Researchers have found one other data-seizing macOS malware, with “Cthulhu Stealer” bought to on-line criminals for simply $500 a month.
The Mac is turning into much more of a goal for malware, with warnings surfacing from researchers surfacing frequently. Within the newest instance, it is for malware that is been in circulation for fairly a couple of months.
Defined by Cato Safety and reported by Hacker Information on Friday, the malware known as “Cthulu Stealer” has apparently been round since late 2023. Consisting of “Malware-as-a-Service,” it was ready for use by on-line criminals for a mere $500 per thirty days.
Unhealthy disk photos
The malware takes the type of an Apple disk picture that incorporates a pair of binaries. This allowed it to assault each Intel and Apple Silicon Macs, relying on the detected structure.
To attempt to entice shoppers to open it, the malware can be disguised as different software program, together with Grand Theft Auto IV and CleanMyMac. It additionally appeared as Adobe GenP, a software for patching Adobe apps in order that they do not depend on receiving a paid safety key from the Inventive Cloud.
The supposed contents was a ploy to persuade customers to launch the unsigned file and permitting it to run after bypassing Gatekeeper. The customers are then requested to enter their system password, adopted by a password for the MetaMask cryptocurrency pockets.
With these passwords in place, system info and iCloud Keychain passwords are stolen, together with internet browser cookies and Telegram account particulars. They’re despatched off to a management server.
“The principle performance of Cthulhu Stealer is to steal credentials and cryptocurrency wallets from varied shops, together with sport accounts,” stated Cato Safety researcher Tara Gould.
Borrowing code
Evaluation of the malware signifies that the malware is much like one other that was beforehand discovered by the title of “Atomic Stealer.”
It’s thought that whomever made Cthulu Stealer used the code that produced Atomic Stealer as a base. Except for performance, the primary proof of that is an OSA script that prompts for the person’s password, which has the identical spelling errors.
Unusually for found malware, it seems that the creators of Cthulhu Stealer aren’t in a position to handle it, as a result of fee disputes. The developer behind it was completely banned from a cybercrime market that marketed the software over accusations of an exit rip-off that affected different market customers.
Defending your self
Customers haven’t got to do this a lot to guard themselves from Cthulhu Stealer, not least due to possession management points.
As ordinary, the recommendation is to be vigilant about what apps you obtain, that you simply obtain from secure sources, and to concentrate to what the app does as you put in it.
As for overriding Gatekeeper, that is one thing that may be achieved simply in macOS Sonoma and earlier releases. For macOS Sequoia, customers can’t Management-click to override Gatekeeper, however might want to go to System Settings then Privateness & Safety to evaluate a software program’s safety info as a substitute.
This modification ought to cut back the variety of situations the place Gatekeeper is bypassed, just by including extra obstacles.
Even so, customers ought to nonetheless listen each time Gatekeeper raises an objection to putting in or operating an app.
“Antivirus software program slows down my PC.” It is a remark that’s typically heard when speaking about antivirus and malware safety.
That is perhaps the case with many safety merchandise, but it surely’s not the case with McAfee. Unbiased assessments since 2016 have confirmed that McAfee is just not solely good at catching malware and viruses, but in addition one of many lightest safety merchandise accessible at present.
What’s antivirus safety?
Antivirus varieties a significant cornerstone of on-line safety software program. It protects your units towards malware and viruses via a mix of prevention, detection, and removing. Ours makes use of AI to detect absolutely the newest threats — and has for a number of years now.
For many years, individuals have put in antivirus software program on their computer systems. At present, it might probably additionally shield your smartphones and tablets as properly. In truth, we suggest putting in it on these units as properly as a result of they’re related, identical to a pc. And any system that connects to the web is a possible goal for malware and viruses.
One vital distinction about antivirus is its title, a reputation that first got here into use years in the past when viruses first appeared on the scene. Nonetheless, antivirus protects you from greater than viruses. It protects towards the broad class of malware too — issues like adware, ransomware, and keyloggers.
How does efficiency get measured?
To measure how a lot influence on-line safety software program has on PC efficiency, some impartial take a look at labs embody efficiency influence benchmarks of their safety product assessments. Essentially the most well-known of those take a look at labs are AV-TEST, which relies in Germany, and Austria-based AV-Comparatives. These impartial labs are among the many most respected and well-known anti-malware take a look at labs on the planet.
Through the years, we’ve examined strongly. These outcomes bought stronger nonetheless with the discharge of our McAfee Subsequent-gen Menace Safety.
McAfee’s AI-powered safety simply bought sooner and stronger. Our Subsequent-gen Menace Safety takes up much less disk area, reduces its background processes by 75%, and scans 3x sooner than earlier than. This makes your time on-line safer with out slowing down your looking, purchasing, streaming, and gaming.
And the outcomes present it.
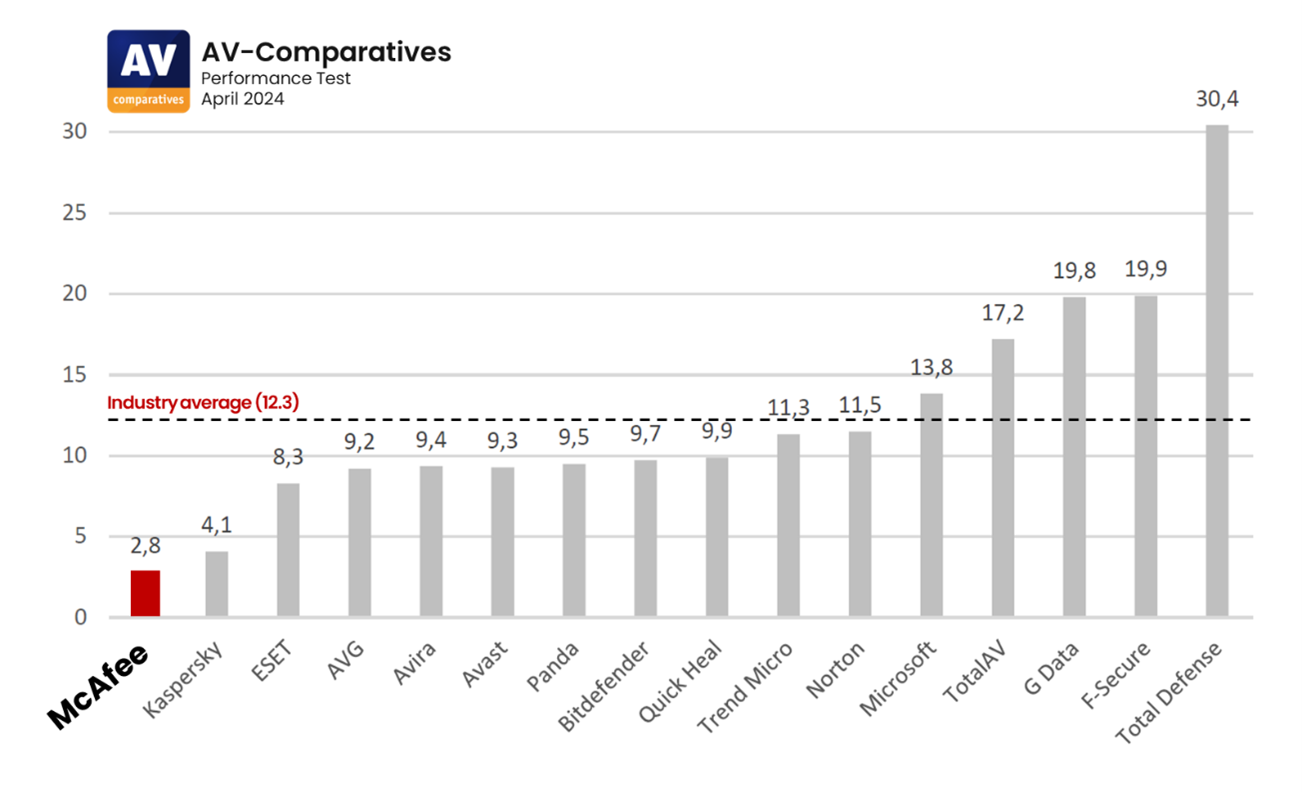
McAfee got here in with the bottom system influence rating in a subject of 16. With an total influence rating of two.8, it weighed in far lower than the business common of 12.3. This excellent efficiency earned McAfee the very best potential rating: ADVANCED+ 3 Stars.
Sturdy antivirus doesn’t must gradual you down
Even with sturdy safety constantly monitoring all exercise in your PC and laptop computer for threats, the perfect form of antivirus retains your units working rapidly.
Advances in our already high-performing safety have solidified our glorious standing in impartial assessments. The labs run them commonly, and we take delight in realizing that we’re not solely defending you, we’re preserving you shifting alongside at an excellent clip.
Introducing McAfee+
Id theft safety and privateness in your digital life
Assessing a machine studying mannequin isn’t simply the ultimate step—it’s the keystone of success. Think about constructing a cutting-edge mannequin that dazzles with excessive accuracy, solely to seek out it crumbles below real-world stress. Analysis is greater than ticking off metrics; it’s about making certain your mannequin constantly performs within the wild. On this article, we’ll dive into the widespread pitfalls that may derail even probably the most promising classification fashions and reveal the very best practices that may elevate your mannequin from good to distinctive. Let’s flip your classification modeling duties into dependable, efficient options.
Overview
Assemble a classification mannequin: Construct a strong classification mannequin with step-by-step steering.
Establish frequent errors: Spot and keep away from widespread pitfalls in classification modeling.
Comprehend overfitting: Perceive overfitting and learn to forestall it in your fashions.
Enhance model-building expertise: Improve your model-building expertise with finest practices and superior strategies.
Classification Modeling: An Overview
Within the classification drawback, we attempt to construct a mannequin that predicts the labels of the goal variable utilizing impartial variables. As we cope with labeled goal knowledge, we’ll want supervised machine studying algorithms like Logistic Regression, SVM, Choice Tree, and so on. We can even have a look at Neural Community fashions for fixing the classification drawback, figuring out widespread errors individuals would possibly make, and figuring out the best way to keep away from them.
Constructing a Fundamental Classification Mannequin
We’ll reveal making a basic classification mannequin utilizing the Date-Fruit dataset from Kaggle. Concerning the dataset: The goal variable consists of seven varieties of date fruits: Barhee, Deglet Nour, Sukkary, Rotab Mozafati, Ruthana, Safawi, and Sagai. The dataset consists of 898 photographs of seven completely different date fruit varieties, and 34 options had been extracted via picture processing strategies. The target is to categorise these fruits primarily based on their attributes.
1. Information Preparation
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Load the dataset
knowledge = pd.read_excel('/content material/Date_Fruit_Datasets.xlsx')
# Splitting the info into options and goal
X = knowledge.drop('Class', axis=1)
y = knowledge['Class']
# Splitting the dataset into coaching and testing units
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Function scaling
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.remodel(X_test)
Classification fashions can encounter a number of challenges that will compromise their effectiveness. It’s important to acknowledge and deal with these issues to construct dependable fashions. Under are some essential elements to think about:
Overfitting and Underfitting:
Cross-Validation: Keep away from relying solely on a single train-test break up. Make the most of k-fold cross-validation to higher assess your mannequin’s efficiency by testing it on varied knowledge segments.
Regularization: Extremely complicated fashions would possibly overfit by capturing noise within the knowledge. Regularization strategies like pruning or regularisation ought to be used to penalize complexity.
Hyperparameter Optimization: Completely discover and tune hyperparameters (e.g., via grid or random search) to stability bias and variance.
Ensemble Methods:
Mannequin Aggregation: Ensemble strategies like Random Forests or Gradient Boosting mix predictions from a number of fashions, typically leading to enhanced generalization. These strategies can seize intricate patterns within the knowledge whereas mitigating the danger of overfitting by averaging out particular person mannequin errors.
Class Imbalance:
Imbalanced Courses: In lots of circumstances one class is perhaps much less in rely than others, resulting in biased predictions. Strategies like Oversampling, Undersampling or SMOTE have to be used based on the issue.
Information Leakage:
Unintentional Leakage: Information leakage occurs when data from outdoors the coaching set influences the mannequin, inflicting inflated efficiency metrics. It’s essential to make sure that the take a look at knowledge stays totally unseen throughout coaching and that options derived from the goal variable are managed with care.
Instance of improved Logistic Regression utilizing Grid Search
from sklearn.model_selection import GridSearchCV
# Implementing Grid Seek for Logistic Regression
param_grid = {'C': [0.1, 1, 10, 100], 'solver': ['lbfgs']}
grid_search = GridSearchCV(LogisticRegression(multi_class="multinomial", max_iter=1000), param_grid, cv=5)
grid_search.match(X_train, y_train)
# Greatest mannequin
best_model = grid_search.best_estimator_
# Consider on take a look at set
test_accuracy = best_model.rating(X_test, y_test)
print(f"Greatest Logistic Regression - Check Accuracy: {test_accuracy}")
Let’s deal with enhancing our earlier neural community mannequin, specializing in strategies to reduce overfitting and improve generalization.
Early Stopping and Mannequin Checkpointing
Early Stopping ceases coaching when the mannequin’s validation efficiency plateaus, stopping overfitting by avoiding extreme studying from coaching knowledge noise.
Mannequin Checkpointing saves the mannequin that performs finest on the validation set all through coaching, making certain that the optimum mannequin model is preserved even when subsequent coaching results in overfitting.
import numpy as np
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split
from tensorflow.keras import fashions, layers
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# Label encode the goal courses
label_encoder = LabelEncoder()
y_encoded = label_encoder.fit_transform(y)
# Prepare-test break up
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)
# Function scaling
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.remodel(X_test)
# Neural Community
mannequin = fashions.Sequential([
layers.Dense(64, activation='relu', input_shape=(X_train.shape[1],)),
layers.Dense(32, activation='relu'),
layers.Dense(len(np.distinctive(y_encoded)), activation='softmax') # Guarantee output layer measurement matches variety of courses
])
mannequin.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=['accuracy'])
# Callbacks
early_stopping = EarlyStopping(monitor="val_loss", endurance=10, restore_best_weights=True)
model_checkpoint = ModelCheckpoint('best_model.keras', monitor="val_loss", save_best_only=True)
# Prepare the mannequin
historical past = mannequin.match(X_train, y_train, epochs=100, batch_size=32, validation_data=(X_test, y_test),
callbacks=[early_stopping, model_checkpoint], verbose=1)
# Consider the mannequin
train_loss, train_accuracy = mannequin.consider(X_train, y_train, verbose=0)
test_loss, test_accuracy = mannequin.consider(X_test, y_test, verbose=0)
print(f"Neural Community - Prepare Accuracy: {train_accuracy}, Check Accuracy: {test_accuracy}")
Understanding the Significance of Numerous Metrics
Accuracy: Though essential, accuracy may not totally seize a mannequin’s efficiency, notably when coping with imbalanced class distributions.
Loss: The loss operate evaluates how properly the anticipated values align with the true labels; smaller loss values point out greater accuracy.
Precision, Recall, and F1-Rating: Precision evaluates the correctness of optimistic predictions, recall measures the mannequin’s success in figuring out all optimistic circumstances, and the F1-score balances precision and recall.
ROC-AUC: The ROC-AUC metric quantifies the mannequin’s capability to differentiate between courses whatever the threshold setting.
The mannequin’s efficiency throughout coaching might be seen by plotting studying curves for accuracy and loss, displaying whether or not the mannequin is overfitting or underfitting. We used early stopping to stop overfitting, and this helps generalize to new knowledge.
Meticulous analysis is essential to stop points like overfitting and underfitting. Constructing efficient classification fashions includes greater than selecting and coaching the proper algorithm. Mannequin consistency and reliability might be enhanced by implementing ensemble strategies, regularization, tuning hyperparameters, and cross-validation. Though our small dataset could not have skilled vital overfitting, using these strategies ensures that fashions are sturdy and exact, main to higher decision-making in sensible purposes.
Incessantly Requested Questions
Q1. Why is it essential to evaluate a machine studying mannequin past accuracy?
Ans. Whereas accuracy is a key metric, it doesn’t at all times give an entire image, particularly with imbalanced datasets. Evaluating different elements like consistency, robustness, and generalization ensures that the mannequin performs properly throughout varied eventualities, not simply in managed take a look at circumstances.
Q2. What are the widespread errors to keep away from when constructing classification fashions?
Ans. Frequent errors embrace overfitting, underfitting, knowledge leakage, ignoring class imbalance, and failing to validate the mannequin correctly. These points can result in fashions that carry out properly in testing however fail in real-world purposes.
Q3. How can I forestall overfitting in my classification mannequin?
Ans. Overfitting might be mitigated via cross-validation, regularization, early stopping, and ensemble strategies. These approaches assist stability the mannequin’s complexity and guarantee it generalizes properly to new knowledge.
This autumn. What metrics ought to I take advantage of to guage the efficiency of my classification mannequin?
Ans. Past accuracy, contemplate metrics like precision, recall, F1-score, ROC-AUC, and loss. These metrics present a extra nuanced understanding of the mannequin’s efficiency, particularly in dealing with imbalanced knowledge and making correct predictions.
LLMs have turn into one of the vital essential applied sciences to emerge in recent times. Most of the most outstanding LLM instruments are closed supply, which has led to nice curiosity in growing open-source instruments.
Antonio Velasco Fernández is a Knowledge Scientist and Jose Pablo Cabeza García is a Lead Knowledge Engineer, each at Elastacloud. On this episode, recorded in 2023, they joined the podcast to speak about LLMs and the significance of group improvement for LMMs.
Jordi Mon Companys is a product supervisor and marketer that makes a speciality of software program supply, developer expertise, cloud native and open supply. He has developed his profession at corporations like GitLab, Weaveworks, Harness and different platform and devtool suppliers. His pursuits vary from software program provide chain safety to open supply innovation. You’ll be able to attain out to him on Twitter at @jordimonpmm
This episode of Software program Engineering Each day is dropped at you by Vantage. Have you learnt what your cloud invoice can be for this month?
For a lot of corporations, cloud prices are the quantity two line merchandise of their price range and the primary quickest rising class of spend.
Vantage helps you get a deal with in your cloud payments, with self-serve stories and dashboards constructed for engineers, finance, and operations groups. With Vantage, you may put prices within the palms of the service homeowners and managers who generate them—giving them budgets, alerts, anomaly detection, and granular visibility into each greenback.
With native billing integrations with dozens of cloud providers, together with AWS, Azure, GCP, Datadog, Snowflake, and Kubernetes, Vantage is the one FinOps platform to observe and scale back all of your cloud payments.
To get began, head to vantage.sh, join your accounts, and get a free financial savings estimate as a part of a 14-day free trial.
This episode of Software program Engineering Each day is dropped at you by Starburst.
Struggling to ship analytics on the pace your customers need with out your prices snowballing?
For knowledge engineers who battle to construct and scale prime quality knowledge pipelines, Starburst’s knowledge lakehouse platform helps you ship distinctive consumer experiences at peta-byte scale, with out compromising on efficiency or price.
Trusted by the groups at Comcast, Doordash, and MIT, Starburst delivers the adaptability and suppleness a lakehouse ecosystem guarantees on an open structure that helps – Apache Iceberg, Delta Lake and Hudi, so that you at all times keep possession of your knowledge.
Wish to see Starburst in motion? Get began right now with a free trial at starburst.io/sed.
As a listener of Software program Engineering Each day you perceive the affect of generative AI. On the podcast, we’ve coated many thrilling elements of GenAI applied sciences, in addition to the brand new vulnerabilities and dangers they bring about.
HackerOne’s AI purple teaming addresses the novel challenges of AI security and safety for companies launching new AI deployments.
Their method includes stress-testing AI fashions and deployments to ensure they will’t be tricked into offering data past their meant use, and that safety flaws can’t be exploited to entry confidential knowledge or methods.
Throughout the HackerOne group, over 750 energetic hackers concentrate on immediate hacking and different AI safety and security testing.
In a single latest engagement, a staff of 18 HackerOne hackers rapidly recognized 26 legitimate findings throughout the preliminary 24 hours and accrued over 100 legitimate findings within the two-week engagement.
HackerOne presents strategic flexibility, speedy deployment, and a hybrid expertise technique. Be taught extra at Hackerone.com/ai.
Cybersecurity researchers have uncovered new Android malware that may relay victims’ contactless fee information from bodily credit score and debit playing cards to an attacker-controlled machine with the purpose of conducting fraudulent operations.
The Slovak cybersecurity firm is monitoring the novel malware as NGate, stating it noticed the crimeware marketing campaign focusing on three banks in Czechia.
The malware “has the distinctive capacity to relay information from victims’ fee playing cards, through a malicious app put in on their Android units, to the attacker’s rooted Android telephone,” researchers Lukáš Štefanko and Jakub Osmani mentioned in an evaluation.
The exercise is a part of a broader marketing campaign that has been discovered to focus on monetary establishments in Czechia since November 2023 utilizing malicious progressive internet apps (PWAs) and WebAPKs. The primary recorded use of NGate was in March 2024.
The tip purpose of the assaults is to clone near-field communication (NFC) information from victims’ bodily fee playing cards utilizing NGate and transmit the data to an attacker machine that then emulates the unique card to withdraw cash from an ATM.
NGate has its roots in a professional software named NFCGate, which was initially developed in 2015 for safety analysis functions by college students of the Safe Cell Networking Lab at TU Darmstadt.
The assault chains are believed to contain a mix of social engineering and SMS phishing to trick customers into putting in NGate by directing customers to short-lived domains impersonating professional banking web sites or official cell banking apps accessible on the Google Play retailer.
As many as six totally different NGate apps have been recognized to this point between November 2023 and March 2024, when the actions got here to a halt seemingly following the arrest of a 22-year-old by Czech authorities in reference to stealing funds from ATMs.
NGate, moreover abusing the performance of NFCGate to seize NFC visitors and cross it alongside to a different machine, prompts customers to enter delicate monetary info, together with banking shopper ID, date of delivery, and the PIN code for his or her banking card. The phishing web page is introduced inside a WebView.
“It additionally asks them to activate the NFC characteristic on their smartphone,” the researchers mentioned. “Then, victims are instructed to position their fee card behind their smartphone till the malicious app acknowledges the cardboard.”
The assaults additional undertake an insidious method in that victims, after having put in the PWA or WebAPK app by means of hyperlinks despatched through SMS messages, have their credentials phished and subsequently obtain calls from the risk actor, who pretends to be a financial institution worker and informs them that their checking account had been compromised because of putting in the app.
They’re subsequently instructed to alter their PIN and validate their banking card utilizing a special cell app (i.e., NGate), an set up hyperlink to which can be despatched by means of SMS. There isn’t a proof that these apps had been distributed by means of the Google Play Retailer.
“NGate makes use of two distinct servers to facilitate its operations,” the researchers defined. “The primary is a phishing web site designed to lure victims into offering delicate info and able to initiating an NFC relay assault. The second is an NFCGate relay server tasked with redirecting NFC visitors from the sufferer’s machine to the attacker’s.”
The disclosure comes as Zscaler ThreatLabz detailed a brand new variant of a identified Android banking trojan referred to as Copybara that is propagated through voice phishing (vishing) assaults and lures them into getting into their checking account credentials.
“This new variant of Copybara has been energetic since November 2023, and makes use of the MQTT protocol to ascertain communication with its command-and-control (C2) server,” Ruchna Nigam mentioned.
“The malware abuses the accessibility service characteristic that’s native to Android units to exert granular management over the contaminated machine. Within the background, the malware additionally proceeds to obtain phishing pages that imitate common cryptocurrency exchanges and monetary establishments with the usage of their logos and software names.”
Discovered this text attention-grabbing? Observe us on Twitter and LinkedIn to learn extra unique content material we publish.