency:
Compute-Compute Separation
Rockset lately unveiled a brand new cloud structure for real-time analytics: compute-compute separation. The structure permits customers to spin up a number of, remoted digital situations on the identical shared knowledge. With the brand new structure in place, customers can isolate the compute used for streaming ingestion from the compute used for queries, guaranteeing not simply excessive efficiency, however predictable, environment friendly excessive efficiency. Customers now not have to overprovision compute or add replicas to beat compute competition.
One of many advantages of this new structure is that we have been capable of eradicate duplicate duties within the ingestion course of so that every one knowledge parsing, knowledge transformation, knowledge indexing and compaction solely occur as soon as. This considerably reduces the CPU overhead required for ingestion, whereas sustaining reliability and enabling customers to attain even higher price-performance.
RocksDB Improve
Rockset makes use of RocksDB as its embedded storage engine below the hood. The staff at Rockset created and open-sourced RocksDB whereas at Fb and it’s presently utilized in manufacturing at Linkedin, Netflix, Pinterest and extra web-scale corporations. Rockset chosen RocksDB for its efficiency and skill to deal with ceaselessly mutating knowledge effectively. Rockset leverages the newest model of RocksDB, model 7.8.0+, to scale back the write amplification by greater than 10%.
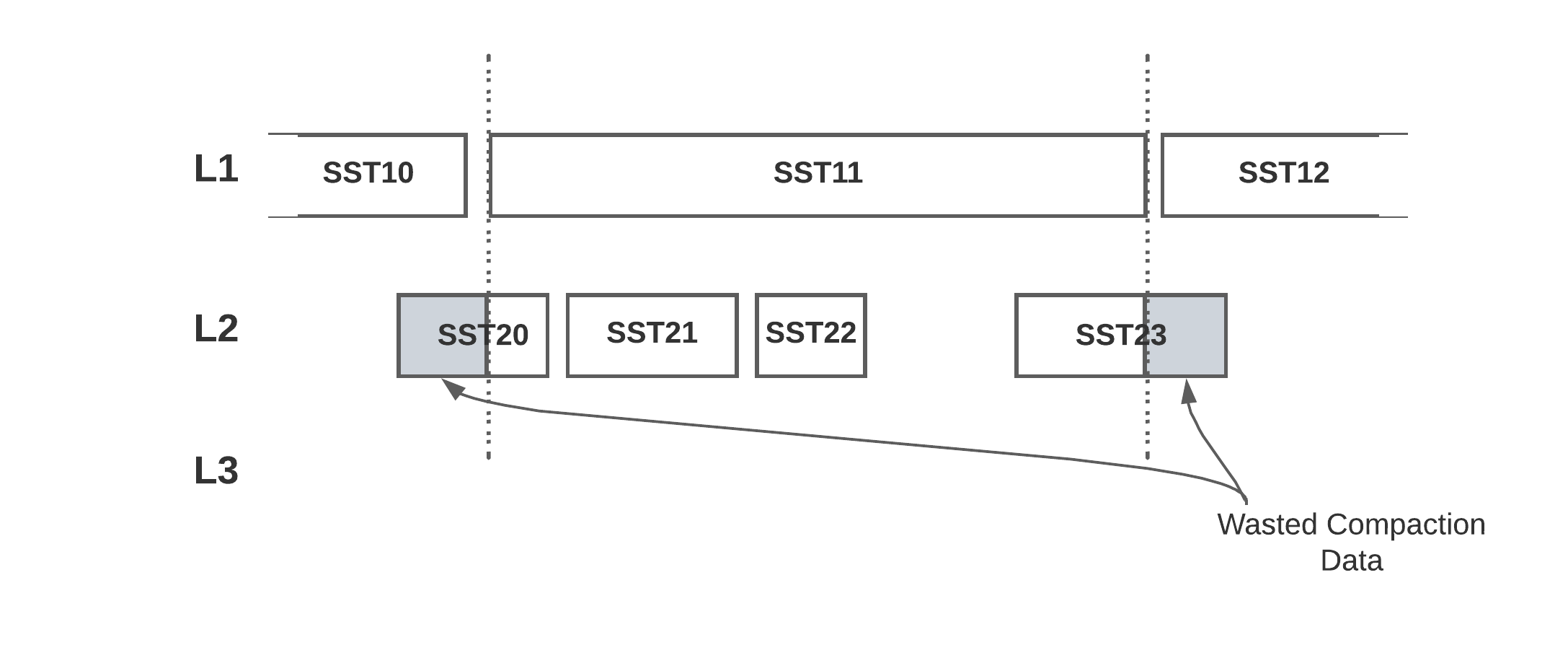
Earlier variations of RocksDB used a partial merge compaction algorithm, which picks one file from the supply stage and compacts to the subsequent stage. In comparison with a full merge compaction, this produces smaller compaction dimension and higher parallelism. Nevertheless, it additionally leads to write amplification.
Earlier RocksDB Merge Compaction Algorithm
In RocksDB model 7.8.0+, the compaction output file is minimize earlier and permits bigger than targeted_file_size to align compaction recordsdata to the subsequent stage recordsdata. This reduces write amplification by 10+ %.
New RocksDB Merge Compaction Algorithm
By upgrading to this new model of RocksDB, the discount in write amplification means higher ingest efficiency, which you’ll be able to see mirrored within the benchmark outcomes.
Customized Parsers
Rockset has schemaless ingest and helps all kinds of knowledge codecs together with JSON, Parquet, Avro, XML and extra. Rockset’s capacity to natively help SQL on semi-structured knowledge minimizes the necessity for upstream pipelines that add knowledge latency. To make this knowledge queryable, Rockset converts the info into a normal proprietary format at ingestion time utilizing knowledge parsers.
Information parsers are answerable for downloading and parsing knowledge to make it obtainable for indexing. Rockset’s legacy knowledge parsers leveraged open-source elements that didn’t effectively use reminiscence or compute. Moreover, the legacy parsers transformed knowledge to an middleman format earlier than once more changing knowledge to Rockset’s proprietary format. To be able to decrease latency and compute, the info parsers have been rewritten in a {custom} format. Customized knowledge parsers are twice as quick, serving to to attain the info latency outcomes captured on this benchmark.
How Efficiency Enhancements Profit Clients
Rockset delivers predictable, excessive efficiency ingestion that allows prospects throughout industries to construct functions on streaming knowledge. Listed below are a couple of examples of latency-sensitive functions constructed on Rockset in insurance coverage, gaming, healthcare and monetary providers industries:
Insurance coverage {industry}: The digitization of the insurance coverage {industry} is prompting insurers to ship insurance policies which might be tailor-made to the danger profiles of consumers and tailored in realm time. A fortune 500 insurance coverage firm gives prompt insurance coverage quotes based mostly on tons of of threat elements, requiring lower than 200 ms knowledge latency with a view to generate real-time insurance coverage quotes.
Gaming {industry}: Actual-time leaderboards increase gamer engagement and retention with stay metrics. A number one esports gaming firm requires 200 ms knowledge latency to indicate how video games progress in actual time.
Monetary providers: Monetary administration software program helps corporations and people observe their monetary well being and the place their cash is being spent. A Fortune 500 firm makes use of real-time analytics to supply a 360 diploma of funds, displaying the newest transactions in below 500 ms.
Healthcare {industry}: Well being info and affected person profiles are continuously altering with new check outcomes, treatment updates and affected person communication. A number one healthcare participant helps scientific groups monitor and observe sufferers in actual time, with a knowledge latency requirement of below 2 seconds.
Rockset scales ingestion to help excessive velocity streaming knowledge with out incurring any unfavourable impression on question efficiency. In consequence, corporations throughout industries are unlocking the worth of real-time streaming knowledge in an environment friendly, accessible means. We’re excited to proceed to push the decrease limits of knowledge latency and share the newest efficiency benchmark with Rockset attaining 70 ms knowledge latency on 20 MB/s of streaming knowledge ingestion.
You can also expertise these efficiency enhancements robotically and with out requiring infrastructure tuning or guide upgrades by beginning a free trial of Rockset at present.
Richard Lin and Kshitij Wadhwa, software program engineers at Rockset, carried out the info latency investigation and testing on which this weblog is predicated.