Following on from our latest article on the kernel drivers in Sophos Intercept X, by which we mentioned how they’re examined and what they do, we’re offering additional transparency into the internal workings of Intercept X – this time with a take a look at content material updates which might be both configuration adjustments that lead to adjustments to code execution paths, or are code themselves.
Intercept X makes use of a mixture of real-time Cloud lookups and on-device content material updates. As a result of the risk panorama is continually evolving and shifting, it’s essential that on-device content material updates are delivered often (some on-device knowledge adjustments much less often, however might require updates at brief discover). Nevertheless, this comes with its personal dangers; if content material updates are corrupt or invalid, this may end up in disruption.
Sophos makes use of a typical mechanism to distribute on-device content material updates, that are loaded into low-privileged Sophos user-space processes (reasonably than being loaded into or interpreted by Sophos kernel drivers) from Sophos’s Content material Distribution Community (CDN). Content material updates type one of many three foremost parts of Intercept X, together with software program from the CDN, and coverage and configuration from Sophos Central.
On this article, we’ll discover the varied varieties of content material updates we use, how we confirm and validate them, and the way the ecosystem is architected to keep away from points brought on by corrupt or faulty content material. (As we famous in our earlier article, Intercept X (and all its parts) has additionally been a part of an exterior bug bounty program since December 14, 2017.)
It’s value noting that the small print inside this text are appropriate as of this writing (August 2024) however might change sooner or later as we proceed to replace and develop options.
Sophos delivers new content material updates to prospects in ‘launch teams.’ Every Sophos Central tenant is assigned to a launch group.
The primary launch group is for inside engineering testing; we don’t assign any manufacturing prospects to it. This enables our engineering groups to check new content material updates on manufacturing infrastructure, with out requiring any guide steps. If testing fails, we abort the discharge with out continuing to any additional launch teams.
If engineering qualification succeeds, we manually promote the discharge to the ‘Sophos inside’ launch group (‘dogfooding’). This contains Sophos staff’ manufacturing units, in addition to staff’ private accounts. Once more, if issues are detected or reported, we abort the discharge and don’t proceed any additional.
All being nicely, we then manually promote the discharge to public launch teams. From this level, the Sophos launch programs mechanically publish the brand new content material replace to all the discharge teams over a interval of a number of hours or days by default (see Determine 1 beneath).
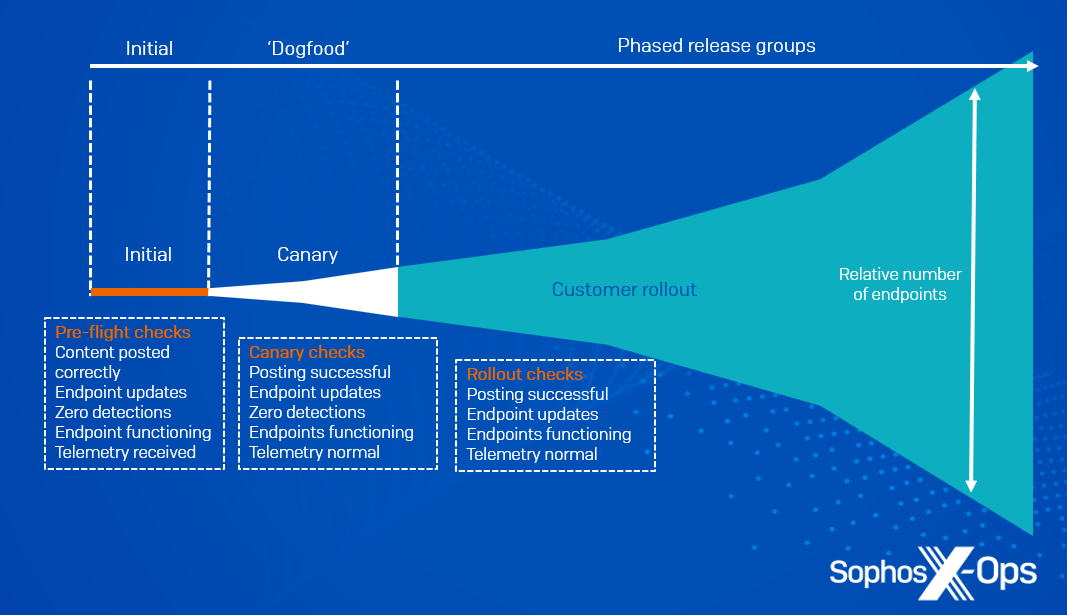
Determine 1: Phases of launch, with verification checks at every section
Sophos AutoUpdate – a part of Intercept X – checks for brand spanking new content material updates each hour, though in follow updates are much less frequent than this (see desk beneath).
Sophos AutoUpdate downloads every content material replace from the CDN and checks to see if new content material replace packages can be found for the suitable launch group.
Content material updates are time-stamped and signed utilizing SHA-384 and a non-public Sophos certificates chain. Sophos AutoUpdate verifies the updates it downloads. If it detects corrupt or untrusted updates, it discards them and warns each Sophos and the Sophos Central administrator. As well as, to guard in opposition to stale CDN caches or malicious replay assaults, Sophos AutoUpdate rejects any otherwise-valid replace whose signature timestamp is older than the already-downloaded replace.
If a brand new content material replace bundle is out there, Sophos AutoUpdate downloads and installs it utilizing the related bundle installer. Completely different updates are dealt with by completely different parts of Intercept X.
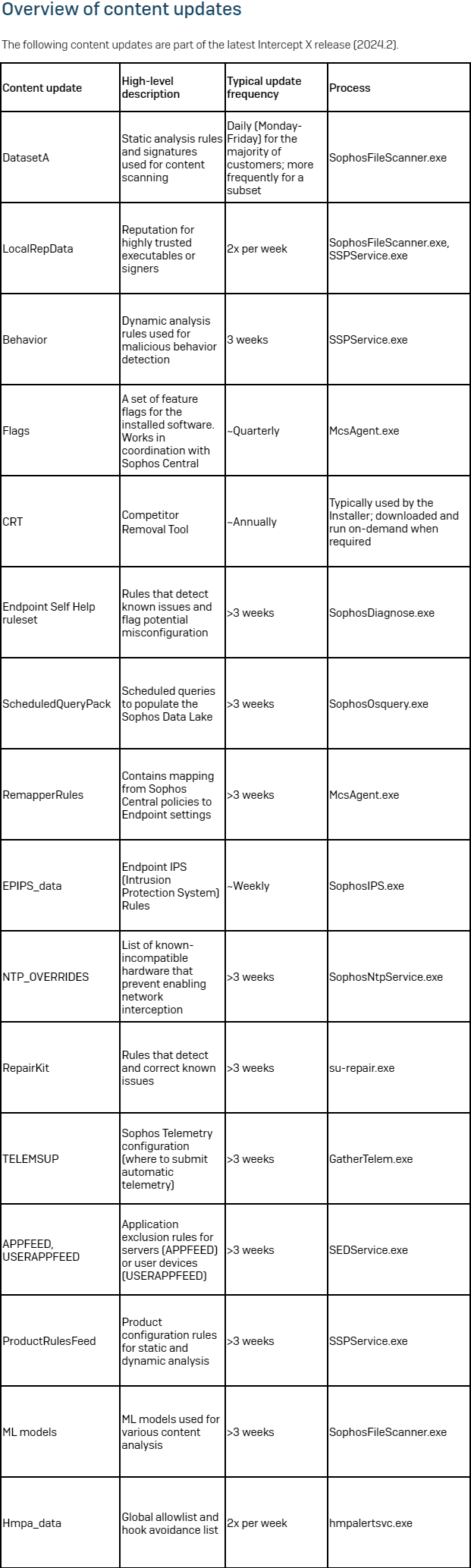
The next content material updates are a part of the most recent Intercept X launch (2042.2).
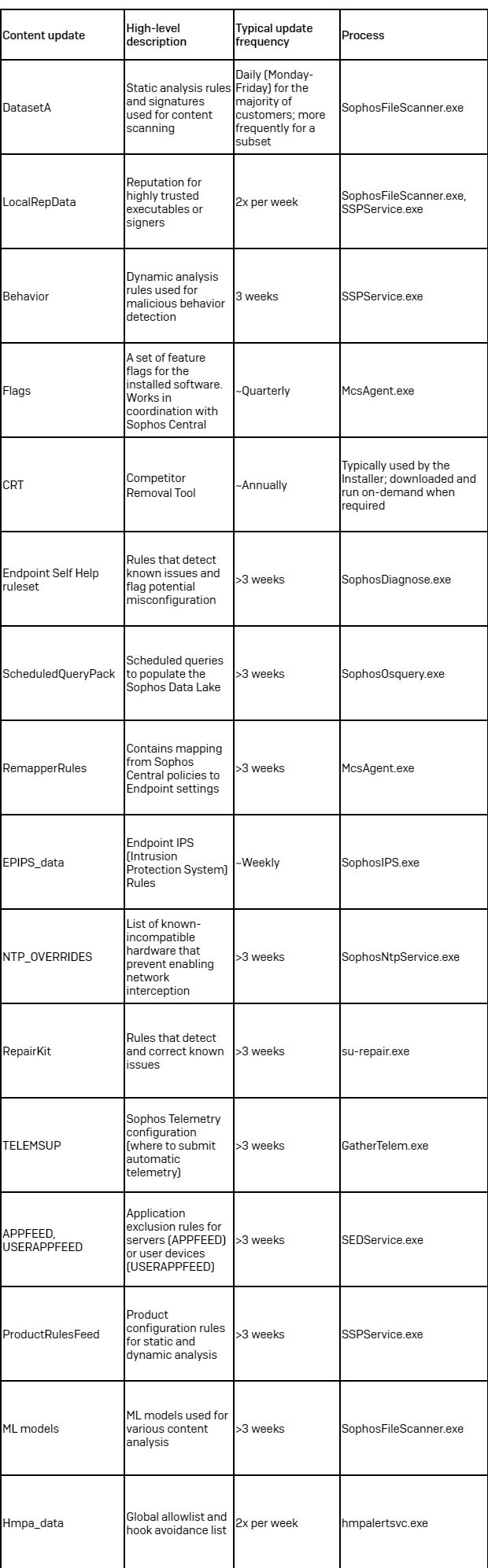 Desk 1: An outline of the content material updates which might be a part of the most recent Intercept X launch (2024.2)
Desk 1: An outline of the content material updates which might be a part of the most recent Intercept X launch (2024.2)
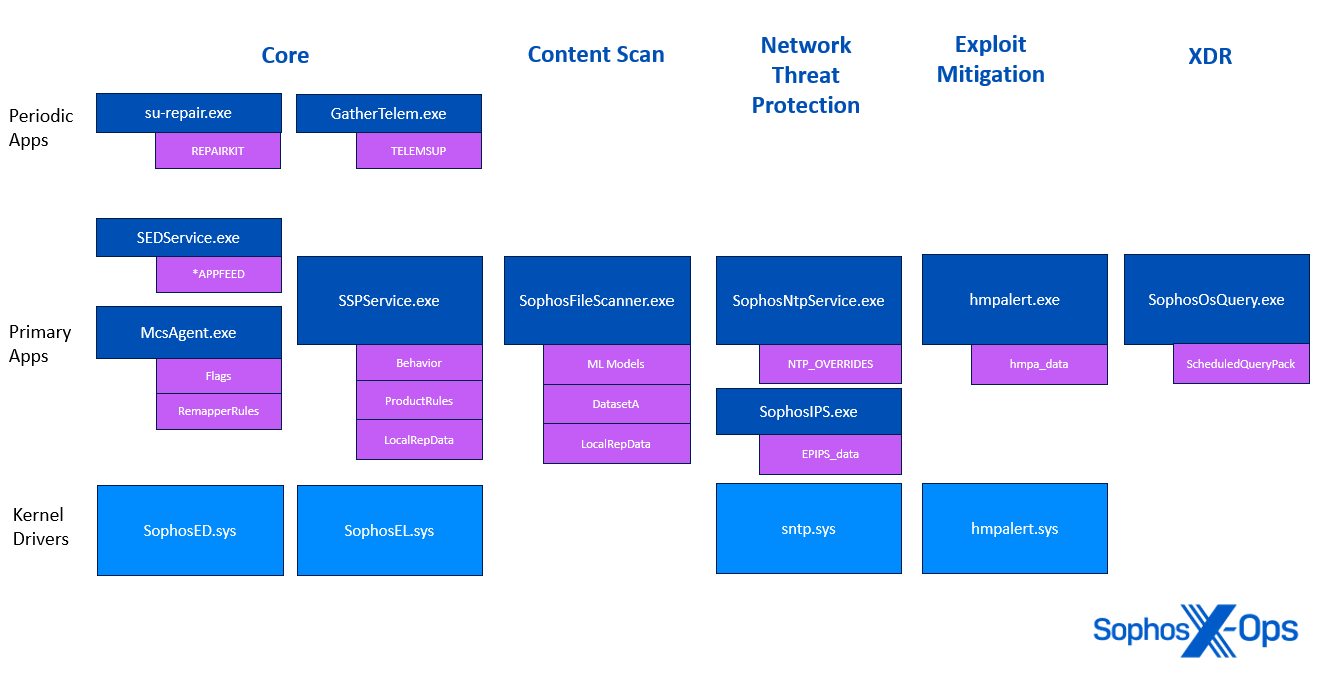
Determine 2: A diagram illustrating which Sophos processes (proven in navy blue) load which content material updates (proven in purple)
DatasetA
DatasetA is loaded by SophosFileScanner.exe, a low-privilege course of with no filesystem entry (apart from its log folder and a brief listing used for scanning massive objects). It masses the Sophos Anti-Virus Interface (SAVI).
SophosFileScanner.exe scans content material following scan requests from different Sophos processes. Though it’s referred to as “SophosFileScanner.exe”, the title is considerably historic: it’s the main content material scanner in Intercept X, scanning recordsdata, course of reminiscence, community site visitors, and so forth.
LocalRepData
LocalRepData incorporates two fame lists:
- Repute by SHA-256
- Repute by signer
When a Home windows executable begins execution, Intercept X appears to be like it up within the LocalRepData by its SHA-256 hash and its signature (assuming it’s validly signed). If the fame is supplied by LocalRepData, Intercept X ‘tags’ the method with the fame (Sophos guidelines deal with high-reputation recordsdata and processes in another way – as an illustration, exempting them from cleanup).
SSPService.exe makes use of LocalRepData to assign fame as processes launch.
SophosFileScanner.exe additionally masses LocalRepData, in order that it will probably assign fame to embedded executable streams it discovers in content material apart from executed recordsdata.
Conduct
Conduct guidelines are loaded by SSPService.exe. Guidelines recordsdata include signed and encrypted Lua code. SSPService.exe verifies, decrypts and masses the foundations right into a sandboxed LuaJIT interpreter with entry solely to Sophos-internal APIs.
Lua is a quick, embedded scripting language. Sophos makes use of Lua for habits guidelines as a result of it supplies a versatile solution to ship new habits detections with no need a brand new software program launch, however whereas nonetheless sustaining security. The foundations are loaded in user-space, so can’t trigger a important system failure in the event that they misbehave. As well as, Sophos builds its guidelines engine with out the Lua base libraries – the one entry to the system is by way of Sophos’ inside API, which is hardened in opposition to unintended misuse by the habits guidelines. Sophos collects in depth telemetry about rule runtimes, and repeatedly tunes and reduces runtime overhead.
Guidelines are reactors: Intercept X supplies numerous occasions, and guidelines register handlers for these occasions. Guidelines may configure numerous aggregation parameters for some high-volume occasions, permitting the sensor to coalesce or discard sure occasions.
Flags
Flags are the means by which Sophos steadily allows new options in Intercept X. Flags are delivered in two methods:
- The Flags Complement incorporates a baseline set of flags akin to the out there options within the software program
- The Flags Service is a Sophos Central microservice that enables Sophos Launch Engineers to configure flags throughout a number of tenants
The Flags Complement for a given software program launch incorporates a set of function flags and the way the function ought to be enabled:
| Flag Complement Worth |
Flag Service Worth |
Characteristic is… |
| Off |
Ignored |
Off |
| Accessible |
Off |
Off |
| Accessible |
On |
On |
This mechanism offers Sophos a number of avenues to allow and disable options.
- Sophos can introduce new options with the flag “Accessible” (however not enabled within the Flags Service)
- Sophos can steadily allow new options utilizing the Flags Service to allow flags throughout tenants
- Sophos can disable a problematic function by disabling the flag within the Flags Service
- Sophos can disable a problematic function in a particular software program launch by altering the discharge’s Flags Complement.
CRT
The Competitor Elimination Instrument (CRT) incorporates a algorithm for eradicating known-incompatible software program throughout the set up. It’s mechanically downloaded by the installer, and is eliminated after set up.
Usually the CRT just isn’t utilized by Intercept X; nevertheless, if a buyer installs a non-protection element like Sophos Gadget Encryption, and later opts to deploy Intercept X, the present agent downloads and installs the CRT and runs it previous to set up. As soon as Intercept X is put in, the CRT is mechanically eliminated.
Endpoint Self Assist Ruleset
The Endpoint Self Assist (ESH) guidelines are a set of standard expressions for sure log recordsdata. If Sophos engineers have recognized a typical root trigger or misconfiguration, they’ll publish a brand new rule and hyperlink again to the Information Base Article (KBA) describing the issue and the prompt resolution(s).
ScheduledQueryPack
The scheduled question pack content material replace incorporates an inventory of scheduled queries and their execution frequency. The foundations are loaded by SophosOsquery.exe; the output is delivered by McsClient.exe for ingestion by the Sophos Central Knowledge Lake.
SophosOsquery.exe has a built-in watchdog that forestalls ‘runaway’ queries from consuming extreme CPU or reminiscence. Sophos collects telemetry on scheduled question efficiency, and frequently optimizes and tunes scheduled queries to keep away from triggering the watchdog.
RemapperRules
The remapper guidelines are loaded by McsAgent.exe and used to ‘remap’ Sophos Central coverage settings into the Endpoint configuration, saved within the Home windows registry underneath HKLMSOFTWARESophosManagementPolicy.
The coverage is equipped from Central as a set of XML paperwork. The foundations are additionally a set of XML paperwork that describe the construction of the information saved within the registry and supply XPath queries and some conversion capabilities to extract content material from the coverage XML and generate registry knowledge.
If a rule file is corrupt, or if processing them fails for another cause, not one of the registry values outlined by that file are up to date and any earlier settings are left intact. Processing of different, legitimate, rule recordsdata is equally unaffected.
EPIPS_data
The EPIPS_data content material replace incorporates intrusion prevention system (IPS) signatures loaded by SophosIPS.exe. SophosIPS.exe incorporates a Sophos-built IPS product; the signatures are IPS signatures printed by SophosLabs.
SophosIPS.exe runs as a low-privilege course of. When IPS is enabled, the sntp.sys driver sends packets to SophosIPS.exe for filtering; SophosIPS.exe responds to the driving force with instructions to just accept or reject the packets.
Interacting with community flows packet-by-packet deep within the community stack requires excessive care. The Home windows Filtering Platform (WFP) callouts at L2 are very delicate to the underlying drivers, typically from third-parties, that service the bodily and media entry layers. Due to the excessive threat to system stability, the IPS function displays itself for BSODs or community disruptions which might be possible brought on by third-party driver interactions. If detected, the IPS function mechanically disables itself and units the endpoint’s well being standing to purple as an alert to the incompatibility.
NTP_OVERRIDES
One of many potential points when constructing a Home windows Filtering Platform (WFP) kernel driver is that though the platform is designed for a number of drivers to work together with the filtering stack on the similar time, Sophos has recognized sure third-party software program packages that aren’t appropriate with the IPS function, which requires the power to intercept and manipulate L2 packets.
The NTP_OVERRIDES content material replace incorporates an inventory of known-incompatible drivers. If IPS is enabled in coverage however deployed on a tool with an incompatible driver, SophosNtpService.exe disables IPS, overriding the coverage.
That is delivered as a content material replace in order that as new incompatible drivers are found, Sophos can react dynamically to guard different prospects with the identical configuration. As well as, if Sophos or third-parties replace drivers to handle the incompatibility, Sophos can take away the driving force as of a sure model.
RepairKit
Throughout every hourly replace, Sophos AutoUpdate executes a self-repair program (su-repair.exe) to detect and proper any repairable recognized points. The RepairKit was initially constructed to detect and restore file corruption brought on by unclean shutdowns that would corrupt the Sophos set up. Over time, the Sophos engineering staff has used this facility to appropriate many points that traditionally would have required a Sophos assist engagement with the shopper, or probably gone unnoticed till a future software program replace flagged the problem.
RepairKit guidelines are written in Lua and loaded by su-repair.exe. The foundations are encrypted and signed. If su-repair.exe fails to load the RepairKit guidelines, it masses a baked-in ‘final resort’ ruleset which solely focuses on repairing Sophos AutoUpdate itself.
RepairKit guidelines have broad entry to the machine and run as SYSTEM, since they want the power to appropriate privileged keys and recordsdata.
TELEMSUP
This telemetry content material replace incorporates a JSON doc describing how typically and the place to submit telemetry:
{
"additionalHeaders": "x-amz-acl:bucket-owner-full-control",
"port": 0,
"resourceRoot": "prod",
"server": "t1.sophosupd.com",
"verb": "PUT",
"interval": 86400
}
The telemetry content material replace has not modified because it was launched in 2016.
APPFEED, USERAPPFEED
The APPFEED content material updates include signed and encrypted Lua snippets for detecting put in functions and dynamically producing exclusions for them.
If an software is detected for which the APPFEED incorporates exclusion guidelines, the foundations dynamically generate machine-specific exclusions based mostly on the put in software. These exclusions are reported again to Sophos Central for informational show to the Sophos Central administrator.
The foundations have read-only entry to the registry and filesystem, and customarily function by searching for recognized apps within the Add/Take away Packages registry keys. Some functions, like Microsoft SQL Server, require executing PowerShell script to detect non-obligatory OS parts.
APPFEED and USERAPPFEED are loaded by an occasion of SEDService.exe.
ProductRulesFeed
Product guidelines are loaded by SSPService.exe. They’re in the identical format as Conduct guidelines, with the identical entry and privileges. They’re loaded into the identical LuaJIT interpreter and supply core performance required by the Conduct guidelines.
ML fashions
The ML fashions content material replace incorporates a number of machine studying fashions loaded by SophosFileScanner.exe. In contrast to most content material updates, ML fashions include Home windows DLLs that include the core ML mannequin logic, in addition to the ‘weights’ – the results of coaching and tuning fashions within the SophosLabs Cloud.
The ML fashions are loaded by SophosFileScanner.exe and are run in the identical low-privilege setting. SophosFileScanner.exe helps loading two variations of every mannequin: ‘telemetry’ and ‘dwell.’ Sophos makes use of this functionality to ship candidate ML fashions in telemetry mode. When SophosFileScanner.exe has an ML mannequin in telemetry mode, it selects a pattern of knowledge for telemetry evaluation, and runs it by the telemetry mannequin (along with regular actions). The output from the telemetry mannequin, alongside the information collected by the traditional fashions, supplies telemetry to Sophos for evaluation and coaching.
Sophos delivers ML fashions as content material updates so {that a} new ML mannequin can get a number of iterations of telemetry, retraining, and fine-tuning earlier than being promoted to the dwell mannequin.
For the reason that ML mannequin replace incorporates executable code, Sophos releases it extra steadily and with extra gates:
- It spends extra time within the early launch teams (engineering testing and Sophos Inner)
- It’s launched over a number of weeks, not hours.
Hmpa_data
The Hmpa_data content material replace incorporates a worldwide allowlist of HitmanPro.Alert thumbprints. Each HitmanPro.Alert detection creates a novel thumbprint for the related mitigation and the detection-specific data. For instance, a thumbprint for a StackPivot mitigation would possibly embody the method and the previous few stack frames.
Hmpa_data incorporates a compact record of worldwide allowed thumbprints. The HitmanPro.Alert service hmpalertsvc.exe makes use of this database to rapidly and quietly suppress detections, scale back false positives, and keep away from efficiency or stability points.
- The HitmanPro.Alert driver, hmpalert.sys, generates thumbprints and sends them to the service for any driver-based mitigation: CryptoGuard, CiGuard, PrivGuard, and so on.
- The HitmanPro.Alert hook DLL, hmpalert.dll, which is injected into person processes, generates thumbprints for every detection and sends them to the service for reporting.
With the intention to maintain tempo with the ever-evolving risk panorama, and to guard in opposition to rising threats, it’s vitally essential to frequently replace safety merchandise with new knowledge. Nevertheless, corrupt or faulty content material updates could cause disruptions, so it’s additionally important that there are mechanisms in place to assist be sure that they’re legitimate, signed, and verified.
On this article, we’ve supplied a high-level overview of the content material updates we use in Intercept X – exploring what they’re, how typically they’re delivered, how they’re validated and verified, the particular low-privileged processes they’re loaded into, and the strategies we use to roll them out in a staged and managed method.
As we alluded to in our earlier article on Intercept X kernel drivers, balancing safety and security is dangerous – however we’re dedicated to managing that threat, as transparently as doable.