Cellular apps have turn into the primary alternative for customers for his or her on-line actions in banking, e-commerce, media streaming, social media, and so on. More and more, cellular apps on smartphones ‘discuss’ to one another.
Based on a current research, assaults on APIs have elevated by 117% yearly. Even a single consumer information breach or just a few hours of downtime can impression a enterprise to hundreds of thousands of {dollars}. Companies can now not afford to permit the safety of their cellular APIs to take a backseat.
There are presently two main courses of GPU architectures: Rapid-Mode Rendering (IMR) and Tile-Primarily based Rendering (TBR).
The IMR structure is older, considerably less complicated and extra forgiving to inefficiently written purposes, however it’s energy hungry. Usually present in desktop GPU playing cards, this structure is thought to supply excessive efficiency whereas consuming a whole bunch of watts of energy.
The TBR structure alternatively might be very power environment friendly, as it could actually reduce entry to RAM as a serious supply of power attract typical rendering. Usually present in cell and battery-powered units, these GPUs may devour as little as single digit watts of energy. Nonetheless, this structure’s efficiency closely will depend on appropriate software utilization.
Compared with IMR GPUs, TBR GPUs have some benefits (akin to environment friendly multisampling) and drawbacks (akin to inefficient geometry and tessellation shaders). For extra info, see this weblog submit. Some GPU distributors produce hybrid architectures, and a few handle to devour little energy with IMR {hardware} on cell units, however in most GPU architectures utilized in cell units, it’s the TBR options that make low energy consumption doable.
On this submit, I’ll clarify one of the vital essential options of TBR {hardware}, how it may be most effectively used, how Vulkan makes it very straightforward to try this, and the way OpenGL ES makes it really easy to wreck efficiency and what you are able to do to keep away from that.
With out going into an excessive amount of element, TBR {hardware} operates on the idea of “render passes”. Every render cross is a set of draw calls to the identical “framebuffer” with no interruptions. For instance, say a render cross within the software points 1000 draw calls.
TBR {hardware} takes these 1000 draw calls, runs the pre-fragment shaders and figures out the place every triangle falls within the framebuffer. It then divides the framebuffer in small areas (known as tiles) and redraws the identical 1000 draw calls in every of them individually (or reasonably, whichever triangles truly hit that tile).
The tile reminiscence is successfully a cache which you could’t get unfortunate with. In contrast to CPU and lots of different caches, the place dangerous entry patterns may cause thrashing, the tile reminiscence is a cache that’s loaded and saved at most as soon as per render cross. As such, it’s extremely environment friendly.
So, let’s put one tile into focus.
Reminiscence accesses between RAM, Tile Reminiscence and shader cores. The Tile Reminiscence is a type of quick cache that’s (optionally) loaded or cleared on render cross begin and (optionally) saved at render cross finish. The shader cores solely entry this reminiscence for framebuffer attachment output and enter (by means of enter attachments, in any other case often called framebuffer fetch).
Within the above diagram, there are a selection of operations, every with a price:
Fragment shader invocation: That is the actual price of the applying’s draw calls. The fragment shader can also entry RAM for texture sampling and many others, not proven within the diagram. Whereas this price is critical, it’s irrelevant to this dialogue.
Fragment shader attachment entry: Colour and depth/stencil information is discovered on the tile reminiscence, entry to which is lightning quick and consumes little or no energy. This price can also be irrelevant to this dialogue.
Tile reminiscence load: This prices time and power, as accessing RAM is gradual. Thankfully, TBR {hardware} has methods to keep away from this price: – Skip the load and depart the contents of the framebuffer on the tile reminiscence undefined (for instance as a result of they will be utterly overwritten) – Skip the load and clear the contents of the framebuffer on the tile reminiscence immediately
Tile reminiscence retailer: That is no less than as pricey as load. TBR {hardware} has methods to keep away from this price too: – Skip the shop and drop the contents of the framebuffer on the tile reminiscence (for instance as a result of that information is now not wanted) – Skip the shop as a result of the render cross didn’t modify the values that had been beforehand loaded
Crucial takeaway from the above is:
Keep away from load in any respect prices
Keep away from retailer in any respect prices
That is trivial with Vulkan, however simpler stated than carried out with OpenGL. If you’re on the fence about shifting to Vulkan, the additional work of managing descriptor units, command buffers, and many others will all be definitely worth the super achieve from creating fewer render passes with the suitable load and retailer ops.
Vulkan natively has an idea of render passes and cargo and retailer operations, immediately mapping to the TBR options above. Take a set of attachments (some coloration, perhaps a depth/stencil) in a render cross, they may have load ops (akin to “Tile reminiscence load” as described within the part above) and retailer ops (akin to “Tile reminiscence retailer”). Contained in the render cross, only some calls are allowed; notably calls that set state, bind assets and draw calls.
You’ll be able to create render passes with VK_KHR_dynamic_rendering (trendy strategy) or VkRenderPass objects (authentic strategy). Both manner, you possibly can configure the load and retailer operations of every render cross attachment immediately.
Potential load ops are:
LOAD_OP_CLEAR: Which means the attachment is to be cleared when the render cross begins. That is very low-cost, as it’s carried out immediately on tile reminiscence.
LOAD_OP_LOAD: Which means the attachment contents are to be loaded from RAM. That is very gradual.
LOAD_OP_DONT_CARE: Which means the attachment will not be loaded from RAM, and its contents are initially rubbish. This has no price.
Potential retailer ops are:
STORE_OP_STORE: Which means the attachment contents are to be saved to RAM. That is very gradual.
STORE_OP_DONT_CARE: Which means the attachment will not be saved to RAM, and its contents are thrown away. This has no price.
STORE_OP_NONE: Which means the attachment will not be saved to RAM as a result of the render cross by no means wrote to the attachment in any respect. This has no price.
A great render cross may seem like the next:
Use LOAD_OP_CLEAR on all attachments (very low-cost)
Quite a few draw calls
Use STORE_OP_STORE on the first coloration attachment, and STORE_OP_DONT_CARE on ancillary attachments (akin to depth/stencil, g-buffers, and many others) (minimal retailer price)
For multisampling, the ops are comparable. See this weblog submit for additional particulars concerning multisampling.
You’ll be able to obtain extremely environment friendly rendering on TBR {hardware} with Vulkan by conserving the render passes as few as doable and avoiding pointless load and retailer operations.
Sadly, OpenGL doesn’t information the applying in direction of environment friendly rendering on TBR {hardware} (in contrast to Vulkan). As such, cell drivers have amassed quite a few heroics to reorder the stream of operations issued by the purposes as in any other case their efficiency can be abysmal. These heroics are the supply of most nook case bugs you may need encountered in these drivers, and understandably so; they make the driving force far more sophisticated.
Do your self a favor and improve to Vulkan!
Nonetheless right here? Alright, let’s see how we are able to make an OpenGL software problem calls that will result in ideally suited render passes. The easiest way to grasp that’s truly by mapping just a few key OpenGL calls to Vulkan ideas, as they match the {hardware} very properly. So first, learn the Render Passes in Vulkan part above!
Now let’s see how to try this with OpenGL.
That is extraordinarily essential, and the primary supply of inefficiency in apps and heroics in drivers. What does it imply to interrupt the render cross? Take the best render cross within the earlier part: what occurs if in between the quite a few draw calls, an motion is carried out that can not be encoded within the render cross?
Say out of 1000 draw calls wanted for the scene, you’ve issued 600 of them and now want a fast away from a placeholder texture to pattern from within the subsequent draw name. You bind that texture to a temp framebuffer, bind that framebuffer and clear it, then bind again the unique framebuffer and problem the remainder of the 400 draw calls. Actual purposes (plural) do that!
However, the render cross can’t maintain a transparent command for an unrelated picture (it could actually solely try this for the render cross’s attachments). The consequence can be two render passes:
(authentic render cross’s load ops)
600 draw calls
Render cross breaks: Use STORE_OP_STORE on all attachments (tremendous costly)
Clear a tiny texture
Use LOAD_OP_LOAD on all attachments (tremendous costly)
400 draw calls
(authentic render cross’s retailer ops)
OpenGL drivers truly optimize this and shuffle the clear name earlier than the render cross and keep away from the render cross break … for those who’re fortunate.
What causes a render cross to interrupt? Numerous issues:
The apparent: issues that want the work to get to the GPU proper now, akin to glFinish(), glReadPixels(), glClientWaitSync(), eglSwapBuffers(), and many others.
Binding a distinct framebuffer (glBindFramebuffer()), or mutating the presently certain one (e.g. glFramebufferTexture2D()): That is the commonest cause for render cross breaks. Essential to not unnecessarily do that. Please!
Synchronization necessities: For instance, glMapBufferRange() after writing to the buffer within the render cross, glDispatchCompute() writing to a useful resource that was used within the render cross, glGetQueryObjectuiv(GL_QUERY_RESULT) for a question used within the render cross, and many others.
Different probably shocking causes, akin to enabling depth write to a depth/stencil attachment that was beforehand in a read-only suggestions loop (i.e. concurrently used for depth/stencil testing and sampled in a texture)!
The easiest way to keep away from render cross breaks is to mannequin the OpenGL calls after the equal Vulkan software would have:
Separate non-render-pass calls from render cross calls and do them earlier than the draw calls.
Through the render cross, solely bind issues (NOT framebuffers), set state and problem draw calls. Nothing else!
OpenGL has its roots in IMR {hardware}, the place load and retailer ops successfully don’t exist (aside from LOAD_OP_CLEAR in fact). They’re ignored in Vulkan implementations on IMR {hardware} at this time (once more, aside from LOAD_OP_CLEAR). As demonstrated above nonetheless, they’re essential for TBR {hardware}, and unfortunate for us, assist for them was indirectly added to OpenGL.
As an alternative, there’s a mixture of two separate calls that controls load and retailer ops of a render cross attachment. You need to make these calls simply earlier than the render cross begins and simply after the render cross ends, which as we noticed above it isn’t in any respect apparent when it occurs. Enter driver heroics to reorder app instructions in fact.
The 2 calls are the next:
glClear() and household: When this name is made earlier than the render cross begins, it ends in the corresponding attachment’s load op to turn into LOAD_OP_CLEAR.
glInvalidateFramebuffer(): If this name is made earlier than the render cross begins, it ends in the corresponding attachment’s load op to turn into LOAD_OP_DONT_CARE. If this name is made after the render cross ends, the corresponding attachment’s retailer op could turn into STORE_OP_DONT_CARE (if the decision will not be made too late).
As a result of the glClear() name is made earlier than the render cross begins, and since purposes make that decision in actually random locations, cell drivers go to nice lengths to defer the clear name such that if and when a render cross begins with such an attachment, its load op might be changed into LOAD_OP_CLEAR. Which means typically the applying can clear the attachments a lot sooner than the render cross begins and nonetheless get this good load op. Beware that scissored/masked clears and scissored render passes thwart all that nonetheless.
For glInvalidateFramebuffer(), the driving force tracks which subresources of the attachment have legitimate or invalid contents. When carried out sooner than the render cross begins, this may simply result in the attachment’s load op to turn into LOAD_OP_DONT_CARE. To get the shop op to turn into STORE_OP_DONT_CARE nonetheless, there may be nothing the driving force can do if the app makes the decision on the flawed time.
To get the best render cross then, the applying must make the calls as such:
glClear() or glClearBuffer*() or glInvalidateFramebuffer() (might be carried out earlier)
Quite a few draw calls
glInvalidateFramebuffer() for ancillary attachments.
It’s of the utmost significance for the glInvalidateFramebuffer() name to be made proper after the final draw name. Anything taking place in between could make it too late for the driving force to regulate the shop op of the attachments. There’s a slight distinction for multisampling, defined in this weblog submit.
Now you’ve gone by means of the difficulty of implementing all that in your software or sport, however how have you learnt it’s truly working? Certain, FPS is doubled and battery lasts for much longer, however are all optimizations working as anticipated?
You will get assist from a mission known as ANGLE (slated to be the longer term OpenGL ES driver on Android, already out there in Android 15). ANGLE is an OpenGL layer on high of Vulkan (amongst different APIs, however that’s irrelevant right here), which implies that it’s an OpenGL driver that does all the identical heroics as native drivers, besides it produces Vulkan API calls and so is one driver that works on all GPUs.
There are two issues about ANGLE that make it very helpful in optimizing OpenGL purposes for TBR {hardware}.
One is that its translation to Vulkan is user-visible. Since Vulkan render passes map completely to TBR {hardware}, by inspecting the generated Vulkan render passes one can decide whether or not their OpenGL code might be improved and the way. My favourite manner of doing that’s taking a Vulkan RenderDoc seize of an OpenGL software working over ANGLE.
Discover a LOAD_OP_LOAD that’s pointless? Clear the feel, or invalidate it!
Discover a STORE_OP_STORE that’s pointless? Put a glInvalidateFramebuffer() on the proper place.
Is STORE_OP_STORE nonetheless there? That was not the best place!
Have extra render passes than you anticipated? See subsequent level.
The opposite is that it declares why a render cross has ended. In a RenderDoc seize, this exhibits up on the finish of every render cross, which can be utilized to confirm that the render cross break was supposed. If it wasn’t supposed, along with the API calls across the render cross break, the offered info will help you determine what OpenGL name sequence has induced it. For instance, on this seize of a unit check, the render cross is damaged as a consequence of a name to glReadPixels() (as hinted at by the next vkCmdCopyImageToBuffer name):
ANGLE might be instructed to incorporate the OpenGL calls that result in a given Vulkan name within the hint, which might make figuring issues out simpler. ANGLE is open supply, be at liberty to examine the code if that helps you perceive the rationale for render cross breaks extra simply.
Whereas on this topic, you would possibly discover it useful that ANGLE points efficiency warnings when it detects inefficient use of OpenGL (in different situations unrelated to render passes). These warnings are reported by means of the GL_KHR_debug extension’s callback mechanism, are logged and in addition present up in a RenderDoc seize. You would possibly very properly discover different OpenGL pitfalls you could have fallen into.
Vulkan could seem sophisticated at first, however it does one factor very properly; it maps properly to {hardware}. Whereas an OpenGL software could also be shorter in lines-of-code, in a manner it’s extra sophisticated to write down a good OpenGL software particularly for TBR {hardware} due to its lack of construction.
Whether or not you find yourself upgrading to Vulkan or staying with OpenGL, you’d do very properly to study Vulkan. If nothing else, studying Vulkan will show you how to write higher OpenGL code.
In case your future holds extra OpenGL code, I sincerely hope that the above information helps you produce OpenGL code that isn’t an excessive amount of slower than the Vulkan equal would. And don’t hesitate to attempt ANGLE out to enhance your efficiency, individuals who do have discovered nice success with it!
Tedious paperwork and lengthy wait instances are each individual’s worst insurance coverage nightmare. However insurance coverage declare automation is paving the way in which for sooner, extra correct, and extra customer-friendly experiences.
The drive to reinforce claims processing by means of new applied sciences has intensified, particularly since each greenback saved immediately impacts profitability. The pandemic additional accelerated this shift, quickly pushing insurers to undertake digital and digital claims dealing with virtually in a single day.
This text explores the impression of automation on the claims panorama, whether or not you are an insurer seeking to streamline operations or a policyholder in search of faster resolutions.
What’s claims course of automation?
In 2024, 88% of consumers anticipate insurers to supply on-line self-service portals for claims, driving insurers to spend money on user-friendly digital platforms to reinforce the claims course of.
Claims course of automation makes use of superior know-how to streamline insurance coverage declare administration. It includes automating completely different steps of declare processing workflows, similar to declare submission, claims investigation, deep coverage assessment, and decision-making.
This automation course of leverages cutting-edge instruments similar to machine studying (ML), synthetic intelligence (AI), and pure language processing (NLP).
With automation, insurers can automate repetitive duties similar to guide knowledge entry and doc verification, velocity up declare processing to extend effectivity and accuracy and decrease errors and fraud.
Automating claims processing additionally affords substantial advantages, similar to further price financial savings, improved customer support, and strengthened knowledge safety.
This transformation enhances operational effectivity and leads to vital price financial savings and improved buyer satisfaction.
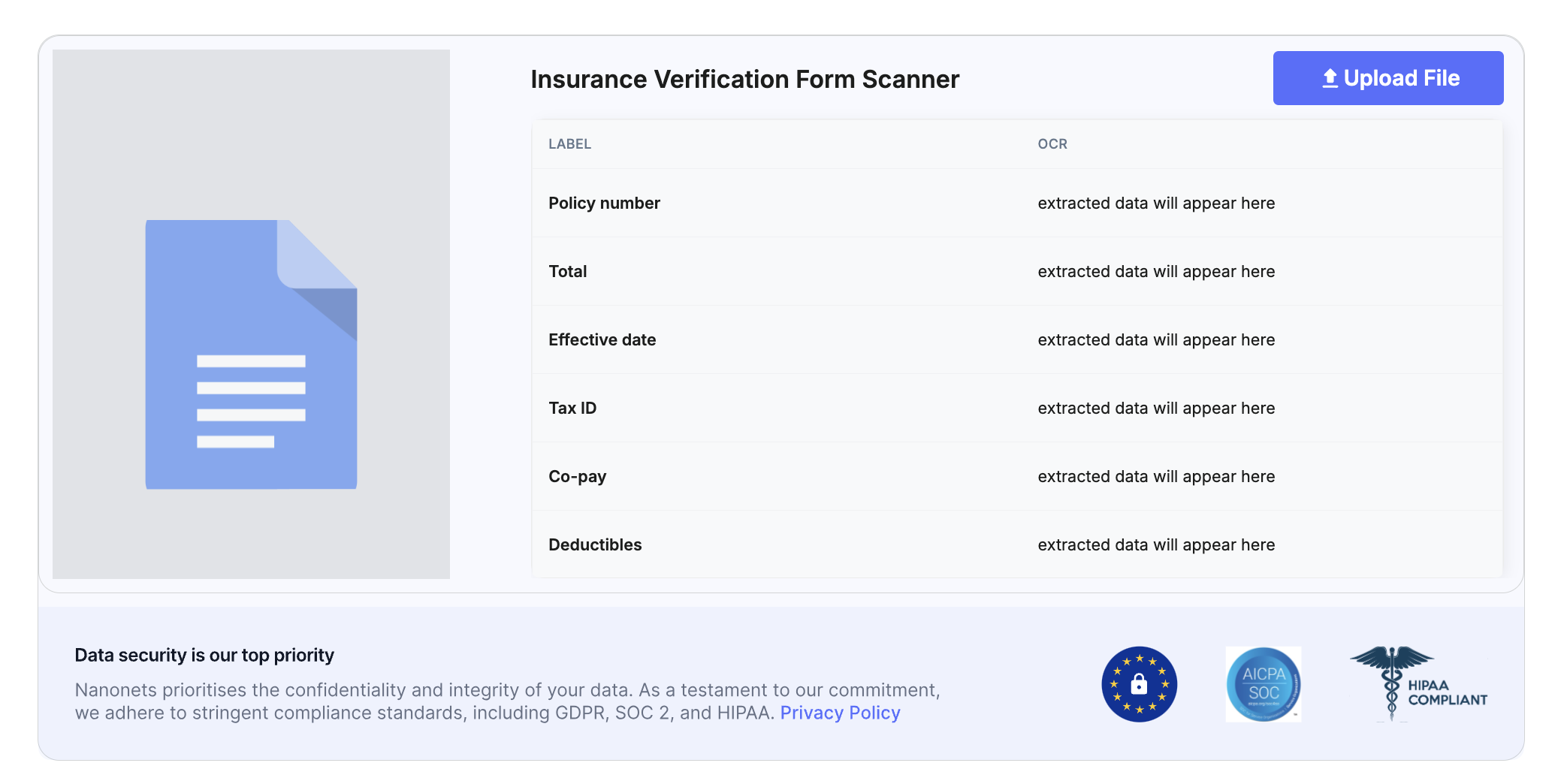
Add any insurance coverage type and extract knowledge in seconds
How automated insurance coverage claims processing works
Let’s perceive the applied sciences that drive automated insurance coverage declare processing and the steps within the course of:
Machine Studying(ML)
By analyzing intensive datasets of historic claims, ML algorithms can determine patterns and developments, enabling insurers to foretell outcomes, assess danger ranges, and even flag probably fraudulent claims.
That is important in automating decision-making processes, decreasing guide interventions, and expediting claims settlements.
For e.g., ML fashions can precisely estimate restore prices in auto insurance coverage claims by evaluating them in opposition to huge datasets of comparable claims.
Synthetic Intelligence (AI)
AI is especially good at dealing with complicated duties like fraud detection, danger evaluation, and claims adjudication.
Superior AI programs can cross-check declare particulars in opposition to coverage knowledge, third-party databases, and historic declare information to detect anomalies and assess the validity of claims. This considerably reduces the probability of fraudulent payouts and improves total claims accuracy.
Pure Language Processing (NLP)
NLP algorithms can extract and interpret data from unstructured knowledge codecs, similar to handwritten notes, emails, and scanned paperwork.
This permits automated knowledge entry processes that result in sooner doc assessment, decrease processing time, and enhanced buyer expertise.
Robotic Course of Automation (RPA)
RPA automates repetitive, rule-based duties in claims automation. RPA bots can deal with duties likeknowledge entry, verification of declare particulars, updating standing within the claims administration system, and even communication with clients.
This frees up vital time for insurance coverage suppliers to give attention to extra complicated, high-value actions, thus rising operational effectivity and decreasing the probability of human error
Correct OCR is crucial for digitizing bodily paperwork and pictures by changing them into machine-readable textual content. OCR can swiftly course of types, invoices, and different paper-based paperwork, extracting essential data like names, dates, and declare numbers.
This automation reduces the time spent on guide knowledge entry and ensures that data is precisely captured for additional processing. When mixed with AI, superior OCR programs can even deal with variations in doc codecs and high quality, enhancing the reliability of the information extracted.
Seeking to automate claims processing? Strive Nanonets Claims Processing Automated Workflows free of charge.
Steps in insurance coverage claims course of and how one can automate them
Over 50% of worldwide insurers prioritize digital claims processing, pushed by the necessity to deal with challenges like provide chain disruptions that impression 62% of insurers.
Automated declare processing includes a number of key steps, every enhanced by automation to enhance effectivity, accuracy, and velocity.
Let’s perceive every step and the way workflow automation appears like at every step:
Declare submission
The method begins with the policyholder submitting a First Discover of Loss (FNOL) by means of the insurance coverage platform or the dealer. The policyholder supplies primary details about the declare, such because the date and placement of the incident and any supporting documentation or photographs as proof.
With automation, the declare submission course of has now gotten extra environment friendly and correct with –
Digital instruments embody a web based insurance coverage platform, cellular apps, and chatbots by means of which the policyholder can immediately submit the declare.
Pre-filled types that robotically populate knowledge from the present buyer information. This removes the necessity to fetch paperwork, decreasing errors and the time interval between the loss and declare submitting.
Immediate acknowledgment supplies rapid affirmation receipt and a monitoring ID, maintaining policyholders knowledgeable all through.
Assessment and verification
Insurance coverage suppliers then study the coverage phrases and accumulate additional proof and paperwork. The matter is investigated, and all liable events are recognized.
The insurer makes use of completely different strategies to evaluate the declare and the extent of harm to find out whether or not the coverage covers it. This may increasingly contain analyzing the coverage language, reviewing the reported damages, and consulting with third-party databases to confirm the claimant’s id and prior claims historical past.
Automation accelerates this course of by means of:
Automated coverage evaluation:Declare processing automation instruments cross-reference claims with coverage databases to determine protection particulars and exclusions swiftly.
It instantly identifies the phrases and situations and exclusions, eliminating the necessity for guide assessment and rushing up the assessment course of.
Doc verification: AI and NLP confirm the submitted paperwork with excessive accuracy, considerably decreasing errors that human eyes typically miss. For instance, AI can simply learn and confirm receipts and reviews in opposition to the coverage phrases.
Fraud detection: Fraudulent claims are one of many insurance coverage trade’s largest challenges. Superior algorithms analyze claims knowledge to detect patterns or anomalies which will point out fraudulent exercise.
Whereas people can’t probably confirm 1000’s of claims day by day, AI reduces this quantity considerably.
This additionally helps them prioritize claims that require detailed scrutiny, guaranteeing that high-risk claims are flagged early within the course of. This reduces the probability of fraudulent claims being authorized, enhancing the integrity of the method.
Integrations: Automation pulls knowledge from a number of sources, databases, third-party instruments, and so forth., thus permitting for seamless verification.
If the declare is deemed legitimate, the insurer will start validating it by gathering further data, similar to medical information or restore estimates. The declare is both authorized or denied based mostly on the coverage pointers. The claimant should bear any further expense for damages the insurance coverage coverage doesn’t cowl.
With automation, the declare decision-making is far sooner and unbiased, and reduces the errors considerably in human judgment calls:
Pre-set guidelines: Automating declare processing permits setting pre-set guidelines and pointers to judge the declare in line with the coverage protection.
It helps insurance coverage corporations decide if the declare meets the factors for approval and if additional assessment is important, considerably rushing up the decision-making course of.
Consistency: With automation, each declare is evaluated persistently, decreasing the probabilities of human bias or oversight. The device ensures that comparable claims obtain comparable outcomes by following standardized guidelines, bettering equity and reliability.
Whereas automation does cut back the necessity for guide intervention, it additionally flags high-value or high-risk claims that may be despatched for human assessment. This ensures that such circumstances obtain the cautious consideration they deserve.
Cost disbursement
The insurance coverage supplier initiates the digital fee disbursement if the declare is verified.
Automated fee processing: As soon as a declare is authorized, the automated device calculates the settlement quantity based mostly on the relevant coverage and triggers the fee course of. This ensures faster and extra correct disbursements and reduces policyholder delays.
Digital funds: The declare processing platform is built-in with digital fee instruments similar to direct financial institution transfers or cellular fee programs. This hastens fee disbursement and supplies a transparent, traceable document of transactions for dispute decision.
It additionally notifies the policyholder of the fee standing, resulting in elevated transparency and improved buyer satisfaction.
Advantages of claims automation
Automating claims processing affords quite a few benefits that improve the effectivity and effectiveness of insurance coverage operations. Right here’s how:
Insurance coverage corporations that use RPA and AI can deal with as much as 10 instances extra claims in the identical interval than these utilizing conventional guide processes.
Sooner declare settlements
Duties that normally take weeks, similar to claims verification and fraud detection, can now be accomplished with AI instruments in a matter of days. This could cut back the general declare processing time from weeks to only a few days, permitting for faster decision and sooner payouts to policyholders.
Improved customer support
Automation can result in a 15-20% improve in buyer satisfaction. This enchancment is essentially as a result of sooner claims processing, real-time standing updates, proactive communication with well timed alerts and notifications, and extra correct payouts.
Elevated income and price financial savings
Insurers implementing superior declare automation have reported income will increase of as much as 20%, pushed largely by better operational effectivity and enhanced buyer retention.
By decreasing reliance on guide labor, automation additionally helps corporations decrease their operational and administrative prices by 30%, resulting in total profitability by discount in errors and improved monetary efficiency.
Threat mitigation and fraud prevention
Fraud detection applied sciences have been instrumental in decreasing the $40 billion annual price of fraudulent claims within the U.S. alone.
Superior automation instruments incorporate options for fraud detection by ML algorithms that detect and flag suspicious patterns in claims. Additionally they present danger evaluation and analysis by figuring out and mitigating potential fraudulent actions.
Declare automation improves environmental sustainability by minimizing reliance on paper-based processes and decreasing waste. By transitioning to digital documentation, insurance coverage corporations will help decrease the environmental footprint of claims processing operations.
Challenges concerned in declare automation
Whereas automation affords nice advantages to insurance coverage suppliers and policyholders, it additionally presents a number of challenges that insurers should navigate:
Complicated implementation
If new automated know-how and instruments are usually not correctly built-in into present programs, they will shortly grow to be complicated and dear.
Legacy programs that use outdated software program typically face problem adapting to new applied sciences. They require vital funding and wish fixed upgrades and even frequent replacements.
Information high quality and administration
Automation machine studying fashions rely closely on a big set of correct and constant knowledge. Inconsistent or poor-quality knowledge can result in errors in automated processes and show ineffective.
Restricted flexibility
Whereas many automated instruments work effectively with easy, predictable duties in declare processing, they typically battle with complicated or distinctive claims that require nuanced decision-making. Human intervention continues to be mandatory in such conditions and may decelerate the method.
Cybersecurity dangers
The insurance coverage declare trade offers with an unlimited quantity of delicate data and automation instruments with entry to this data may be straightforward targets for cyberattacks. Strong cybersecurity measures are essential to guard in opposition to knowledge breaches, malware, and different threats.
Regulatory compliance
Regulatory requirements range by area and alter incessantly. Declare automation programs should adjust to evolving rules and require monitoring and changes.
Adoption
Overhauling your pre-existing system with automation isn’t a one-day job. There’s a lengthy studying curve, and staff should adapt to new instruments and processes. This could typically contain intensive coaching and a shift in job roles, which may be difficult for workers.
Buyer belief
Whereas there’s a common consensus on the widespread advantages of automation, some could also be cautious of automated processes. Such clients choose human interplay, particularly in complicated or high-stakes conditions. Insurers should steadiness automation with sustaining a private contact to make sure buyer satisfaction when adopting automation in declare processes.
Addressing these challenges requires cautious planning, funding, and a strategic strategy to make sure that the advantages of automation are totally realized whereas minimizing potential drawbacks.
With this, let’s start understanding how one can start your automation journey within the insurance coverage trade.
Let’s take a look at among the finest instruments which might be leveraging superior AI to automate completely different steps of claims processing within the insurance coverage trade:
Claims processing
Snapsheet affords a digital claims platform that enables policyholders to submit claims on-line or by means of a cellular app.
ClaimVantage by Majesco supplies a complicated cloud-based claims administration system tailor-made for all times, well being, and incapacity insurance coverage. It affords automated workflows, on-line declare submission, and monitoring capabilities.
Lemonade automates the claims course of, from submission to decision-making. Its AI bot, “Jim,” processes claims immediately, assessing eligibility and disbursing funds inside minutes for easy claims.
Doc verification and validation
NanonetsOCR know-how automates the extraction of key data from declare types, similar to coverage numbers, claimant names, and harm descriptions.
By leveraging machine studying algorithms, Nanonets helps insurers shortly validate claims, decreasing guide work and bettering accuracy. Nanonets is especially trusted and in style for automating document-heavy processes like claims validation, medical information and types knowledge extraction, and even handwritten scanned paperwork.
Tractable makes use of laptop imaginative and prescient and AI to robotically assess automobile harm and decide the suitable restore prices. Tractable’s AI could make fast, data-driven selections, considerably decreasing the time required to settle auto insurance coverage claims
Verisk Analytics: Provides an in depth suite of instruments for claims validation, together with predictive analytics, property and casualty claims analytics, and medical invoice assessment. This device is trusted to validate complicated claims similar to employees’ compensation and property harm.
Customer support
Lemonade is an AI-powered insurance coverage platform that automates your entire claims course of, from submission to decision-making. Lemonade’s AI bot “Jim” processes claims immediately, assessing eligibility and disbursing funds inside minutes for easy claims.
Underwriting
Octo Telematicsmakes use of knowledge to research driving habits and alter premiums based mostly on danger, resulting in extra correct pricing and higher danger administration.
AI underwriting instruments like Nanonets can help underwriters by robotically analyzing applicant knowledge, figuring out danger elements, and suggesting applicable protection ranges based mostly on historic knowledge and predictive fashions
Checkbook.io affords a digital test platform that enables insurers to situation funds electronically and securely.
One Inc supplies a digital funds platform designed particularly for the insurance coverage trade. One Inc. affords safe, real-time fee options for claims disbursement by way of ACH, bank cards, and digital wallets. Its integration with present claims programs ensures seamless and environment friendly fee processing.
Claims verification and fraud detection
Shift Know-how is in style for its AI-driven fraud detection capabilities. It analyzes claims knowledge to determine potential fraud, errors, and anomalies. Its algorithms are skilled on huge datasets, guaranteeing excessive accuracy in flagging suspicious claims, thereby decreasing the chance of fraudulent payouts.
FRISS is a complete insurance coverage fraud detection platform that makes use of AI and predictive analytics to watch and confirm claims. It evaluates danger scores in real-time through the declare lifecycle, serving to insurers detect and forestall fraud at an early stage.
Take into account the next whereas evaluating an automation device for declare processing and administration:
Getting began with claims course of automation with Nanonets
Nanonets is an AI-powered doc processing platform that permits corporations throughout completely different industries to extract data from unstructured paperwork.
Options of Nanonets AI that make it profitable for insurance coverage corporations:
Automated doc processing
OCR know-how for handwritten types, scanned PDFs and pictures.
Multi-language help
Clever knowledge extraction
Obtain 99% accuracy in knowledge extraction
Pre-built customized machine studying fashions
Automated knowledge validation
Sample recognition to identify anomalies
Assign danger scores to claims
Seamless integration and rule-based approval setup
Automated notifications and well timed alerts
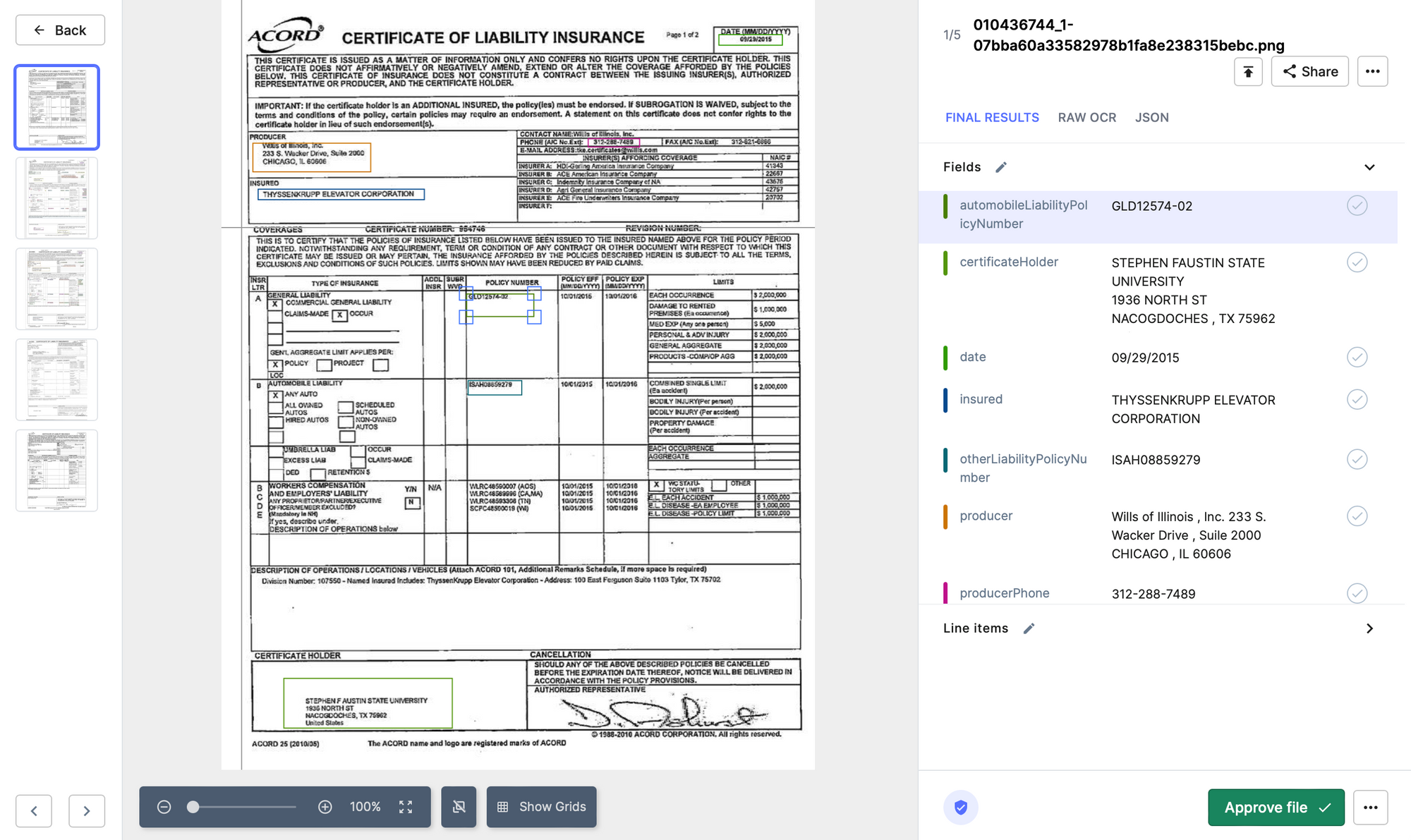
To begin processing your insurance coverage claims on Nanonets free of charge,
Step 3: Wait because the AI and OCR processes the declare and extracts all fields
Step 4: Confirm all of the fields. Prepare the mannequin to find different fields, if missed
Step 5: Obtain the information in a CSV, XML, or any format you favor
Step 6: Course of your declare additional by integrating your present system
Whereas claims processing is one problem within the insurance coverage trade, Nanonets has additionally automated the underwriting course of, coverage issuance, renewals administration, and premium calculation for a lot of healthcare and insurance coverage corporations worldwide.
Enthusiasmus, Know-how und Kreativität – beim Deutschlandfinale 2024 der World Robotic Olympiad (WRO) in Passau zeigten 136 Groups aus Kindern und Jugendlichen im Alter von acht bis 19 Jahren ihr beeindruckendes technisches Expertise. Die Sieger der vier Kategorien nehmen im November im türkischen Izmir am internationalen WRO-Finale teil. fischertechnik begleitete den vom Verein TECHNIK BEGEISTERT organsierten Nachwuchswettbewerb als globaler Companion.
Die insgesamt 136 Groups hatten sich in 50 regionalen Ausscheidungen für das Finale in der Dreiländerhalle qualifiziert. 103 Mannschaften traten in der Kategorie „Robo Mission“ an, 16 nahmen bei den „Future Innovators“ teil und zehn bei den „Future Engineers“. Zudem waren auch sieben „Starter-Groups“ dabei. In den vier Kategorien geht es in unterschiedlichen Schwierigkeitsgraden darum, Roboter und Roboterfahrzeuge erfolgreich durch einen Parcours zu bringen bzw. ein Roboterprojekt zu entwickeln und zu präsentieren. Das aktuelle Thema des Wettbewerbs 2024 lautet „Earth Allies“. Die Schülerinnen und Schüler sollen sich damit auseinandersetzen, wie Roboter dabei helfen können, in Harmonie mit der Natur zu leben. „Es struggle fantastisch zu erleben, wie die Kinder und Jugendlichen ihr Bestes gaben und zu sehen, wie fischertechnik Teil der einzelnen Roboter-Erfolgsgeschichten sein kann“, zeigte sich Ann-Christin Walker, Enterprise Growth Administration Training bei fischertechnik, von den Darbietungen des Tüftlernachwuchses begeistert. Für das internationale Finale in Izmir im November haben sich 14 Groups qualifiziert.
fischertechnik struggle mit einem Stand auf dem WRO Deutschland-Finale vertreten und präsentierte dort die breite und vielseitige Robotik-Produktpalette, die Alterszielgruppen vom Kindergarten bis zur Universität anspricht. Speziell für die WRO-Kategorie „Future Engineers“ hat das Nordschwarzwälder Unternehmen den Baukasten STEM Coding Competitors entwickelt. Dieses Set bringt alles mit, um ein autonom fahrendes Roboterauto zu bauen, zu programmieren und einen Parcours erfolgreich zu meistern. Großes Interesse beim Publikum fanden auch Lernkonzepte, die erneuerbare Energien für Kinder in Grund- und weiterführenden Schulen spielerisch und handlungsorientiert begreifbar machen.
Der Verein TECHNIK BEGEISTERT wurde 2011 von jungen Erwachsenen gegründet. Ziel der über 80 Mitglieder ist es, die eigene Begeisterung für Roboterwettbewerbe an andere Kinder und Jugendliche weiterzugeben. Mit der World Robotic Olympiad organisiert der Verein einen der größten Roboterwettbewerbe in Deutschland. Außerdem unterstützt er Schulen beim Aufbau von Roboter-AGs, führt Schulungen durch und unterstützt andere Roboteraktivitäten.
A group led by Jose Onuchic at Rice College and Paul Whitford at Northeastern College, each researchers on the Nationwide Science Basis Physics Frontiers Heart on the Heart for Theoretical Organic Physics (CTBP) at Rice, has made a discovery within the struggle in opposition to extreme acute respiratory syndrome coronavirus-2 (SARS-CoV-2), the virus liable for COVID-19.
The group, in partnership with an experimental effort led by Yale College researchers Walter Mothes and Wenwei Li, has uncovered new insights into how the virus infects human cells and the way it may be neutralized. Their findings had been revealed within the journal Science on Aug. 15.
SARS-CoV-2 makes use of its spike protein to connect to the angiotensin-converting enzyme 2 on human cells, initiating a course of that enables it to enter the cell. The spike protein has two predominant components: the S1 area, which varies drastically amongst totally different strains of the virus, and the S2 area, which is extremely conserved throughout totally different coronaviruses. This similarity makes the S2 area a promising goal for vaccines and therapies that would work in opposition to many virus strains.
By combining simulations and theoretical predictions with structural data from their experimental collaborators, together with preliminary and last configurations in addition to intermediate states in the course of the viral invasion, the researchers obtained an in depth image of the an infection course of at an atomic stage.
“Understanding these intermediate states of the spike protein creates new alternatives for therapy and prevention,” mentioned Onuchic, the Harry C. and Olga Okay. Wiess Chair of Physics, professor of physics and astronomy, chemistry and biosciences and co-director of CTBP. “Our work demonstrates the significance of mixing theoretical and experimental approaches to deal with complicated issues akin to viral infections.”
Utilizing a complicated imaging method referred to as cryo-electron tomography, the experimental researchers at Yale captured detailed snapshots of the spike protein because it adjustments in the course of the fusion course of.
They found antibodies concentrating on a particular a part of the S2 area, referred to as the stem-helix, which might bind to the spike protein and cease it from refolding right into a form obligatory for fusion. This prevents the virus from getting into human cells.
Our research gives an in depth understanding of how the spike protein adjustments form throughout an infection and the way antibodies can block this course of. This molecular perception opens up new potentialities for designing vaccines and therapies concentrating on a variety of coronavirus strains.”
Jose Onuchic at Rice College
The researchers used a mix of theoretical modeling and experimental knowledge to attain their findings. By combining simulations of the spike protein with experimental photos, they captured intermediate states of the protein that had been beforehand unseen. This built-in method allowed them to grasp the an infection course of at an atomic stage.
“The synergy between theoretical and experimental strategies was essential for our success,” mentioned Whitford, a professor within the Division of Physics at Northeastern. “Our findings spotlight new therapeutic targets and techniques for vaccine improvement that could possibly be efficient in opposition to most variants of the virus.”
The group’s discovery is critical within the ongoing efforts to fight COVID-19 and put together for future outbreaks of associated viruses. By concentrating on the conserved S2 area, scientists can develop vaccines and therapies that stay efficient even because the virus mutates.
“This analysis is a step ahead within the struggle in opposition to COVID-19 and different coronaviruses which will emerge sooner or later,” mentioned Saul Gonzalez, director of the U.S. Nationwide Science Basis’s Physics Division. “Understanding the elemental bodily workings inside intricate organic mechanisms is crucial for creating simpler and common remedies that may shield our well being and save lives.”
This work was supported by the Nationwide Science Basis, Nationwide Institutes of Well being, Canadian Institutes of Well being Analysis, Canada Analysis Chairs and Welch Basis.
Different researchers embrace Michael Grunst and Zhuan Qin on the Division of Microbial Pathogenesis and Shenping Wu on the Division of Pharmacology at Yale; Esteban Dodero-Rojas at CTPB; Shilei Ding, Jérémie Prévost and Andrés Finzi on the Centre de Recherche du CHUM; Yaozong Chen and Marzena Pazgier within the Infectious Illness Division within the F. Edward Hebert Faculty of Medication at Uniformed Providers College of the Well being Sciences; and Yanping Hu and Xuping Xie within the Division of Biochemistry and Molecular Biology on the College of Texas Medical Department at Galveston.
Supply:
Journal reference:
Grunst, M. W., et al. (2024). Construction and inhibition of SARS-CoV-2 spike refolding in membranes. Science. doi.org/10.1126/science.adn5658.