
ios – Why does dependency evaluation work for script that outputs folder that’s copied as bundle useful resource however not if that script is in an mixture goal?

Principally in my app I’ve a script that outputs a folder with a couple of information inside it. This folder is output to $(BUILT_PRODUCTS_DIR)/construct/ and is referenced through a PBXBuildFile. As a result of I put a wait within the script (to simulate an extended construct I’ve in my actual venture) it is vitally apparent when the script is or is not run. The purpose can be for it to run solely when its dependencies have modified.
The trick is that if I put this script as a “run script” part inside my closing goal dependency evaluation works nice. The script solely runs when the dependencies are up to date. Nonetheless if I put the “run script” part into an mixture goal then add it as a Goal Dependency in the principle goal Xcode needs to run the script each time. No matter if the dependencies have modified. Nonetheless for those who construct simply the mixture goal alone every little thing goes simply superb. It solely builds when it has to.
To me this doesn’t fairly make sense. I assumed that dependency evaluation of the script inside my mixture goal can be the identical no matter whether or not that script was throughout the mixture goal or the principle goal.
In my app I ideally want the mixture goal to be shared by a number of different targets. Whereas I may put the script in every it might be extra foolproof to have them share an mixture goal.
Why would dependency evaluation come to a special conclusion when the script is inside an mixture goal that could be a goal dependency of the principle goal?
If it helps right here is the script and your entire venture could be discovered right here on GitHub if you need to play with it.
mkdir -p "${SCRIPT_OUTPUT_FILE_0}/construct/"
echo "Pausing for 10 seconds earlier than creating information..."
sleep 10
cat "${SCRIPT_INPUT_FILE_0}"
cat > "${SCRIPT_OUTPUT_FILE_0}/construct/index.html" << EOF
Easy Web page
Generated at: $(date)
EOF
cat > "${SCRIPT_OUTPUT_FILE_0}/construct/web page.html" << 'EOF'
Easy Web page
EOF
Enhancing Machine Studying Assurance with Portend

Information drift happens when machine studying fashions are deployed in environments that not resemble the information on which they had been educated. Because of this alteration, mannequin efficiency can deteriorate. For instance, if an autonomous unmanned aerial automobile (UAV) makes an attempt to visually navigate with out GPS over an space throughout inclement climate, the UAV could not be capable to efficiently maneuver if its coaching information is lacking climate phenomena equivalent to fog or rain.
On this weblog submit, we introduce Portend, a brand new open supply toolset from the SEI that simulates information drift in ML fashions and identifies the correct metrics to detect drift in manufacturing environments. Portend may also produce alerts if it detects drift, enabling customers to take corrective motion and improve ML assurance. This submit explains the toolset structure and illustrates an instance use case.
Portend Workflow
The Portend workflow consists of two phases: the information drift starting stage and the monitor choice stage. Within the information drift starting stage, a mannequin developer defines the anticipated drift situations, configures drift inducers that can simulate that drift, and measures the affect of that drift. The developer then makes use of these ends in the monitor choice stage to find out the thresholds for alerts.
Earlier than starting this course of, a developer should have already educated and validated an ML mannequin.
Information Drift Planning Stage
With a educated mannequin, a developer can then outline and generate drifted information and compute metrics to detect the induced drift. The Portend information drift stage consists of the next instruments and parts:
Drifter—a instrument that generates a drifted information set from a base information setPredictor—a element that ingests the drifted information set and calculates information drift metrics. The outputs are the mannequin predictions for the drifted information set.
Determine 1 under offers an summary of the information drift starting stage.
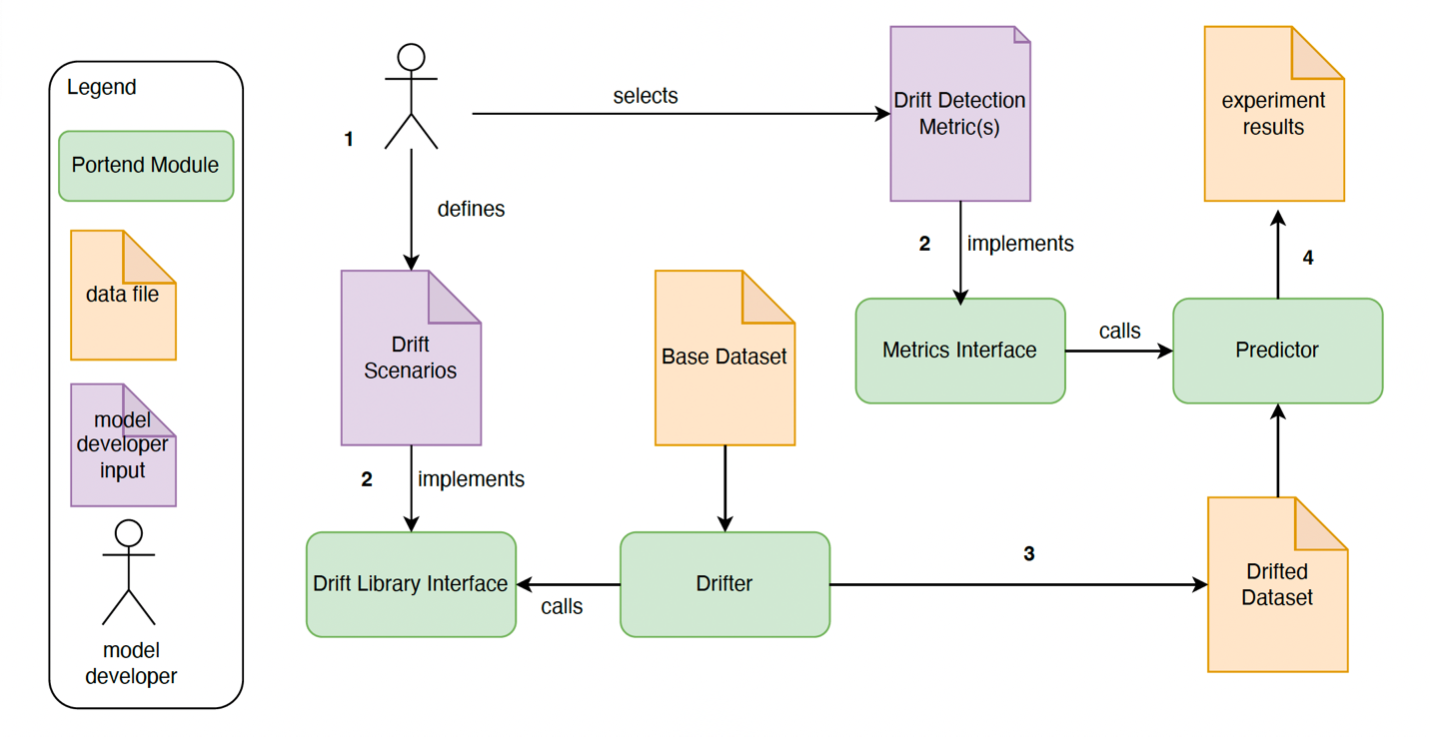{kind=link}

Determine 1: Portend information drift planning experiment workflow. In step 1, the mannequin developer selects drift induction and detection strategies primarily based on the issue area. In step 2, if these strategies should not presently supported within the Portend library, the developer creates and integrates new implementations. In step 3, the information drift induction technique(s) are utilized to provide the drifted information set. In step 4, the drifted information is offered to the Predictor to provide experimental outcomes.
The developer first defines the drift situations that illustrate how the information drift is more likely to have an effect on the mannequin. An instance is a situation the place a UAV makes an attempt to navigate over a identified metropolis, which has considerably modified how it’s seen from the air as a result of presence of fog. These situations ought to account for the magnitude, frequency, and period of a possible drift (in our instance above, the density of the fog). At this stage, the developer additionally selects the drift induction and detection strategies. The particular strategies rely on the character of the information used, the anticipated information drift, and the character of the ML mannequin. Whereas Portend helps plenty of drift simulations and detection metrics, a consumer may also add new performance if wanted.
As soon as these parameters are outlined, the developer makes use of the Drifter to generate the drifted information set. Utilizing this enter, the Predictor conducts an experiment by operating the mannequin on the drifted information and accumulating the drift detection metrics. The configurations to generate drift and to detect drift are impartial, and the developer can strive completely different combos to search out essentially the most acceptable ones to their particular situations.
Monitor Choice Stage
On this stage, the developer makes use of the experimental outcomes from the drift starting stage to research the drift detection metrics and decide acceptable thresholds for creating alerts or different kinds of corrective actions throughout operation of the system. The objective of this stage is to create metrics that can be utilized to watch for information drift whereas the system is in use.
The Portend monitor choice stage consists of the next instruments:
Selector—a instrument that takes the enter of the planning experiments and produces a configuration file that features detection metrics and really helpful thresholdsMonitor—a element that can be embedded within the goal exterior system. TheMonitortakes the configuration file from theSelectorand sends alerts if it detects information drift.
Determine 2 under reveals an summary of the complete Portend instrument set.
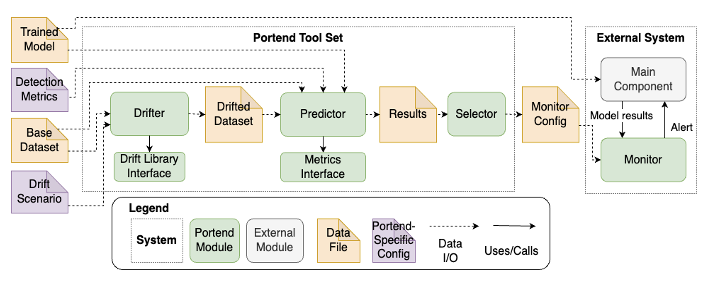{kind=link}
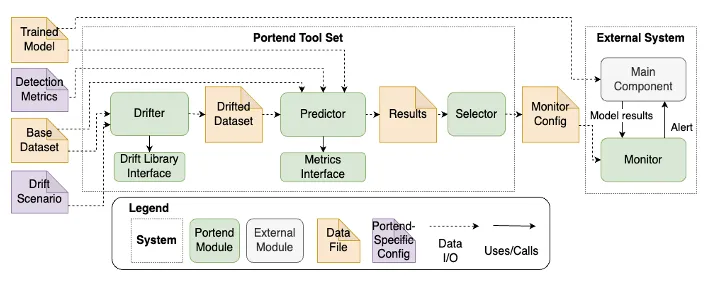
Determine 2: An outline of the Portend instrument set
Utilizing Portend
Returning to the UAV navigation situation talked about above, we created an instance situation as an instance Portend’s capabilities. Our objective was to generate a monitor for an image-based localization algorithm after which take a look at that monitor to see the way it carried out when new satellite tv for pc photos had been offered to the mannequin. The code for the situation is offered within the GitHub repository.
To start, we chosen a localization algorithm, Wildnav, and modified its code barely to permit for extra inputs, simpler integration with Portend, and extra sturdy picture rotation detection. For our base dataset, we used 225 satellite tv for pc photos from Fiesta Island, California that may be regenerated utilizing scripts obtainable in our repository.
With our mannequin outlined and base dataset chosen, we then specified our drift situation. On this case, we had been desirous about how the usage of overhead photos of a identified space, however with fog added to them, would have an effect on the efficiency of the mannequin. Utilizing a approach to simulate fog and haze in photos, we created drifted information units with the Drifter. We then chosen our detection metric, the common threshold confidence (ATC), due to its generalizability to utilizing ML fashions for classification duties. Primarily based on our experiments, we additionally modified the ATC metric to higher work with the sorts of satellite tv for pc imagery we used.
As soon as we had the drifted information set and our detection metric, we used the Predictor to find out our prediction confidence. In our case, we set a efficiency threshold of a localization error lower than or equal to 5 meters. Determine 3 illustrates the proportion of matching photos within the base dataset by drift extent.
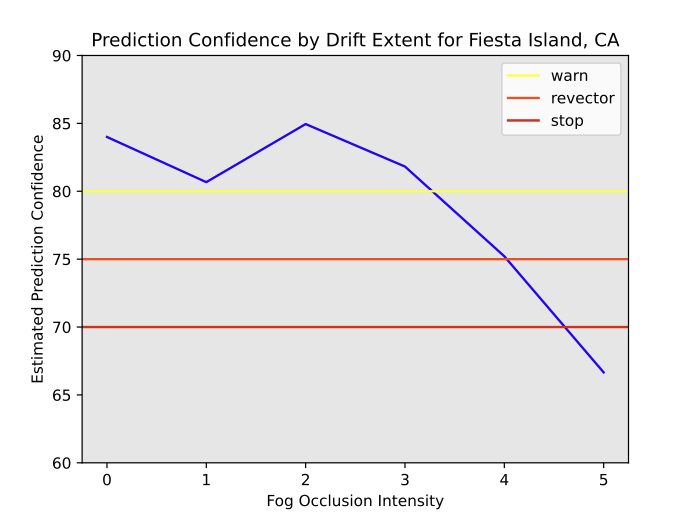{kind=link}
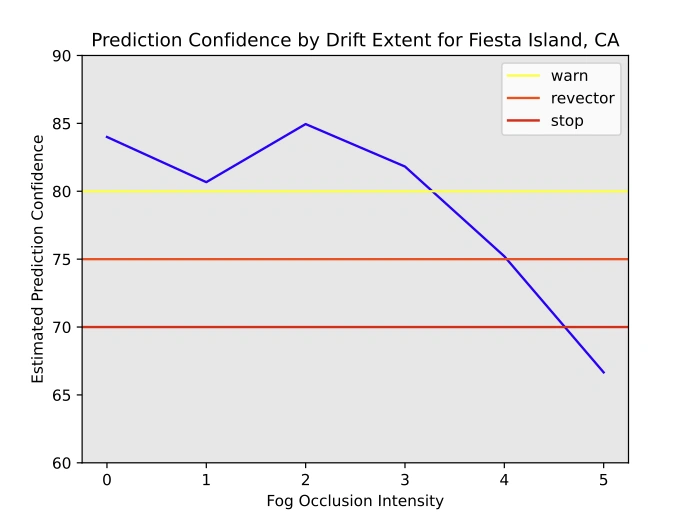
Determine 3: Prediction confidence by drift extent for 225 photos within the Fiesta Island, CA dataset with share of matching photos.
With these metrics in hand, we used the Selector to set thresholds for alert detection. In Determine 3, we will see three potential alert thresholds configured for this case, that can be utilized by the system or its operator to react in numerous methods relying on the severity of the drift. The pattern alert thresholds are warn to only warn the operator; revector, to counsel the system or operator to search out an alternate route; and cease, to suggest to cease the mission altogether.
Lastly, we carried out the ATC metric into the Monitor in a system that simulates UAV navigation. We ran simulated flights over Fiesta Island, and the system was in a position to detect areas of poor efficiency and log alerts in a approach that could possibly be offered to an operator. Which means that the metric was in a position to detect areas of poor mannequin efficiency in an space that the mannequin was in a roundabout way educated on and gives proof of idea for utilizing the Portend toolset for drift planning and operational monitoring.
Work with the SEI
We’re searching for suggestions on the Portend instrument. Portend presently comprises libraries to simulate 4 time collection situations and picture manipulation for fog and flood. The instrument additionally helps seven drift detection metrics that estimate change within the information distribution and one error-based metric (ATC). The instruments might be simply prolonged for overhead picture information however might be prolonged to help different information varieties as properly. Displays are presently supported in Python and might be ported to different programming languages. We additionally welcome contributions to float metrics and simulators.
Moreover, in case you are desirous about utilizing Portend in your group, our staff might help adapt the instrument on your wants. For questions or feedback, e-mail information@sei.cmu.edu or open a problem in our GitHub repository.
The Important Function of AISIRT in Flaw and Vulnerability Administration

The speedy enlargement of synthetic intelligence (AI) in recent times launched a brand new wave of safety challenges. The SEI’s preliminary examinations of those points revealed flaws and vulnerabilities at ranges above and past these of conventional software program. Some newsworthy vulnerabilities that got here to gentle that 12 months, such because the guardrail bypass to supply harmful content material, demonstrated the necessity for well timed motion and a devoted method to AI safety.
The SEI’s CERT Division has lengthy been on the forefront of enhancing the safety and resilience of rising applied sciences. In response to the rising dangers in AI, it took a big step ahead by establishing the primary Synthetic Intelligence Safety Incident Response Staff (AISIRT) in November 2023. The AISIRT was created to establish, analyze, and reply to AI-related incidents, flaws, and vulnerabilities—notably in techniques crucial to protection and nationwide safety.
Since then, we have now encountered a rising set of crucial points and rising assault strategies, akin to guardrail bypass (jailbreaking), information poisoning, and mannequin inversion. The growing quantity of AI safety points places shoppers, companies, and nationwide safety in danger. Given our long-standing experience in coordinating vulnerability disclosure throughout numerous applied sciences, increasing this effort to AI and AI-enabled techniques was a pure match. The scope and urgency of the issue now demand the identical stage of motion that has confirmed efficient in different domains. We lately collaborated with 33 consultants throughout academia, business, and authorities to emphasise the urgent want for higher coordination in managing AI flaws and vulnerabilities.
On this weblog publish, we offer background on AISIRT and what we have now been doing over the past 12 months, particularly in regard to coordination of flaws and vulnerabilities in AI techniques. As AISIRT evolves, we are going to proceed to replace you on our efforts throughout a number of fronts, together with community-reported AI incidents, development within the AI safety physique of data, and proposals for enchancment to AI and to AI-enabled techniques.
What Is AISIRT?
AISIRT on the SEI focuses on advancing the state-of-the-art in AI safety in rising areas akin to coordinating the disclosure of vulnerabilities and flaws in AI techniques, AI assurance, AI digital forensics and incident response, and AI red-teaming.
AISIRT’s preliminary goal is knowing and mitigating AI incidents, vulnerabilities, and flaws, particularly in protection and nationwide safety techniques. As we highlighted in our 2024 RSA Convention discuss, these vulnerabilities and flaws prolong past conventional cybersecurity points to incorporate adversarial machine studying threats and joint cyber-AI assaults. To deal with these challenges, we collaborate carefully with researchers at Carnegie Mellon College and SEI groups that target AI engineering, software program structure and cybersecurity rules. This collaboration extends to our huge coordination community of roughly 5,400 business companions, together with 4,400 distributors and 1,000 safety researchers, in addition to numerous authorities organizations.
The AISIRT’s coordination efforts builds on the longstanding work of the SEI’s CERT Division in dealing with the complete lifecycle of vulnerabilities—notably via coordinated vulnerability disclosure (CVD). CVD is a structured course of for gathering details about vulnerabilities, facilitating communication amongst related stakeholders, and guaranteeing accountable disclosure together with mitigation methods. AISIRT extends this method to what could also be thought-about as AI-specific flaws and vulnerabilities by integrating them into the CERT/CC Vulnerability Notes Database, which offers technical particulars, influence assessments, and mitigation steering for recognized software program and AI-related flaws and vulnerabilities.
Past vulnerability coordination, the SEI has spent over twenty years aiding organizations in establishing and managing Laptop Safety Incident Response Groups (CSIRTs), serving to to forestall and reply to cyber incidents. So far, the SEI has supported the creation of 22 CSIRTs worldwide. AISIRT builds upon this experience whereas approaching the novel safety dangers and complexities of AI techniques, thus additionally maturing and enabling CSIRTs to safe such nascent applied sciences of their framework.
Since its institution in November 2023, AISIRT has acquired over 103 community-reported AI vulnerabilities and flaws. After thorough evaluation, 12 of those instances met the standards for CVD. We’ve got revealed six vulnerability notes detailing findings and mitigations, marking a crucial step in documenting and formalizing AI vulnerability and flaw coordination.
Actions on the Rising AISIRT
In a current SEI podcast, we explored why AI safety incident response groups are needed, highlighting the complexity of AI techniques, their provide chains, and the emergence of recent vulnerabilities throughout the AI stack (encompassing software program frameworks, cloud platforms, and interfaces). Not like conventional software program, the AI stack consists of a number of interconnected layers, every introducing distinctive safety dangers. As outlined in a current SEI white paper, these layers embrace:
- computing and gadgets—the foundational applied sciences, together with programming languages, working techniques, and {hardware} that help AI techniques with their distinctive utilization of GPUs and their API interfaces.
- large information administration—the processes of choosing, analyzing, making ready, and managing information utilized in AI coaching and operations, which incorporates coaching information, fashions, metadata and their ephemeral attributes.
- machine studying—encompasses supervised, unsupervised, and reinforcement studying approaches that present a natively probabilistic algorithms important to such strategies.
- modeling—the structuring of data to synthesize uncooked information into higher-order ideas that basically combines information and its processing code in advanced methods.
- choice help—how AI fashions contribute to decision-making processes in adaptive and dynamic methods.
- planning and performing—the collaboration between AI techniques and people to create and execute plans, offering predictions and driving actionable choices.
- autonomy and human/AI interplay—the spectrum of engagement the place people delegate actions to AI, together with AI offering autonomous choice help.
Every layer presents potential flaws and vulnerabilities, making AI safety inherently advanced. Listed below are three examples from the quite a few AI-specific flaws and vulnerabilities that AISIRT has coordinated, together with their outcomes:
- guardrail bypass vulnerability: After a person reported a big language mannequin (LLM) guardrail bypass vulnerability, AISIRT engaged OpenAI to handle the difficulty. Working with ChatGPT builders, we ensured mitigation measures had been put in place, notably to forestall time-based jailbreak assaults.
- GPU API vulnerability: AI techniques depend on specialised {hardware} with particular utility program interfaces (API) and software program improvement kits (SDK), which introduces distinctive dangers. For example, the LeftoverLocals vulnerability allowed attackers to make use of a GPU-specific API to take advantage of reminiscence leaks to extract LLM responses, probably exposing delicate info. AISIRT labored with stakeholders, resulting in an replace within the Khronos customary to mitigate future dangers in GPU reminiscence administration.
- command injection vulnerability: These vulnerabilities, a subset of immediate injection vulnerabilities, primarily goal AI environments that settle for person inputs within the type of chatbots or AI brokers. A malicious person can benefit from the chat immediate to inject malicious code or different undesirable instructions, which may compromise the AI surroundings and even the complete system. One such vulnerability was reported to AISIRT by safety researchers at Nvidia. AISIRT collaborated with the seller to implement safety measures via coverage updates and using acceptable sandbox environments to guard in opposition to such threats.
Multi-Celebration Coordination Is Important in AI
The advanced AI provide chain and the transferability of flaws and vulnerabilities throughout vendor fashions demand coordinated, multi-party efforts, referred to as multi-party CVD (MPCVD). Addressing AI flaws and vulnerabilities utilizing MPCVD has additional proven that the coordination requires participating not simply AI distributors, but additionally key entities within the AI provide chain, akin to
- information suppliers and curators
- open supply libraries and frameworks
- mannequin hubs and distribution platforms
- third-party AI distributors
A strong AISIRT performs a crucial function in navigating these complexities, guaranteeing flaws and vulnerabilities are successfully recognized, analyzed, and mitigated throughout the AI ecosystem.
AISIRT’s Coordination Workflow and How You Can Contribute
At present, AISIRT receives flaw and vulnerability reviews from the group via the CERT/CC’s web-based platform for software program vulnerability reporting and coordination, often known as the Vulnerability Info and Coordination Setting (VINCE). The VINCE reporting course of captures the AI Flaw Report Card, guaranteeing that key info—akin to the character of the flaw, impacted techniques, and potential mitigations—is captured for efficient coordination.
AISIRT is actively shaping the way forward for AI safety, however we can’t do it alone. We invite you to hitch us on this mission, bringing your experience to work alongside AISIRT and safety professionals worldwide. Whether or not you’re a vendor, safety researcher, mannequin supplier, or service operator, your participation in coordinated flaw and vulnerability disclosure strengthens AI safety and drives the maturity wanted to guard these evolving applied sciences. AI-enabled software program can’t be thought-about safe till it undergoes strong CVD practices, simply as we have now seen in conventional software program safety.
Be a part of us in constructing a safer AI ecosystem. Report vulnerabilities, collaborate on fixes, and assist form the way forward for AI safety. Whether or not you might be constructing an AISIRT or augmenting your AI safety wants with us via VINCE, the SEI is right here to accomplice with you.
ios – Viewing Frustum utilizing ARKit
I’ve been making an attempt to calculate and visualize frustum in SwiftUI utilizing ARKit for a number of days now, however to no avail. I’ve been utilizing the next code
// This perform handles a faucet gesture to provoke the frustum calculation
@objc func handleTap(_ sender: UITapGestureRecognizer? = nil) {
guard let arView = sender?.view as? ARView,
let tapLocation = sender?.location(in: arView) else {
print("Faucet or ARView not discovered")
return
}
// Get the present digicam place from ARKit
if let currentFrame = arView.session.currentFrame {
calculateFOVAndFrustum(body: currentFrame, remodel: currentFrame.digicam.remodel, arView: arView)
}
}
func calculateFOVAndFrustum(body: ARFrame, remodel: simd_float4x4, arView: ARView) {
let intrinsics = body.digicam.intrinsics
let fx = intrinsics[0, 0]
let fy = intrinsics[1, 1]
let imageWidth = Float(body.digicam.imageResolution.width)
let imageHeight = Float(body.digicam.imageResolution.peak)
let aspectRatio = imageWidth / imageHeight
// Calculate FOV
let verticalFOV = 2 * atan(imageHeight / (2 * fy))
let horizontalFOV = 2 * atan(imageWidth / (2 * fx))
let nearDistance: Float = 0.03
let farDistance: Float = 0.1
let nearHeight = 2 * tan(verticalFOV / 2) * nearDistance
let farHeight = 2 * tan(verticalFOV / 2) * farDistance
let nearWidth = nearHeight * aspectRatio
let farWidth = farHeight * aspectRatio
print("Place: (remodel.getPosition())")
print("Rotation: (remodel.getRotation())")
// Get digicam place and orientation from the remodel
let camPos = SIMD3(remodel.columns.3.x,
remodel.columns.3.y,
remodel.columns.3.z)
// Digital camera axes in ARKit (ahead is -Z)
let camForward = -SIMD3(remodel.columns.2.x,
remodel.columns.2.y,
remodel.columns.2.z)
let camUp = SIMD3(remodel.columns.1.x,
remodel.columns.1.y,
remodel.columns.1.z)
let camRight = SIMD3(remodel.columns.0.x,
remodel.columns.0.y,
remodel.columns.0.z)
print("Cam Pos: (camPos)")
print("Cam Ahead: (camForward)")
print("Cam Up: (camUp)")
print("Cam Proper: (camRight)")
// Calculate facilities (in entrance of digicam)
let nearCenter = camPos + camForward * nearDistance
let farCenter = camPos + camForward * farDistance
// Calculate frustum corners
let farTopLeft = farCenter + (camUp * (farHeight * 0.5)) - (camRight * (farWidth * 0.5))
let farTopRight = farCenter + (camUp * (farHeight * 0.5)) + (camRight * (farWidth * 0.5))
let farBottomLeft = farCenter - (camUp * (farHeight * 0.5)) - (camRight * (farWidth * 0.5))
let farBottomRight = farCenter - (camUp * (farHeight * 0.5)) + (camRight * (farWidth * 0.5))
let nearTopLeft = nearCenter + (camUp * (nearHeight * 0.5)) - (camRight * (nearWidth * 0.5))
let nearTopRight = nearCenter + (camUp * (nearHeight * 0.5)) + (camRight * (nearWidth * 0.5))
let nearBottomLeft = nearCenter - (camUp * (nearHeight * 0.5)) - (camRight * (nearWidth * 0.5))
let nearBottomRight = nearCenter - (camUp * (nearHeight * 0.5)) + (camRight * (nearWidth * 0.5))
visualizeFrustumPlanes(
corners: [nearTopLeft, nearTopRight, nearBottomLeft, nearBottomRight,
farTopLeft, farTopRight, farBottomLeft, farBottomRight],
nearCenter: nearCenter,
farCenter: farCenter,
arView: arView
)
}
// This perform creates and visualizes the frustum planes, and likewise the close to and much facilities as spheres within the AR scene
func visualizeFrustumPlanes(corners: [SIMD3], nearCenter: SIMD3, farCenter: SIMD3, arView: ARView) {
// Outline the aircraft supplies
let nearPlaneMaterial = SimpleMaterial(shade: .blue, isMetallic: true) // Close to aircraft (blue)
let farPlaneMaterial = SimpleMaterial(shade: .crimson, isMetallic: true) // Far aircraft (crimson)
let sidePlaneMaterial = SimpleMaterial(shade: .inexperienced, isMetallic: true) // Facet planes (inexperienced)
// Outline the sphere materials for the facilities
let centerMaterial = SimpleMaterial(shade: .yellow, isMetallic: true) // Yellow for facilities
let centerMaterial2 = SimpleMaterial(shade: .inexperienced, isMetallic: true) // Yellow for facilities
// Create a small sphere mesh for visualization
let sphereMesh = MeshResource.generateSphere(radius: 0.01)
// Create ModelEntities for close to and much facilities (visualize them as spheres)
let nearCenterEntity = ModelEntity(mesh: sphereMesh, supplies: [centerMaterial])
nearCenterEntity.place = nearCenter
let farCenterEntity = ModelEntity(mesh: sphereMesh, supplies: [centerMaterial2])
farCenterEntity.place = farCenter
let nearCenterAnchor = AnchorEntity(world: nearCenter)
nearCenterAnchor.addChild(nearCenterEntity, preservingWorldTransform: true)
let farCenterAnchor = AnchorEntity(world: farCenter)
farCenterAnchor.addChild(farCenterEntity, preservingWorldTransform: true)
arView.scene.addAnchor(nearCenterAnchor)
arView.scene.addAnchor(farCenterAnchor)
}
The issue is that when i attempt to visualize the frustum NEAR and FAR facilities, they seem accurately in heart of what my system digicam can see when it comes to close to and much viewing distance, BUT after the primary body every time i attempt to change my digicam orientation the NEAR and FAR heart factors do get positioned in world house however not within the view of WHAT MY CAMERA IS SEEING.
I might actually respect if anyone may also help me with it.
I count on the NEAR and FAR facilities of the frustum to seem on this planet house however within the view of what my digicam is definitely seeing.