In response to statistics, decentralized exchanges (DEXs) over the past 3-4 years have grow to be a serious a part of Decentralized Finance (DeFi).
PancakeSwap’s 24-hour buying and selling quantity, for instance, reaches $7.39 billion, Uniswap’s — $3.98 billion, and Fluid’s — $1.77 billion.
Nonetheless, regardless of all of the seeming profitability, the buying and selling course of on DEXs is characterised by fragmentation — not solely throughout buying and selling pairs and protocols but in addition throughout whole blockchain networks.
The identical asset can have considerably various costs on completely different chains, relying on liquidity, provide and demand imbalances, and transaction speeds.
In apply, it’s practically unimaginable to hold out asset shopping for and reselling manually as a result of costs change in seconds. Because of this many crypto merchants use cross-chain DEX arbitrage bots.
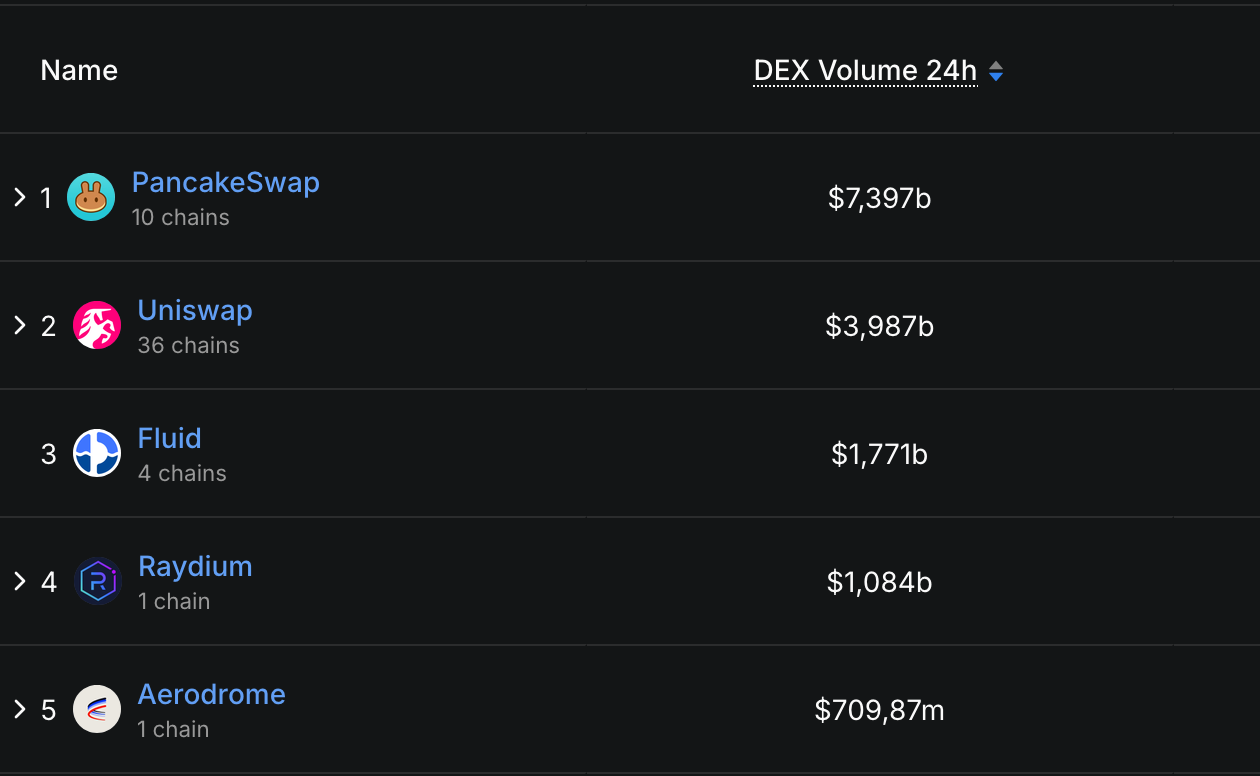
Prime DEXs Ranked by 24h Buying and selling Quantity, DefiLlama
What Is Cross‑Chain DEX Arbitrage?
Cross-chain DEX arbitrage consists of shopping for a token on one chain and promoting the identical token on a DEX on one other, all to capitalize on worth variations.
These gaps can come up based mostly on variations in liquidity, volumes, or how briskly the worth is being up to date between networks.
For instance, suppose a token is priced at $98 on a DEX on Avalanche however $100 on a DEX on Ethereum. A dealer (or ideally a bot) can purchase the token on Avalanche at a cheaper price and promote it on Ethereum for a $2 revenue per token (after charges).
Arbitrage of this type maintains costs in equilibrium throughout blockchains, however the window of alternative sometimes shuts in a matter of seconds. That’s why utilizing bots to swap property turns into a necessity.
What Is a Cross‑Chain DEX Arbitrage Bot?
A cross-chain DEX arbitrage bot is an automatic program that observes token costs throughout a number of exchanges on completely different blockchains.
When it detects a worth disparity important sufficient to cowl charges and slippage, it executes a sequence of trades between them to reap the distinction.
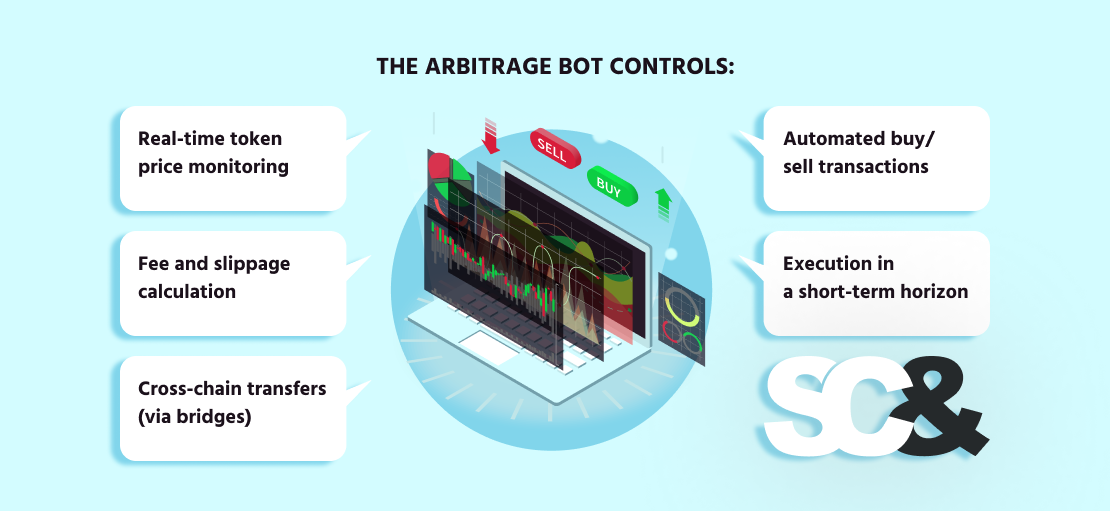
These bots are vital in cross-chain situations, the place handbook execution could be too late and completely miss the chance. The arbitrage bot controls:
- Actual-time token worth monitoring
- Payment, slippage, and profitability calculation
- Cross-chain transfers (by way of bridges)
- Automated purchase/promote transactions
- Frontrun and backrun execution
Key Parts of a Cross‑Chain Arbitrage Bot
A cross-chain arbitrage bot all the time wants to incorporate a number of parts so as to detect worth dissimilarities and make trades in a well timed method.
Arbitrage Logic
That is the core of the bot. It retains observe of token costs on completely different DEXs (Ethereum, BSC) and figures out when a worth distinction is large enough to make a revenue after fuel charges, bridge charges, and slippage.
However to actually keep forward, the bot must also take a look at a number of much less apparent facets:
- Different bots: There could already be bots buying and selling on the identical DEXs. It’s helpful to trace their exercise as a result of they will have an effect on costs earlier than your bot does.
- Market makers: Some tokens are supported by market makers who’ve their very own buying and selling methods to maintain the market liquid. Understanding how they behave helps keep away from chasing deceptive alternatives.
- Buying and selling stats: Analyzing commerce quantity and exercise over the past 7–30 days can provide your bot a greater sense of which alternatives are price going after.
DEX Connections
To commerce on decentralized exchanges like Uniswap, PancakeSwap, or SushiSwap, your bot wants to attach on to the blockchain not simply by way of API, however through the use of a node.
Connecting by way of a blockchain node lets the bot learn knowledge straight from sensible contracts, which is quicker and extra dependable than most APIs. In some instances, it might even observe the mempool, giving your bot an opportunity to identify worth modifications earlier than they occur on-chain.
Cross-Chain Bridge Assist
For the reason that bot works on completely different blockchains, it wants a method to transfer tokens between them. That’s the place bridges like Axelar, LayerZero, or Wormhole are available; they switch property from one chain to a different.
Blockchain Entry (RPC Nodes)
To get up-to-date blockchain knowledge and ship transactions, the buying and selling bot makes use of RPC endpoints, which characterize a form of gateway to every blockchain community.
Usually, this implies working your personal full nodes. Public RPC endpoints are sometimes sluggish, unreliable, or restricted in price, which may trigger delays and missed alternatives.
By establishing your personal blockchain infrastructure, you guarantee quick entry to on-chain knowledge, which is essential not just for shortly sending trades but in addition for calculating profitability and reacting to market modifications in actual time.
Automation Engine
The backend of an arbitrage bot often has two components, every doing a special job:
- Quick Layer – Buying and selling Core: That is the half that does all of the real-time work. It’s multithreaded, retains the whole lot in reminiscence, and reacts shortly to cost modifications. It checks costs, calculates potential earnings, and sends trades—quick. The objective right here is pace, so the bot avoids delays and doesn’t wait on exterior techniques.
- Sluggish Layer – Knowledge & Administration: This half takes care of the whole lot that doesn’t must occur immediately. It shops commerce historical past, tracks stats, saves logs, and handles any user-facing options if wanted. It’s centered on evaluation and long-term management, not pace.
Pockets Administration
The bot wants crypto wallets on every blockchain to carry the tokens it trades. These wallets additionally pay for fuel charges, so it’s essential to maintain them protected and funded.
Security and Danger Controls
To keep away from insufficient trades, the bot ought to have limits in place, for instance, how a lot slippage is okay, how a lot fuel it’s prepared to pay, or what to do if one thing goes fallacious with a bridge or commerce.
In lots of instances, the bot additionally makes use of its personal sensible contract to deal with trades or transfer tokens between blockchains. Nonetheless, since this contract holds funds and interacts with DEXs, it might grow to be a goal for hackers. That’s why it’s crucial to audit the sensible contract and examine for vulnerabilities earlier than utilizing it.
Challenges and Dangers When Utilizing Arbitrage Bots
Working a cross-chain arbitrage bot can look like incomes cash the simple approach on decentralized exchanges, however it’s full of a number of challenges.

To start out with, arbitrage alternatives don’t final lengthy — in some instances, just some seconds. If the bot or the community is uncovered to latency or inefficiency, the worth disparity could disappear earlier than the commerce is accomplished.
Gasoline fees are one other drawback. On some blockchains, transaction charges could leap unexpectedly. If these charges are greater than what you count on your return on funding to be, then chances are you’ll lose cash as a substitute of creating it.
And don’t neglect about competitors. There are many different bots on the market gunning for a similar goal, with better assets and sooner set-ups. The fiercer the atmosphere, the tougher it’s to win.
Finest Practices to Use Arbitrage Bots
Working a cross-chain arbitrage bot could be rewarding, however it additionally takes care and a spotlight to do it proper.
To begin with, all the time check your bot on testnets earlier than utilizing actual cash. This allows you to see the way it performs in actual blockchain circumstances, with out the chance. You’ll be able to repair bugs, enhance your logic, and construct confidence earlier than going stay.
As soon as your bot is stay, it’s essential to focus solely on clearly worthwhile trades. Not each worth distinction is price chasing. Many are too small, and when you subtract fuel charges, bridge prices, and slippage, you would possibly find yourself dropping cash.
Earlier than sending actual trades, you can even run your bot on mainnet in dry-run mode. On this mode, the bot calculates potential earnings and logs what it would have finished, however doesn’t really ship transactions to the blockchain. This can be a helpful step to check your technique in actual market circumstances and see if it’s actually worthwhile.
Your bot additionally wants quick and dependable entry to the blockchains it really works with, and meaning constructing your personal infrastructure with devoted nodes. Public RPC endpoints are sometimes too sluggish or unreliable to compete with different bots. In case your knowledge is delayed even by a second, you could possibly miss worthwhile trades.
And don’t rush into it with massive quantities. Begin small whilst you check your bot with actual trades. As your bot proves itself and your funds grows, it’s essential so as to add extra safety measures: set tighter limits, monitor exercise, and audit your sensible contract and infrastructure.
As soon as your bot begins displaying outcomes and transferring actual quantity, you’ll seemingly entice consideration, not simply from different merchants, however from hackers too. When you’re seen, assume no less than ten persons are already watching what you’re doing. Higher to be prepared than remorse later.
Lastly, preserve bettering. The DeFi world modifications shortly, so replace your bot usually. Watch for brand new instruments, DEXs, and methods that may offer you an edge.
| Tip |
Abstract |
| Take a look at First |
Use testnets to repair bugs and fine-tune earlier than risking actual funds. |
| Commerce Sensible |
Solely go for clearly worthwhile trades after charges and slippage. |
| Dependable Entry |
Use steady RPCs with backups to keep away from missed alternatives. |
| Begin Small |
Start with small quantities, scale up as confidence grows. |
| Keep Up to date |
Hold bettering your bot as DeFi instruments and DEXs evolve. |
Construct vs. Purchase: Ought to You Code Your Personal or Use an Present Platform?
When deciding the way to make a cross-chain arbitrage bot, one of many first questions to contemplate is whether or not you’ll make it your self or use an answer that already exists. There is no such thing as a a technique; it comes down solely to expertise, time, and your objectives.

Construct Your Personal
Constructing your personal bot offers you full management. You’ll be able to determine the way it works, what chains and DEXs it connects to, the way it balances dangers, and if it must be aggressive or conservative.
When you’re curious about creating a brand new technique or gradual optimization over time, ranging from scratch is the path to take.
However assembling a bot additionally takes time and severe technical know-how. When you do it your self, you’ll want to grasp blockchain growth, sensible contracts, APIs, cross-chain bridges, fuel optimization, and extra. And whilst you’re busy coding, you would possibly miss actual buying and selling alternatives.
That’s the place a crypto buying and selling bot growth firm like SCAND can assist. With over 25 years of software program growth expertise and a deep precedence on blockchain options, we can assist you design, create, and refine a customized arbitrage bot that serves your technique and scales along with your wants.
Purchase or Customise
Utilizing an current platform is a a lot sooner method to get began. A lot of the software program available on the market comes pre-built with options equivalent to dashboards, monitoring trades, and alerts. You don’t must develop all of this from scratch, and also you’ll have the ability to check precise trades sooner.
Nonetheless, these instruments are often much less versatile. You might not have the ability to modify its components to match your actual technique. Some platforms additionally cost charges or take a lower of your earnings.
There’s additionally a center choice: begin with an open-source bot and customise it, for instance, utilizing the Bot Starter Equipment from SCAND. It offers you a working base to construct on, and you continue to get some flexibility with out ranging from zero.
Ceaselessly Requested Questions (FAQs)
Is arbitrage authorized?
Sure, crypto arbitrage is authorized in most jurisdictions. Nonetheless, all the time seek the advice of native legal guidelines and laws.
Do I want numerous capital to begin?
Not essentially, however greater capital can cowl fuel prices and encourage extra worthwhile trades.
What’s the distinction between cross-chain and on-chain arbitrage?
On-chain arbitrage includes trades throughout the identical blockchain. Cross-chain arbitrage spans a number of blockchains and requires bridging property between them.
Can I nonetheless generate income with arbitrage bots in 2025?
Sure. Nevertheless it’s tougher than ever. The straightforward wins from 2020–2021 are principally gone. Immediately’s earnings usually rely on sooner execution, entry to obscure chains, and smarter algorithms. You’re now competing towards extremely optimized bots and institutional-grade techniques.





