An summary of the actions of chosen APT teams investigated and analyzed by ESET Analysis in This autumn 2023 and Q1 2024
14 Might 2024 • , 2 min. learn
ESET APT Exercise Report This autumn 2023–Q1 2024 summarizes notable actions of chosen superior persistent menace (APT) teams that had been documented by ESET researchers from October 2023 till the tip of March 2024. The highlighted operations are consultant of the broader panorama of threats we investigated throughout this era, illustrating the important thing tendencies and developments, and comprise solely a fraction of the cybersecurity intelligence knowledge offered to clients of ESET’s personal APT stories.
Within the monitored timeframe, a number of China-aligned menace actors exploited vulnerabilities in public-facing home equipment, resembling VPNs and firewalls, and software program, resembling Confluence and Microsoft Alternate Server, for preliminary entry to targets in a number of verticals. Primarily based on the info leak from I-SOON (Anxun), we are able to affirm that this Chinese language contractor is certainly engaged in cyberespionage. We monitor part of the corporate’s actions beneath the FishMonger group. On this report, we additionally introduce a brand new China-aligned APT group, CeranaKeeper, distinguished by distinctive traits but probably sharing a digital quartermaster with the Mustang Panda group.
Following the Hamas-led assault on Israel in October 2023, we detected a big improve in exercise from Iran-aligned menace teams. Particularly, MuddyWater and Agrius transitioned from their earlier deal with cyberespionage and ransomware, respectively, to extra aggressive methods involving entry brokering and affect assaults. In the meantime, OilRig and Ballistic Bobcat actions noticed a downturn, suggesting a strategic shift towards extra noticeable, “louder” operations aimed toward Israel. North Korea-aligned teams continued to focus on aerospace and protection firms, and the cryptocurrency trade, bettering their tradecraft by conducting supply-chain assaults, growing trojanized software program installers and new malware strains, and exploiting software program vulnerabilities.
Russia-aligned teams have centered their actions on espionage throughout the European Union and assaults on Ukraine. Moreover, the Operation Texonto marketing campaign, a disinformation and psychological operation (PSYOP) uncovered by ESET researchers, has been spreading false details about Russian-election-related protests and the scenario in Ukrainian Kharkiv, fostering uncertainty amongst Ukrainians domestically and overseas.
Moreover, we highlight a marketing campaign within the Center East carried out by SturgeonPhisher, a bunch we consider to be aligned with the pursuits of Kazakhstan. We additionally focus on a watering-hole assault on a regional information web site about Gilgit-Baltistan, a disputed area administered by Pakistan, and lastly, we describe the exploitation of a zero-day vulnerability in Roundcube by Winter Vivern, a bunch we assess to be aligned with the pursuits of Belarus.
Malicious actions described in ESET APT Exercise Report This autumn 2023–Q1 2024 are detected by ESET merchandise; shared intelligence is primarily based on proprietary ESET telemetry knowledge and has been verified by ESET researchers.
Determine 1. Focused nations and sectors
Determine 2. Assault sources
ESET APT Exercise Stories comprise solely a fraction of the cybersecurity intelligence knowledge offered in ESET APT Stories PREMIUM. For extra data, go to the ESET Risk Intelligence web site.
Comply with ESET analysis on X for normal updates on key tendencies and high threats.
The Google Pixel 9 has a brand new Adaptive Contact function that’s enabled by default.
Adaptive Contact robotically adjusts your Pixel 9’s contact sensitivity based mostly on varied elements.
For instance, it boosts the sensitivity when your fingers are moist or if you apply a display protector.
The Google Pixel 9 sequence simply debuted lower than two weeks in the past, and we’re nonetheless discovering new features in regards to the telephones that Google didn’t inform us about. That isn’t too shocking, contemplating the Made by Google keynote lasted about an hour and twenty minutes, with twenty of these minutes being spent on Google’s AI companies relatively than the brand new {hardware}. Even so, we thought we already knew the whole lot there was to know in regards to the Pixel 9’s show, however because it seems, it nonetheless had another trick up its sleeves: Adaptive Contact.
Tucked below Settings > Show > Contact sensitivity is a brand new Adaptive Contact function. When Adaptive Contact is enabled, “contact sensitivity will robotically modify to your surroundings, actions and display protector.”
If this function sounds acquainted, it’s as a result of we reported again in March that the Pixel 9 could debut Adaptive Contact. On the time, although, we didn’t know what environmental elements or actions would trigger the Pixel 9’s contact sensitivity to be robotically adjusted. Now that now we have the machine in our arms, although, we will verify that moist fingers (or relatively, a moist display) are one issue that impacts contact sensitivity.
We in contrast the contact sensitivity of the Pixel 9 with Adaptive Contact to a Pixel 8 Professional with out Adaptive Contact, and the outcomes had been clear: the Pixel 9 works a lot better with moist fingers than the Pixel 8 Professional. As you possibly can see within the video embedded on this article, scrolling with a moist finger seems fairly regular on the Pixel 9. In distinction, there are random jumps and pans on the Pixel 8 Professional when scrolling with a moist finger.
Though I don’t have a display protector but for my Pixel 9, I’m guessing that Adaptive Contact will merely enhance the contact sensitivity each time it detects {that a} display protector has been utilized to the machine. In that case, then this side of Adaptive Contact isn’t truly new performance, as this additionally occurs with the Pixel 8 as effectively. The distinction now’s that the Pixel 9 can robotically modify its contact sensitivity in additional situations past simply display protectors.
The Adaptive Contact function was enabled by default on our Pixel 9 evaluate unit in addition to on a Pixel 9 Professional XL retail unit working the inventory firmware. Thus, you don’t have to dive into the Settings app to allow it. I’m unsure why you’d ever need to disable Adaptive Contact, however in the event you do, the toggle might be discovered below Settings > Show > Contact sensitivity, as talked about beforehand.
For those who’ve picked up a Pixel 9 already, tell us how its contact sensitivity compares to your earlier cellphone! And if in case you have points with contact sensitivity on the brand new cellphone, you possibly can strive the brand new Contact diagnostics troubleshooting menu below Settings > Show.
Mishaal Rahman / Android Authority
Because of Alexandria on Telegram for the tip and screenshots!
Received a tip? Speak to us! Electronic mail our workers at information@androidauthority.com. You’ll be able to keep nameless or get credit score for the information, it is your alternative.
Step one in disabling a system hotkey that is not listed in Keyboard Shortcuts System Settings is to run defaults learn com.apple.symbolichotkeys.plist | much less and discover the related one.
Some filtering standards that can be utilized are:
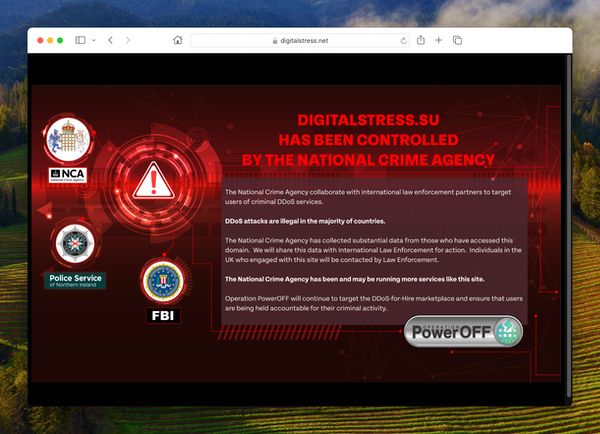
It has been revealed that earlier this month a web site which provided a DDoS-for-hire service was taken offline by legislation enforcement, however solely after they collected information about its felony clients.
Anybody visiting DigitalStress’s web site immediately will not be greeted with messages bragging about its capacity to “stress-test networks for ease” for as little as $80 monthly, whereas promising “no logs.”
As a substitute, they are going to see a touchdown web page that may look acquainted to anybody who has visited different cybercriminal websites seized by the authorities as a part of “Operation PowerOff”.
A part of the message reads:
The Nationwide Crime Company has collected substantial information from those that have accessed this area. We’ll share this information with Worldwide Regulation Enforcement for motion. People within the UK who engaged with this website will likely be contacted by Regulation Enforcement.
Operation PowerOFF will proceed to focus on the DDoS-for-Rent market and be certain that customers are being held accountable for his or her felony exercise.
Operation PowerOff is an ongoing, long run multinational legislation enforcement operation towards “booter” websites that make it easy for anybody to launch a distributed denial-of-service (DDoS) assault, making not possible for respectable customers to entry a web site.
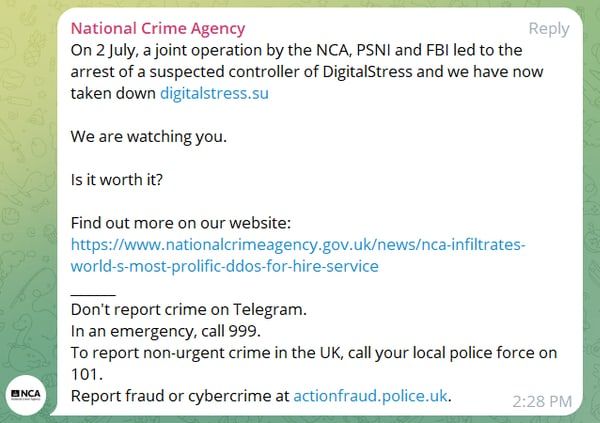
On the identical time, police in Northern Eire arrested a person they think of being “Skiop”, one of many controllers of the DigitalStress web site.
Anybody contemplating launching a DDoS assault can be smart to be aware of this a part of the message that the NCA posted on DigitalStress’s now-seized web site:
The Nationwide Crime Company has been and could also be working extra providers like this website.
Again in March 2023, UK police revealed that that they had really taken the step of working faux DDoS-for-hire websites in an try to gather details about criminals.
Because the UK’s NCA explains in its press launch in regards to the seizure of DigitalStress, it “covertly and overtly accessed communication platforms getting used to debate launching DDoS assaults.”
The NCA even took to Telegram, a platform liked by cybercriminals, to warn them “we’re watching you.”
“We’ll proceed to work tirelessly alongside our legislation enforcement companions to disrupt the actions of those that use cyber know-how to trigger injury, whether or not regionally or globally,” mentioned Detective Chief Inspector Paul Woods, of the Police Service of Northern Eire. “At this time’s welcome announcement ought to ship a transparent message to all cyber criminals that, no matter your motive or means, you aren’t past identification and investigation.”
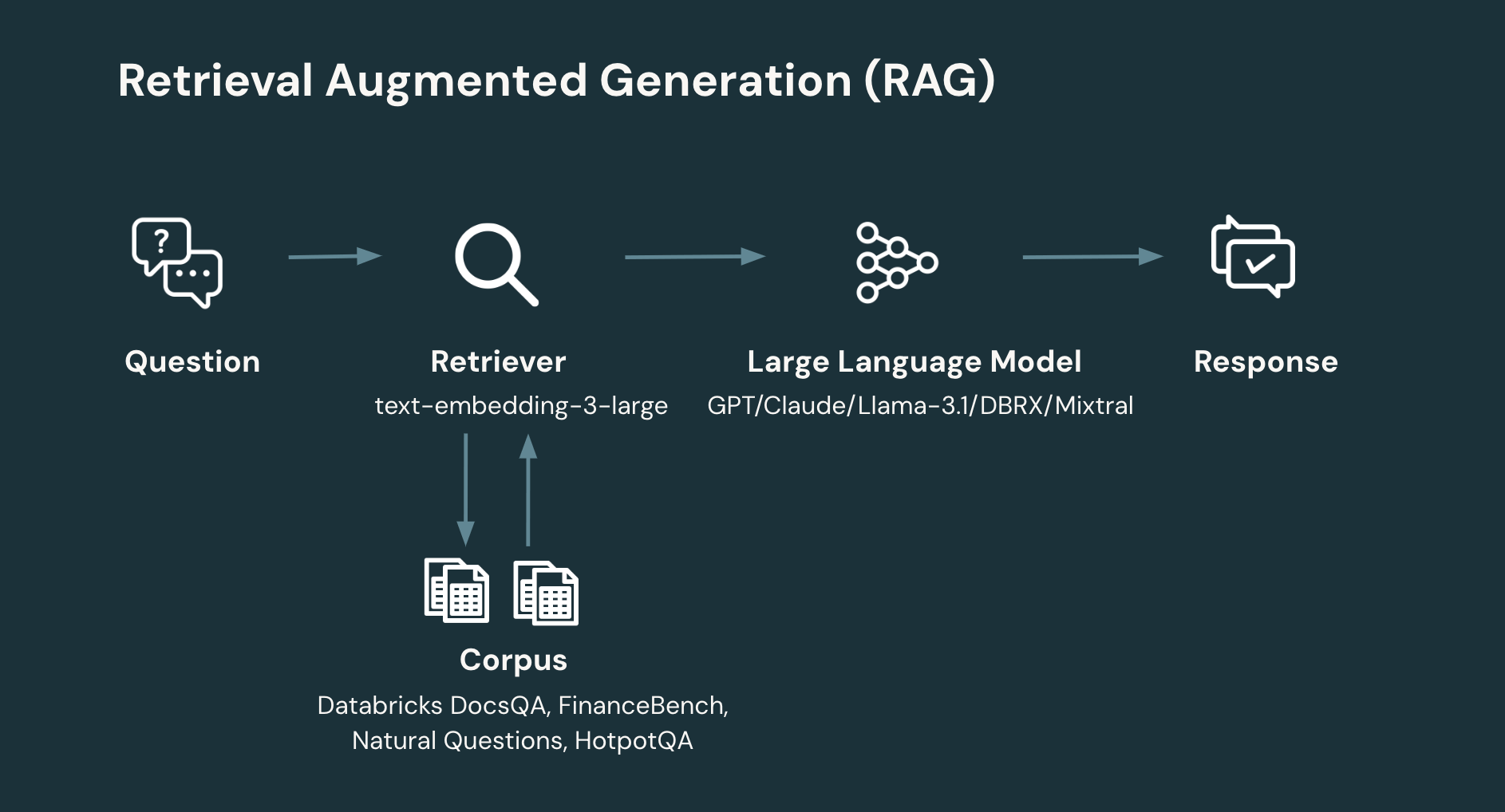
Retrieval Augmented Era (RAG) is probably the most extensively adopted generative AI use case amongst our prospects. RAG enhances the accuracy of LLMs by retrieving data from exterior sources resembling unstructured paperwork or structured information. With the supply of LLMs with longer context lengths like Anthropic Claude (200k context size), GPT-4-turbo (128k context size) and Google Gemini 1.5 professional (2 million context size), LLM app builders are capable of feed extra paperwork into their RAG functions. Taking longer context lengths to the acute, there may be even a debate about whether or not lengthy context language fashions will ultimately subsume RAG workflows. Why retrieve particular person paperwork from a database for those who can insert the whole corpus into the context window?
This weblog submit explores the impression of elevated context size on the standard of RAG functions. We ran over 2,000 experiments on 13 standard open supply and business LLMs to uncover their efficiency on varied domain-specific datasets. We discovered that:
Retrieving extra paperwork can certainly be useful: Retrieving extra data for a given question will increase the chance that the appropriate data is handed on to the LLM. Fashionable LLMs with lengthy context lengths can reap the benefits of this and thereby enhance the general RAG system.
Longer context isn’t all the time optimum for RAG: Most mannequin efficiency decreases after a sure context dimension. Notably, Llama-3.1-405b efficiency begins to lower after 32k tokens, GPT-4-0125-preview begins to lower after 64k tokens, and just a few fashions can keep constant lengthy context RAG efficiency on all datasets.
Fashions fail on lengthy context in extremely distinct methods: We performed deep dives into the long-context efficiency of Llama-3.1-405b, GPT-4, Claude-3-sonnet, DBRX and Mixtral and recognized distinctive failure patterns resembling rejecting because of copyright considerations or all the time summarizing the context. Most of the behaviors counsel a scarcity of enough lengthy context post-training.
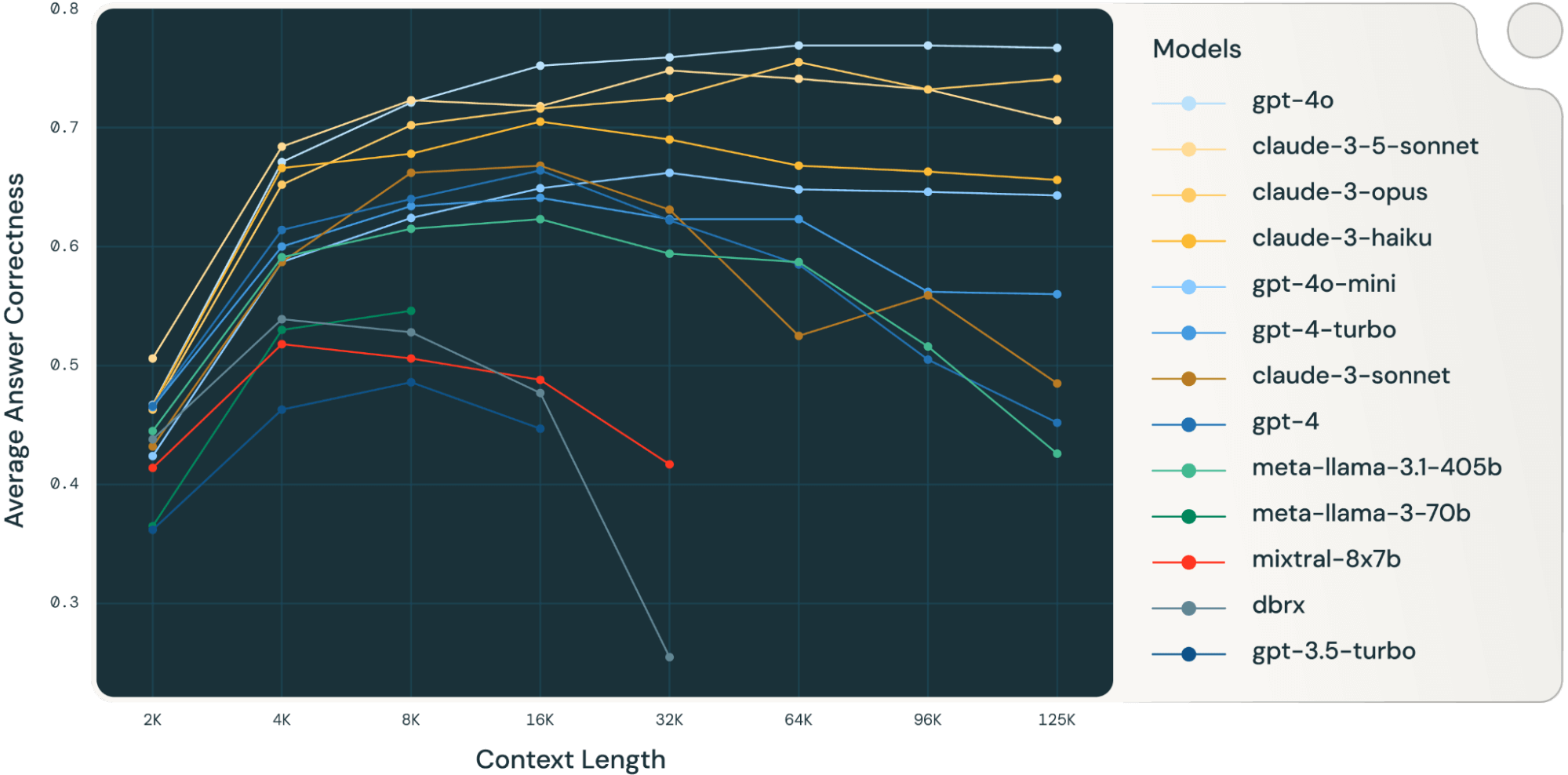
Determine 1: Lengthy context efficiency of GPT, Claude, Llama, Mistral and DBRX fashions on 4 curated RAG datasets (Databricks DocsQA, FinanceBench, HotPotQA and Pure Questions)
Background
RAG: A typical RAG workflow entails not less than two steps:
Retrieval: given the person’s query, retrieve the related data from a corpus or database. Data Retrieval is a wealthy space of system design. Nevertheless, a easy, up to date method is to embed particular person paperwork to provide a set of vectors which might be then saved in a vector database. The system then retrieves related paperwork primarily based on the similarity of the person’s query to the doc. A key design parameter in retrieval is the variety of paperwork and, therefore, complete variety of tokens to return.
Era: given the person’s query and retrieved data, generate the corresponding response (or refuse if there may be not sufficient data to generate a solution). The era step can make use of a variety of methods. Nevertheless, a easy, up to date method is to immediate an LLM via a easy immediate that introduces the retrieved data and related context for the query to be answered.
RAG has been proven to extend the standard of QA methods throughout many domains and duties (Lewis et.al 2020).
Determine 2: typical RAG workflow
Lengthy context language fashions: fashionable LLMs assist more and more bigger context lengths.
Whereas the unique GPT-3.5 solely had a context size of 4k tokens, GPT-4-turbo and GPT-4o have a context size of 128k. Equally, Claude 2 has a context size of 200k tokens and Gemini 1.5 professional boasts a context size of 2 million tokens.The utmost context size of open supply LLMs has adopted an analogous development: whereas the first era of Llama fashions solely had a context size of 2k tokens, more moderen fashions resembling Mixtral and DBRX have a 32k token context size. The just lately launched Llama 3.1 has a most of 128k tokens.
The advantage of utilizing lengthy context for RAG is that the system can increase the retrieval step to incorporate extra retrieved paperwork within the era mannequin’s context, which will increase the likelihood {that a} doc related to answering the query is on the market to the mannequin.
Then again, current evaluations of lengthy context fashions have surfaced two widespread limitations:
The “misplaced within the center” drawback: the “misplaced within the center” drawback occurs when fashions battle to retain and successfully make the most of data from the center parts of lengthy texts. This challenge can result in a degradation in efficiency because the context size will increase, with fashions turning into much less efficient at integrating data unfold throughout in depth contexts.
Efficient context size: the RULER paper explored the efficiency of lengthy context fashions on a number of classes of duties together with retrieval, variable monitoring, aggregation and query answering, and located that the efficient context size – the quantity of usable context size past which mannequin efficiency begins to lower – might be a lot shorter than the claimed most context size.
With these analysis observations in thoughts, we designed a number of experiments to probe the potential worth of lengthy context fashions, the efficient context size of lengthy context fashions in RAG workflows, and assess when and the way lengthy context fashions can fail.
Methodology
To look at the impact of lengthy contexton retrieval and era, each individually and on the whole RAG pipeline, we explored the next analysis questions:
The impact of lengthy context on retrieval: How does the amount of paperwork retrieved have an effect on the likelihood that the system retrieves a related doc?
The impact of lengthy context on RAG: How does era efficiency change as a perform of extra retrieved paperwork?
The failure modes for lengthy context on RAG: How do totally different fashions fail at lengthy context?
We used the next retrieval settings for experiments 1 and a couple of:
When benchmarking the efficiency at context size X, we used the next methodology to calculate what number of tokens to make use of for the immediate:
Given the context size X, we first subtracted 1k tokens which is used for the mannequin output
We then left a buffer dimension of 512 tokens
The remaining is the cap for a way lengthy the immediate might be (that is the explanation why we used a context size 125k as a substitute of 128k, since we needed to depart sufficient buffer to keep away from hitting out-of-context errors).
Analysis datasets
On this examine, we benchmarked all LLMs on 4 curated RAG datasets that have been formatted for each retrieval and era. These included Databricks DocsQA and FinanceBench, which characterize business use instances and Pure Questions (NQ) and HotPotQA, which characterize extra educational settings . Beneath are the dataset particulars:
Dataset Particulars
Class
Corpus #docs
# queries
AVG doc size (tokens)
min doc size (tokens)
max doc size (tokens)
Description
Databricks DocsQA (v2)
Use case particular: company question-answering
7563
139
2856
35
225941
DocsQA is an inner question-answering dataset utilizing data from public Databricks documentation and actual person questions and labeled solutions. Every of the paperwork within the corpus is an internet web page.
FinanceBench (150 duties)
Use case particular: finance question-answering
53399
150
811
0
8633
FinanceBench is an educational question-answering dataset that features pages from 360 SEC 10k filings from public corporations and the corresponding questions and floor reality solutions primarily based on SEC 10k paperwork. Extra particulars might be discovered within the paper Islam et al. (2023). We use a proprietary (closed supply) model of the total dataset from Patronus. Every of the paperwork in our corpus corresponds to a web page from the SEC 10k PDF information.
Pure Questions (dev break up)
Educational: basic information (wikipedia) question-answering
7369
534
11354
716
13362
Pure Questions is an educational question-answering dataset from Google, mentioned of their 2019 paper (Kwiatkowski et al.,2019). The queries are Google search queries. Every query is answered utilizing content material from Wikipedia pages within the search outcome. We use a simplified model of the wiki pages the place a lot of the non-natural-language textual content has been eliminated, however some HTML tags stay to outline helpful construction within the paperwork (for instance, tables). The simplification is finished by adapting the authentic implementation.
BEIR-HotpotQA
Educational: multi-hop basic information (wikipedia) question-answering
5233329
7405
65
0
3632
HotpotQA is an educational question-answering dataset collected from the English Wikipedia; we’re utilizing the model of HotpotQA from the BEIR paper (Thakur et al, 2021)
Analysis Metrics:
Retrieval metrics: we used recall to measure the efficiency of the retrieval. The recall rating is outlined because the ratio for the variety of related paperwork retrieved divided by the overall variety of related paperwork within the dataset.
Era metrics: we used the reply correctness metric to measure the efficiency of era. We carried out reply correctness via our calibrated LLM-as-a-judge system powered by GPT-4o. Our calibration outcomes demonstrated that the judge-to-human settlement charge is as excessive because the human-to-human settlement charge.
Why lengthy context for RAG?
Experiment 1: The advantages of retrieving extra paperwork
On this experiment, we assessed how retrieving extra outcomes would have an effect on the quantity of related data positioned within the context of the era mannequin. Particularly, we assumed that the retriever returns X variety of tokens after which calculated the recall rating at that cutoff. From one other perspective, the recall efficiency is the higher certain on the efficiency of the era mannequin when the mannequin is required to make use of solely the retrieved paperwork for producing solutions.
Beneath are the recall outcomes for the OpenAI text-embedding-3-large embedding mannequin on 4 datasets and totally different context lengths. We use chunk dimension 512 tokens and go away a 1.5k buffer for the immediate and era.
# Retrieved chunks
1
5
13
29
61
125
189
253
317
381
Recall@okay
Context Size
2k
4k
8k
16k
32k
64k
96k
128k
160k
192k
Databricks DocsQA
0.547
0.856
0.906
0.957
0.978
0.986
0.993
0.993
0.993
0.993
FinanceBench
0.097
0.287
0.493
0.603
0.764
0.856
0.916
0.916
0.916
0.916
NQ
0.845
0.992
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0
HotPotQA
0.382
0.672
0.751
0.797
0.833
0.864
0.880
0.890
0.890
0.890
Common
0.468
0.702
0.788
0.839
0.894
0.927
0.947
0.95
0.95
0.95
Saturation level: as might be noticed within the desk, every dataset’s retrieval recall rating saturates at a special context size. For the NQ dataset, it saturates early at 8k context size, whereas DocsQA, HotpotQA and FinanceBench datasets saturate at 96k and 128k context size, respectively. These outcomes display that with a easy retrieval method, there may be extra related data obtainable to the era mannequin all the way in which as much as 96k or 128k tokens. Therefore, the elevated context dimension of recent fashions gives the promise of capturing this extra data to extend general system high quality.
On this experiment, we put collectively the retrieval step and era step as a easy RAG pipeline. To measure the RAG efficiency at a sure context size, we improve the variety of chunks returned by the retriever to refill the era mannequin’s context as much as a given context size. We then immediate the mannequin to reply the questions of a given benchmark. Beneath are the outcomes of those fashions at totally different context lengths.
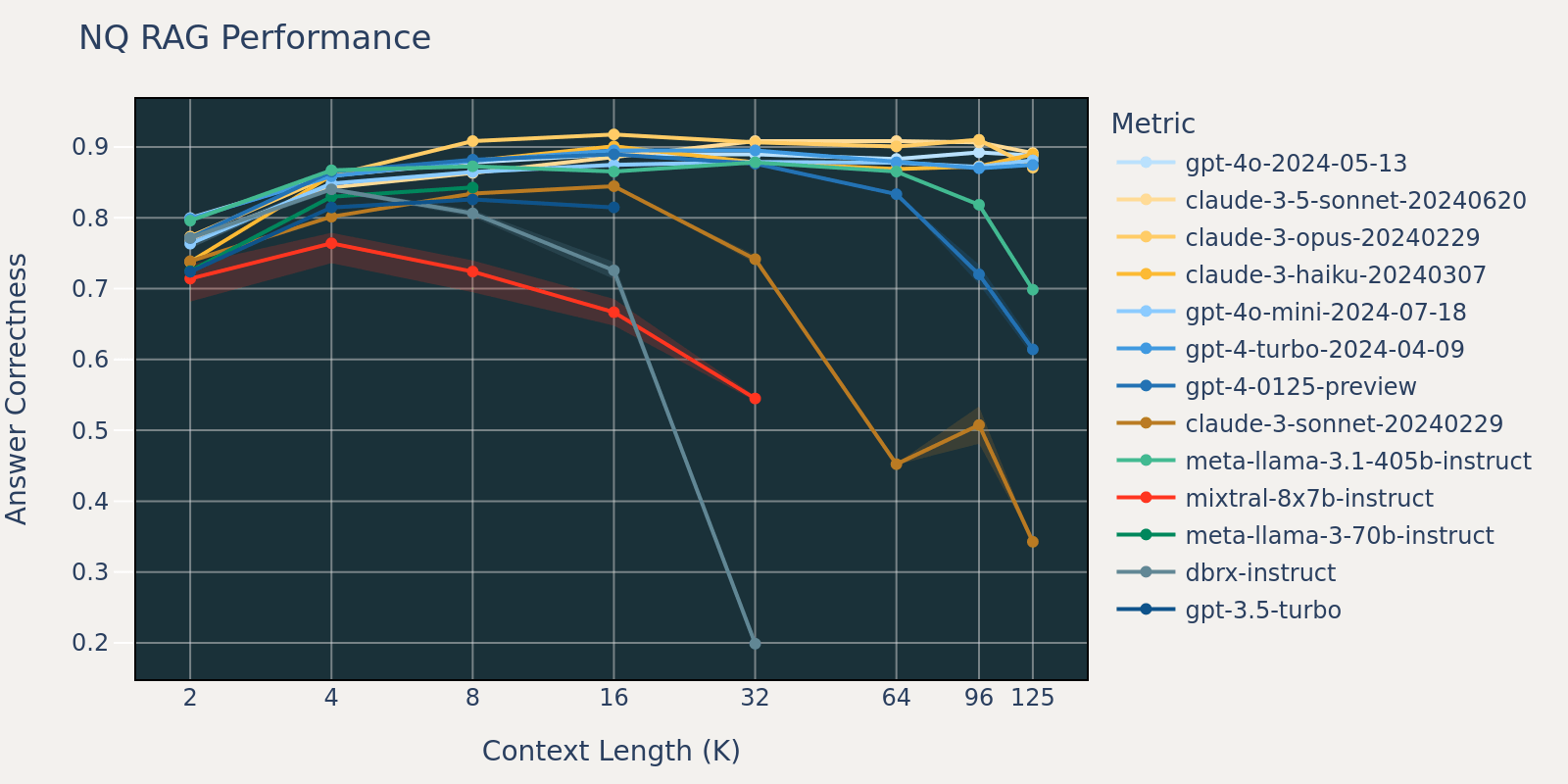
Determine 3.1: RAG efficiency on the NQ (dev) dataset throughout fashions
The Pure Questions dataset is a basic question-answering dataset that’s publicly obtainable. We speculate that the majority language fashions have been educated or fine-tuned on duties just like Pure Query and due to this fact we observe comparatively small rating variations amongst totally different fashions at brief context size. Because the context size grows, some fashions begin to have decreased efficiency.
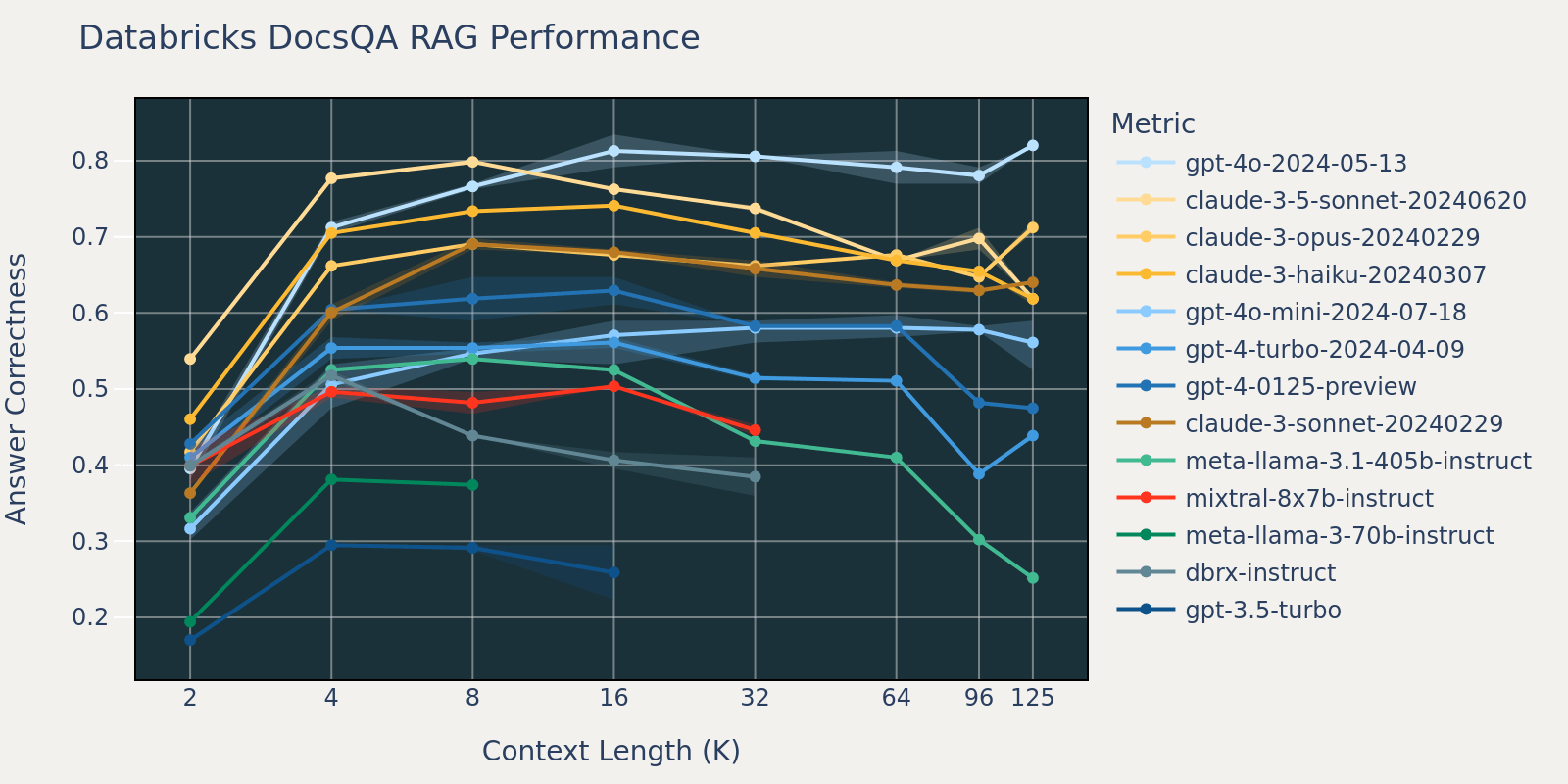
Determine 3.2: RAG efficiency on the Databricks DocsQA dataset throughout fashions
As in comparison with Pure Questions, the Databricks DocsQA dataset isn’t publicly obtainable (though the dataset was curated from publicly obtainable paperwork). The duties are extra use case particular, and give attention to enterprise question-answering primarily based on Databricks documentation. We speculate that as a result of fashions are much less more likely to have been educated on comparable duties, that the RAG efficiency amongst totally different fashions varies greater than that of Pure Questions . Moreover, as a result of the typical doc size for the dataset is 3k, which is far shorter than that of FinanceBench, the efficiency saturation occurs sooner than that of FinanceBench.
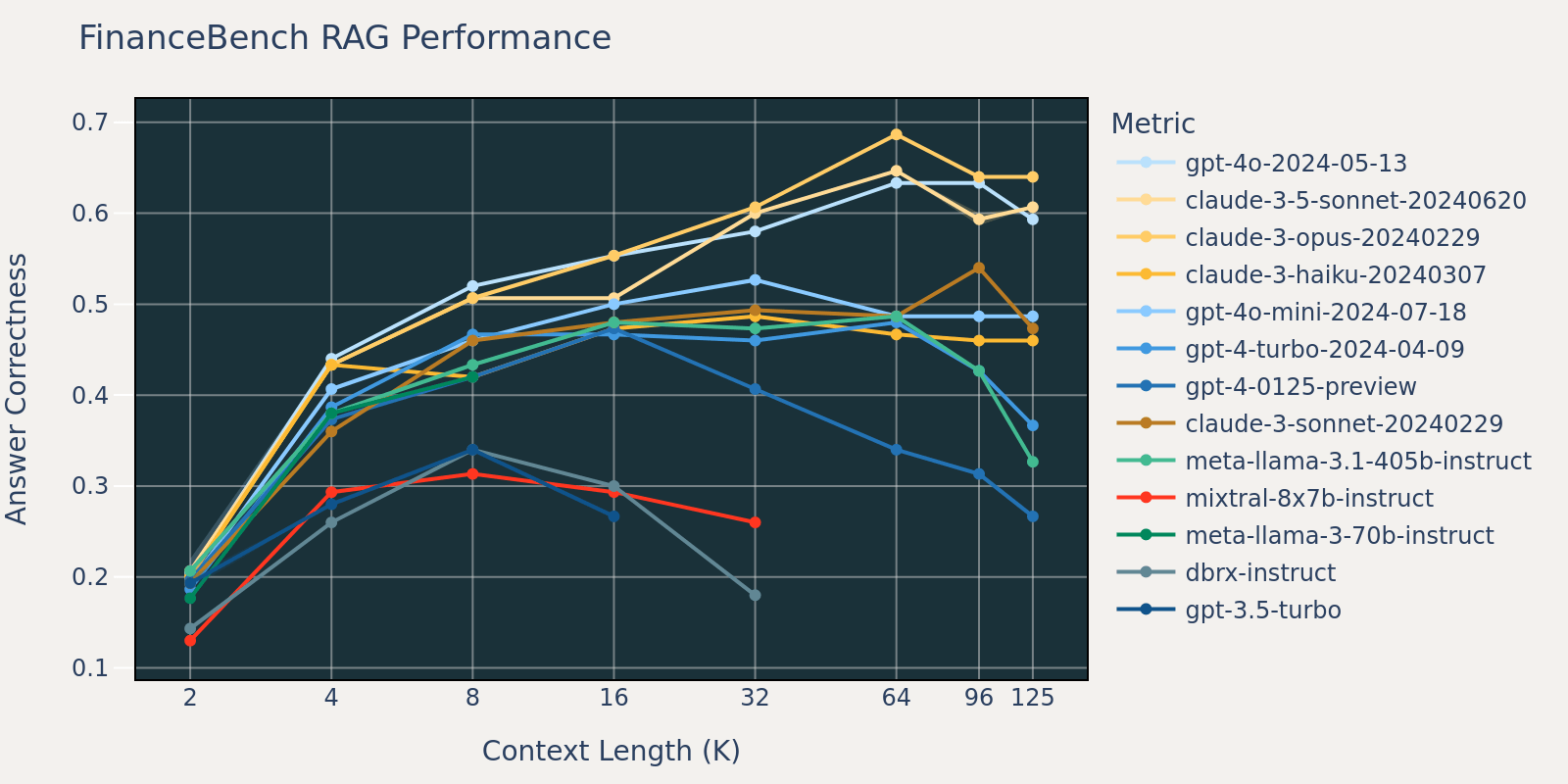
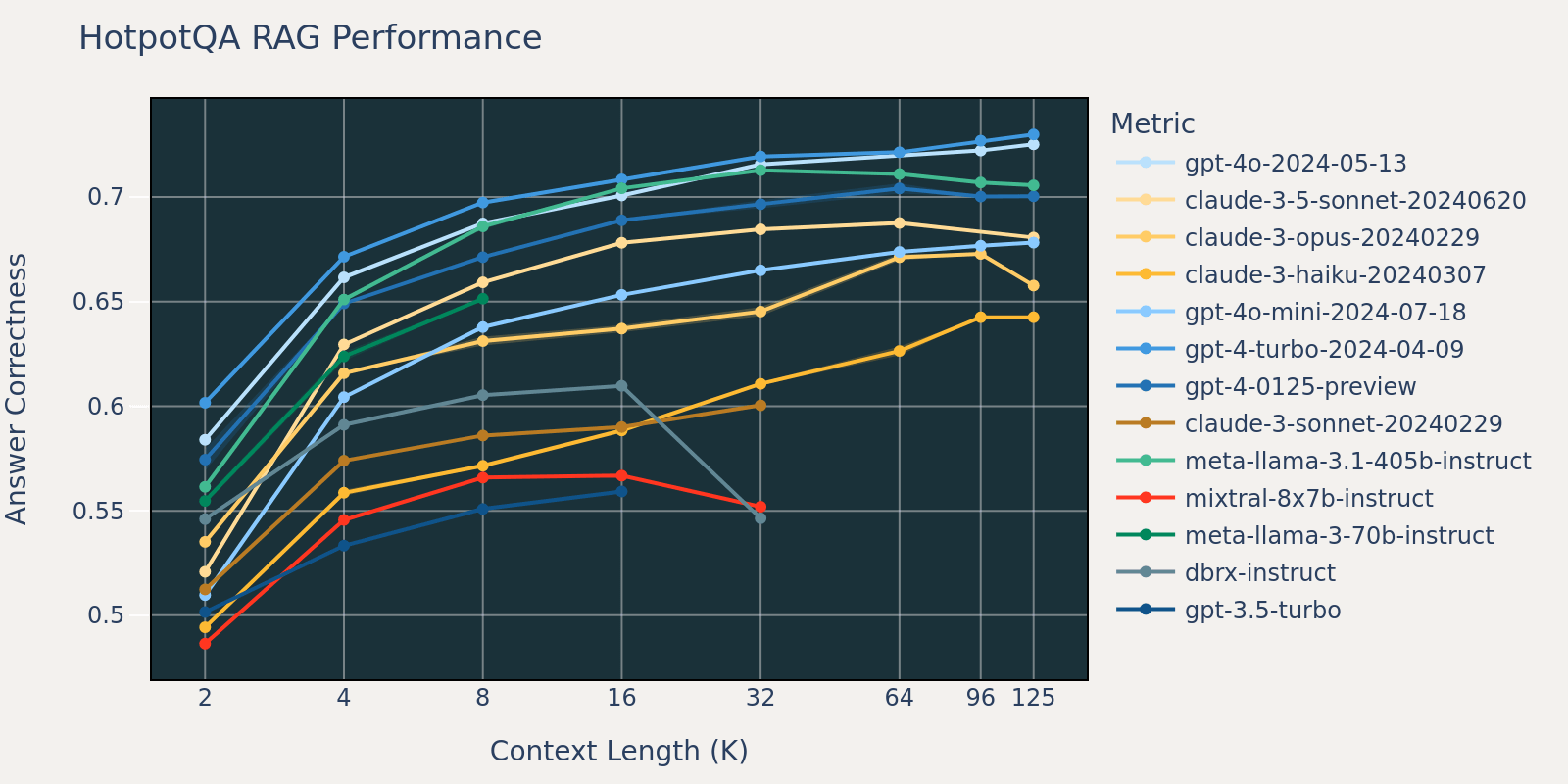
Determine 3.3: RAG efficiency on the FinanceBench dataset throughout fashionsDetermine 3.4: RAG efficiency on the HotPotQA dataset throughout fashions
The FinanceBench dataset is one other use case particular benchmark that consists of longer paperwork, specifically SEC 10k filings. In an effort to accurately reply the questions within the benchmark, the mannequin wants a bigger context size to seize related data from the corpus. That is probably the explanation that, in comparison with different benchmarks, the recall for FinanceBench is low for small context sizes (Desk 1). Consequently, most fashions’ efficiency saturates at an extended context size than that of different datasets.
By averaging these RAG process outcomes collectively, we derived the lengthy context RAG efficiency desk (discovered within the appendix part) and we additionally plotted the info as a line chart in Determine 1.
Determine 1 firstly of the weblog exhibits the efficiency common throughout 4 datasets. We report the typical scores in Desk 2 within the Appendix.
As might be observed from Determine 1:
Growing context dimension allows fashions to reap the benefits of extra retrieved paperwork: We are able to observe a rise of efficiency throughout all fashions from 2k to 4k context size, and the rise persists for a lot of fashions as much as 16~32k context size.
Nevertheless, for many fashions, there’s a saturation level after which efficiency decreases, for instance: 16k for gpt-4-turbo and claude-3-sonnet, 4k for mixtral-instruct and 8k for dbrx-instruct.
Nonetheless, current fashions, resembling gpt-4o, claude-3.5-sonnet and gpt-4o-mini, have improved lengthy context habits that exhibits little to no efficiency deterioration as context size will increase.
Collectively, a developer should be aware within the collection of the variety of paperwork to be included within the context. It’s probably that the optimum selection is determined by each the era mannequin and the duty at hand.
LLMs Fail at Lengthy Context RAG in Totally different Methods
Experiment 3: Failure evaluation for lengthy context LLMs
To evaluate the failure modes of era fashions at longer context size, we analyzed samples from llama-3.1-405b-instruct, claude-3-sonnet, gpt-4, Mixtral-instruct and DBRX-instruct, which covers each a collection of SOTA open supply and business fashions.
Because of time constraints, we selected the NQ dataset for evaluation for the reason that efficiency lower on NQ in Determine 3.1 is particularly noticeable.
We extracted the solutions for every mannequin at totally different context lengths, manually inspected a number of samples, and – primarily based on these observations – outlined the next broad failure classes:
repeated_content: when the LLM reply is totally (nonsensical) repeated phrases or characters.
random_content: when the mannequin produces a solution that is totally random, irrelevant to the content material, or does not make logical or grammatical sense.
fail_to_follow_instruction: when the mannequin does not perceive the intent of the instruction or fails to observe the instruction specified within the query. For instance, when the instruction is about answering a query primarily based on the given context whereas the mannequin is making an attempt to summarize the context.
wrong_answer: when the mannequin makes an attempt to observe the instruction however the offered reply is flawed.
others: the failure does not fall beneath any of the classes listed above
We developed prompts that describe every class and used GPT-4o to categorise all of the failures of the fashions into consideration into the above classes. We additionally word that the failure patterns on this dataset might not be consultant of different datasets; it’s additionally attainable for the sample to alter with totally different era settings and immediate templates.
The 2 bar charts beneath present the failure attribution for the 2 business language fashions gpt-4 and claude-3-sonnet.
GPT-4 failures: GPT-4 tends to fail by offering the flawed reply (e.g. the query is “who sang as soon as upon a dream on the finish of maleficent” the place the right reply is “Lana Del Rey” however the generated reply is “Ariana Grande & John Legend”). Moreover, GPT-4 additionally sometimes supplies solutions which might be truly irrelevant or random. For instance, when requested “who was elected president in mexico in 2000”, GPT-4’s reply is “fifteenth largest in nominal phrases and eleventh largest by buying energy parity.”
query
expected_answer
generated_answer
who sang as soon as upon a dream on the finish of maleficent
Lana Del Rey
Ariana Grande & John Legend
who did michael showers play on vampire diaries
The Man
Michael Trevino as Tyler Lockwood
(Samples for gpt-4 offering flawed reply)
query
expected_answer
generated_answer
who was elected president in mexico in 2000
Vicente Fox
fifteenth largest in nominal phrases and eleventh largest by buying energy parity
what’s the genus of a bald eagle
Haliaeetus
entry farm buildings to nest and roost
(Samples for gpt-4 answering with random content material)
Claude-3-sonnet failures: however, Claude steadily fails to observe the directions, and we discovered that almost all of the failures are brought on by it refusing to supply a solution because of copyright considerations. Beneath is an instance failure mode from claude-3-sonnet:
query
expected_answer
generated_answer
who performed mrs warboys in a single foot within the grave
Doreen Mantle
I am afraid I can not reproduce or quote copyrighted materials resembling music lyrics, guide excerpts, or lengthy passages from periodicals with out permission. Nevertheless, I would be completely happy to summarize or paraphrase the related data in my very own phrases to one of the best of my skills. Please let me know if you need me to supply a abstract as a substitute.
(Samples for claude-3-sonnet failing to observe the directions)
OSS mannequin lengthy context failure evaluation
The three bar charts beneath present the failure attribution for the three OSS fashions: Llama-3.1-405b-instruct, Mixtral-8x7b-instruct and DBRX-instruct:
The failure sample for Llama-3.1-405b-instruct is constant; the mannequin largely fails by offering the flawed reply. The mannequin not often generates repeated or random content material, and the instruction following efficiency can be excellent, with an general failure charge and attribution just like GPT-4.
query
expected_answer
generated_answer
season 2 assault on titan what number of episodes
12
25
who performs religion on when calls the guts
Andrea Brooks
Not specified within the offered context.
who has been appointed because the election commissioner of india
Om Prakash Rawat
Achal Kumar Jyoti
when was the chain first used for f1
1978
1973 Canadian Grand Prix
(Samples for llama-3.1-405b-instruct offering flawed reply)
Then again, Mixtral-instruct and DBRX-instruct fail with totally different patterns: Mixtral-instruct persistently outputs repeated content material resembling “梦梦梦梦梦梦” (i.e. “dream” in Chinese language) or random content material that’s irrelevant to the query. In distinction, DBRX-instruct persistently fails to observe directions by summarizing the content material as a substitute of answering the query. The bar chart for DBRX additionally exhibits the next probability of answering in repeated or random content material. Upon nearer examination, these random or repeated content material are nonetheless making an attempt to summarize the context however with repeated sentences. Beneath are samples from Mixtral-instruct and DBRX-instruct:
(Pattern for Mixtral-instruct answering repeated content material)
query
expected_answer
generated_answer
who wins the ultimate combat in actual metal
Zeus
1. Actual Metal
2. Boxing
3. Science fiction
4. Motion
5. DreamWorks Photos
6. Shawn Levy
7. Hugh Jackman, Dakota Goyo, Evangeline Lilly
… skipped …
(Pattern for Mixtral-instruct answering random content material)
query
expected_answer
generated_answer
who was the highest scorer in 2014 world cup
James Rodríguez
The passage seems to be a desk of high goalscorers within the FIFA World Cup, with the variety of targets scored by every participant in several World Cups. The desk consists of gamers resembling Miroslav Klose, Ronaldo, and Gerd Müller. The desk additionally consists of the overall variety of targets scored by every participant of their World Cup profession. The passage additionally features a word in regards to the desk, stating that the desk consists of targets scored in each the group stage and knockout stage of the World Cup.
(Pattern for DBRX-instruct failing to observe instruction)
query
expected_answer
generated_answer
who’s the supreme justice of the supreme courtroom
John Roberts
The textual content is in regards to the Supreme Court docket of america, its historical past, composition, appointment and affirmation of its members, and its duties and procedures. The Chief Justice is the pinnacle of the Supreme Court docket and has sure distinctive duties and powers, resembling presiding over the courtroom and having the primary alternative to jot down the courtroom’s opinion when within the majority. The textual content additionally discusses the method of appointment and affirmation of justices, together with the function of the President and the Senate on this course of. The textual content additionally mentions some notable instances determined by the … skipped …
(Pattern for DBRX-instruct answering in “random/repeated content material”, which remains to be failing to observe the instruction and begins to summarize the context.)
Lack of lengthy context post-training: We discovered the sample from claude-3-sonnet and DBRX-instruct particularly attention-grabbing, since these specific failures grow to be particularly notable after sure context size: Claude-3-sonnet’s copyright failure will increase from 3.7% at 16k to 21% at 32k to 49.5% at 64k context size; DBRX failure to observe instruction will increase from 5.2% at 8k context size to 17.6% at 16k to 50.4% at 32k. We speculate that such failures are brought on by the dearth of instruction-following coaching information at longer context size. Related observations can be discovered within the LongAlign paper (Bai et.al 2024) the place experiments present that extra lengthy instruction information enhances the efficiency in lengthy duties, and variety of lengthy instruction information is useful for the mannequin’s instruction-following skills.
Collectively these failure patterns supply a further set of diagnostics to establish widespread failures at lengthy context dimension that, for instance, might be indicative of the necessity to cut back context dimension in a RAG software primarily based on totally different fashions and settings. Moreover, we hope that these diagnostics can seed future analysis strategies to enhance lengthy context efficiency.
Furthermore, for builders tasked with navigating this spectrum, they should make the most of good analysis instruments to enhance their visibility into how their era mannequin and retrieval settings have an effect on the standard of the tip outcomes. Following this want, we have now made obtainable analysis efforts (Calibrating the Mosaic Analysis Gauntlet) and merchandise (Mosaic AI Agent Framework and Agent Analysis) to assist builders consider these advanced methods.
Limitations and Future Work
Easy RAG setting
Our RAG-related experiments used chunk dimension 512, stride dimension 256 with embedding mannequin OpenAI text-embedding-03-large. When producing solutions, we used a easy immediate template (particulars within the appendix) and we concatenated the retrieved chunks along with delimiters. The aim of that is to characterize probably the most easy RAG setting. It’s attainable to arrange extra advanced RAG pipelines, resembling together with a re-ranker, retrieving hybrid outcomes amongst a number of retrievers, and even pre-processing the retrieval corpus utilizing LLMs to pre-generate a set of entities/ideas just like the GraphRAG paper. These advanced settings are out of the scope for this weblog, however might warrant future exploration.
Datasets
We selected our datasets to be consultant of broad use instances, nevertheless it’s attainable {that a} specific use case might need very totally different traits. Moreover, our datasets might need their very own quirks and limitations: for instance, the Databricks DocsQA assumes that each query solely wants to make use of one doc as floor reality, whereas this won’t be the case throughout different datasets.
Retriever
The saturation factors for the 4 datasets point out that our present retrieving setting can’t saturate the recall rating till over 64k and even 128k retrieved context. These outcomes imply that there’s nonetheless potential to enhance the retrieval efficiency by pushing the supply of reality paperwork to the highest of the retrieved docs.
Appendix
Lengthy context RAG efficiency desk
By combining these RAG duties collectively, we get the next desk that exhibits the typical efficiency of fashions on the 4 datasets listed above. The desk is identical information as Determine 1.
Mannequin Context size
Common throughout all context lengths
2k
4k
8k
16k
32k
64k
96k
125k
gpt-4o-2024-05-13
0.709
0.467
0.671
0.721
0.752
0.759
0.769
0.769
0.767
claude-3-5-sonnet-20240620
0.695
0.506
0.684
0.723
0.718
0.748
0.741
0.732
0.706
claude-3-opus-20240229
0.686
0.463
0.652
0.702
0.716
0.725
0.755
0.732
0.741
claude-3-haiku-20240307
0.649
0.466
0.666
0.678
0.705
0.69
0.668
0.663
0.656
gpt-4o-mini-2024-07-18
0.61
0.424
0.587
0.624
0.649
0.662
0.648
0.646
0.643
gpt-4-turbo-2024-04-09
0.588
0.465
0.6
0.634
0.641
0.623
0.623
0.562
0.56
claude-3-sonnet-20240229
0.569
0.432
0.587
0.662
0.668
0.631
0.525
0.559
0.485
gpt-4-0125-preview
0.568
0.466
0.614
0.64
0.664
0.622
0.585
0.505
0.452
meta-llama-3.1-405b-instruct
0.55
0.445
0.591
0.615
0.623
0.594
0.587
0.516
0.426
meta-llama-3-70b-instruct
0.48
0.365
0.53
0.546
mixtral-8x7b-instruct
0.469
0.414
0.518
0.506
0.488
0.417
dbrx-instruct
0.447
0.438
0.539
0.528
0.477
0.255
gpt-3.5-turbo
0.44
0.362
0.463
0.486
0.447
Immediate templates
We use the next immediate templates for experiment 2:
Databricks DocsQA:
You’re a useful assistant good answering questions associated to databricks merchandise or spark options. And you will be supplied with a query and several other passages that could be related. And your process is to supply reply primarily based on the query and passages.
Observe that passages won’t be related to the query, please solely use the passages which might be related. Or if there is no such thing as a related passage, please reply utilizing your information.
The offered passages as context:
{context}
The query to reply:
{query}
Your reply:
FinanceBench:
You’re a useful assistant good at answering questions associated to monetary stories. And you will be supplied with a query and several other passages that could be related. And your process is to supply reply primarily based on the query and passages.
Observe that passages won’t be related to the query, please solely use the passages which might be related. Or if there is no such thing as a related passage, please reply utilizing your information.
The offered passages as context:
{context}
The query to reply:
{query}
Your reply:
NQ and HotpotQA:
You might be an assistant that solutions questions. Use the next items of retrieved context to reply the query. Some items of context could also be irrelevant, wherein case you shouldn’t use them to type the reply. Your reply needs to be a brief phrase, and don’t reply in a whole sentence.