[long-reading] I am struggling to get the working DHCP/subscriber administration connectivity on a Juniper MX router. Presently I used to be in a position to determine the working configuration for the DHCP pool to assign IP addresses to purchasers, however then I am caught on the IP connectivity points.
This enables MX to efficiently present IP addresses on vlan 16 and one-directional connectivity for vlan 16 DHCP-enabled gadgets:
> present dhcp server binding
IP handle Session Id {Hardware} handle Expires State Interface
10.10.17.175 13930 00:1a:e8:23:99:1c 583 BOUND ge-1/0/0.16
10.10.17.174 13928 00:1b:0c:db:d1:6d 373 BOUND ge-1/0/0.16
10.10.17.169 13931 00:50:56:91:8a:6b 497 BOUND ge-1/0/0.16
10.10.17.170 13929 34:64:a9:69:06:4d 580 BOUND ge-1/0/0.16
What remains to be non-functional, is the bidirectional connectivity to those hosts: I am shocked to see, that, for example 10.10.17.169 is ready to ping any host in LAN or WAN efficiently, however this works just for DHCP-client-originating IP periods ! Au contraire, when some host in my LAN pings 10.10.17.169 and the seeion goes by way of the MX, the ICMP reply packets are misplaced on the MX. I’ve put in wireshark on 10.10.17.169 and the bizarre factor is that I can see pairs of ICMP-request/ICMP-reply in all of the instances mentioned – when 10.10.17.169 sends ICMP to, for instance, 10.10.10.2, and when 10.10.10.2 (a bunch subsequent to MX) sends ICMP to 10.10.17.169, however ICMP replies are seen solely when 10.10.17.169 initiates ICMP, – when 10.10.10.2 sends ICMP, it by no means will get ICMP replies.
I believe thats in all probability as a result of subscriber routes do look peculiar:
inet.0: 994598 locations, 1977204 routes (105 lively, 0 holddown, 1977094 hidden)
+ = Lively Route, - = Final Lively, * = Each
10.10.17.169/32 *[Access-internal/12] 04:54:10
Personal unicast
I can see that every subcriber has it is personal dynamic interfaces related:
I supposed that rpoxy arp may clear up this, and, as you possibly can see above, I’ve it configured above, however nonetheless the connectivity is pseudo-unidirectional.
Hey there, everybody, and welcome to the most recent installment of “Hank shares his AI journey.” 🙂 Synthetic Intelligence (AI) continues to be all the fashion, and getting back from Cisco Reside in San Diego, I used to be excited to dive into the world of agentic AI.
With bulletins like Cisco’s personal agentic AI resolution, AI Canvas, in addition to discussions with companions and different engineers about this subsequent section of AI potentialities, my curiosity was piqued: What does this all imply for us community engineers? Furthermore, how can we begin to experiment and find out about agentic AI?
I started my exploration of the subject of agentic AI, studying and watching a variety of content material to achieve a deeper understanding of the topic. I gained’t delve into an in depth definition on this weblog, however listed here are the fundamentals of how I give it some thought:
Agentic AI is a imaginative and prescient for a world the place AI doesn’t simply reply questions we ask, however it begins to work extra independently. Pushed by the objectives we set, and using entry to instruments and methods we offer, an agentic AI resolution can monitor the present state of the community and take actions to make sure our community operates precisely as meant.
Sounds fairly darn futuristic, proper? Let’s dive into the technical points of the way it works—roll up your sleeves, get into the lab, and let’s be taught some new issues.
What are AI “instruments?”
The very first thing I needed to discover and higher perceive was the idea of “instruments” inside this agentic framework. As it’s possible you’ll recall, the LLM (massive language mannequin) that powers AI methods is basically an algorithm educated on huge quantities of knowledge. An LLM can “perceive” your questions and directions. On its personal, nonetheless, the LLM is restricted to the information it was educated on. It could actually’t even search the online for present film showtimes with out some “device” permitting it to carry out an online search.
From the very early days of the GenAI buzz, builders have been constructing and including “instruments” into AI purposes. Initially, the creation of those instruments was advert hoc and different relying on the developer, LLM, programming language, and the device’s objective. However lately, a brand new framework for constructing AI instruments has gotten a whole lot of pleasure and is beginning to develop into a brand new “customary” for device improvement.
This framework is called the Mannequin Context Protocol (MCP). Initially developed by Anthropic, the corporate behind Claude, any developer to make use of MCP to construct instruments, referred to as “MCP Servers,” and any AI platform can act as an “MCP Shopper” to make use of these instruments. It’s important to do not forget that we’re nonetheless within the very early days of AI and AgenticAI; nonetheless, presently, MCP seems to be the strategy for device constructing. So I figured I’d dig in and determine how MCP works by constructing my very own very primary NetAI Agent.
I’m removed from the primary networking engineer to need to dive into this area, so I began by studying a few very useful weblog posts by my buddy Kareem Iskander, Head of Technical Advocacy in Study with Cisco.
These gave me a jumpstart on the important thing matters, and Kareem was useful sufficient to offer some instance code for creating an MCP server. I used to be able to discover extra alone.
Creating an area NetAI playground lab
There isn’t a scarcity of AI instruments and platforms at this time. There’s ChatGPT, Claude, Mistral, Gemini, and so many extra. Certainly, I make the most of lots of them recurrently for varied AI duties. Nonetheless, for experimenting with agentic AI and AI instruments, I needed one thing that was 100% native and didn’t depend on a cloud-connected service.
A main purpose for this want was that I needed to make sure all of my AI interactions remained fully on my laptop and inside my community. I knew I’d be experimenting in a wholly new space of improvement. I used to be additionally going to ship information about “my community” to the LLM for processing. And whereas I’ll be utilizing non-production lab methods for all of the testing, I nonetheless didn’t like the concept of leveraging cloud-based AI methods. I’d really feel freer to be taught and make errors if I knew the chance was low. Sure, low… Nothing is totally risk-free.
Fortunately, this wasn’t the primary time I thought-about native LLM work, and I had a few potential choices able to go. The primary is Ollama, a robust open-source engine for working LLMs domestically, or no less than by yourself server. The second is LMStudio, and whereas not itself open supply, it has an open supply basis, and it’s free to make use of for each private and “at work” experimentation with AI fashions. After I learn a current weblog by LMStudio about MCP help now being included, I made a decision to provide it a attempt for my experimentation.
Creating Mr Packets with LMStudio
LMStudio is a shopper for working LLMs, however it isn’t an LLM itself. It gives entry to a lot of LLMs obtainable for obtain and working. With so many LLM choices obtainable, it may be overwhelming once you get began. The important thing issues for this weblog submit and demonstration are that you simply want a mannequin that has been educated for “device use.” Not all fashions are. And moreover, not all “tool-using” fashions truly work with instruments. For this demonstration, I’m utilizing the google/gemma-2-9b mannequin. It’s an “open mannequin” constructed utilizing the identical analysis and tooling behind Gemini.
The following factor I wanted for my experimentation was an preliminary thought for a device to construct. After some thought, I made a decision a superb “hiya world” for my new NetAI challenge can be a method for AI to ship and course of “present instructions” from a community system. I selected pyATS to be my NetDevOps library of alternative for this challenge. Along with being a library that I’m very conversant in, it has the advantage of computerized output processing into JSON via the library of parsers included in pyATS. I may additionally, inside simply a few minutes, generate a primary Python operate to ship a present command to a community system and return the output as a place to begin.
Right here’s that code:
def send_show_command(
command: str,
device_name: str,
username: str,
password: str,
ip_address: str,
ssh_port: int = 22,
network_os: Non-compulsory[str] = "ios",
) -> Non-compulsory[Dict[str, Any]]:
# Construction a dictionary for the system configuration that may be loaded by PyATS
device_dict = {
"units": {
device_name: {
"os": network_os,
"credentials": {
"default": {"username": username, "password": password}
},
"connections": {
"ssh": {"protocol": "ssh", "ip": ip_address, "port": ssh_port}
},
}
}
}
testbed = load(device_dict)
system = testbed.units[device_name]
system.join()
output = system.parse(command)
system.disconnect()
return output
Between Kareem’s weblog posts and the getting-started information for FastMCP 2.0, I realized it was frighteningly simple to transform my operate into an MCP Server/Instrument. I simply wanted so as to add 5 traces of code.
from fastmcp import FastMCP
mcp = FastMCP("NetAI Hey World")
@mcp.device()
def send_show_command()
.
.
if __name__ == "__main__":
mcp.run()
Effectively.. it was ALMOST that simple. I did should make a number of changes to the above fundamentals to get it to run efficiently. You possibly can see the full working copy of the code in my newly created NetAI-Studying challenge on GitHub.
As for these few changes, the adjustments I made had been:
A pleasant, detailed docstring for the operate behind the device. MCP purchasers use the small print from the docstring to know how and why to make use of the device.
After some experimentation, I opted to make use of “http” transport for the MCP server quite than the default and extra frequent “STDIO.” The explanation I went this fashion was to arrange for the subsequent section of my experimentation, when my pyATS MCP server would seemingly run throughout the community lab surroundings itself, quite than on my laptop computer. STDIO requires the MCP Shopper and Server to run on the identical host system.
So I fired up the MCP Server, hoping that there wouldn’t be any errors. (Okay, to be trustworthy, it took a few iterations in improvement to get it working with out errors… however I’m doing this weblog submit “cooking present model,” the place the boring work alongside the best way is hidden. 😉
The following step was to configure LMStudio to behave because the MCP Shopper and connect with the server to have entry to the brand new “send_show_command” device. Whereas not “standardized, “most MCP Purchasers use a really frequent JSON configuration to outline the servers. LMStudio is certainly one of these purchasers.
Including the pyATS MCP server to LMStudio
Wait… if you happen to’re questioning, ‘Wright here’s the community, Hank? What system are you sending the ‘present instructions’ to?’ No worries, my inquisitive good friend: I created a quite simple Cisco Modeling Labs (CML) topology with a few IOL units configured for direct SSH entry utilizing the PATty function.
NetAI Hey World CML Community
Let’s see it in motion!
Okay, I’m certain you’re able to see it in motion. I do know I certain was as I used to be constructing it. So let’s do it!
To begin, I instructed the LLM on how to hook up with my community units within the preliminary message.
Telling the LLM about my units
I did this as a result of the pyATS device wants the deal with and credential data for the units. Sooner or later I’d like to take a look at the MCP servers for various supply of reality choices like NetBox and Vault so it could “look them up” as wanted. However for now, we’ll begin easy.
First query: Let’s ask about software program model information.
You possibly can see the small print of the device name by diving into the enter/output display.
That is fairly cool, however what precisely is going on right here? Let’s stroll via the steps concerned.
The LLM shopper begins and queries the configured MCP servers to find the instruments obtainable.
I ship a “immediate” to the LLM to contemplate.
The LLM processes my prompts. It “considers” the completely different instruments obtainable and in the event that they is perhaps related as a part of constructing a response to the immediate.
The LLM determines that the “send_show_command” device is related to the immediate and builds a correct payload to name the device.
The LLM invokes the device with the correct arguments from the immediate.
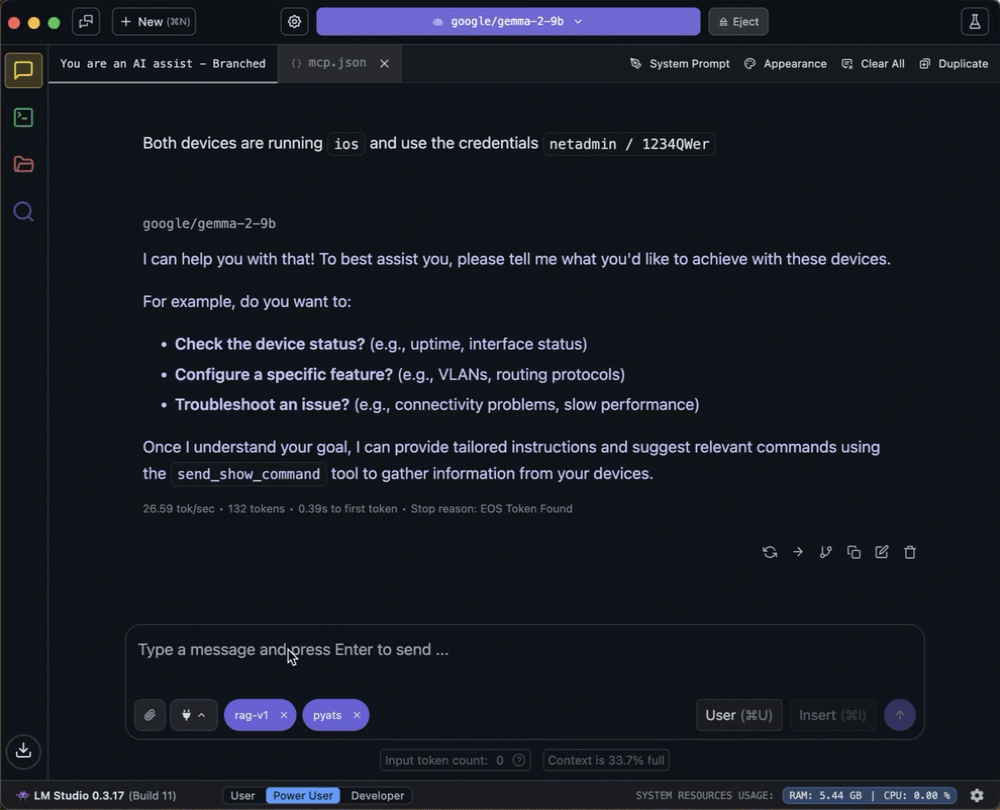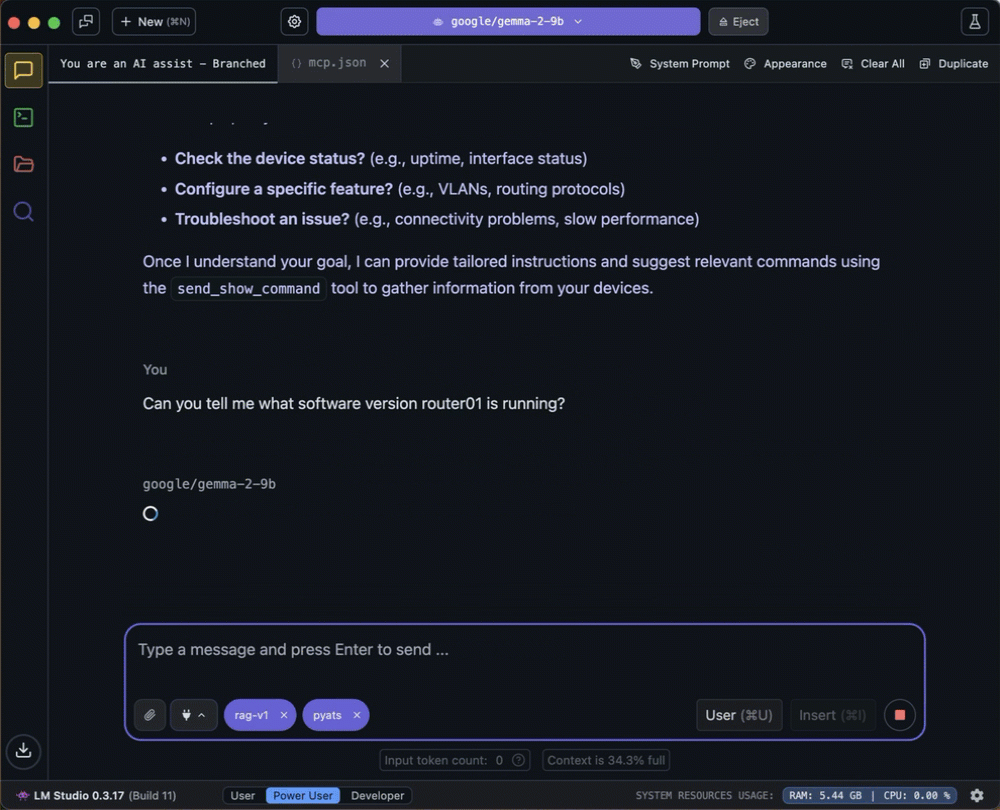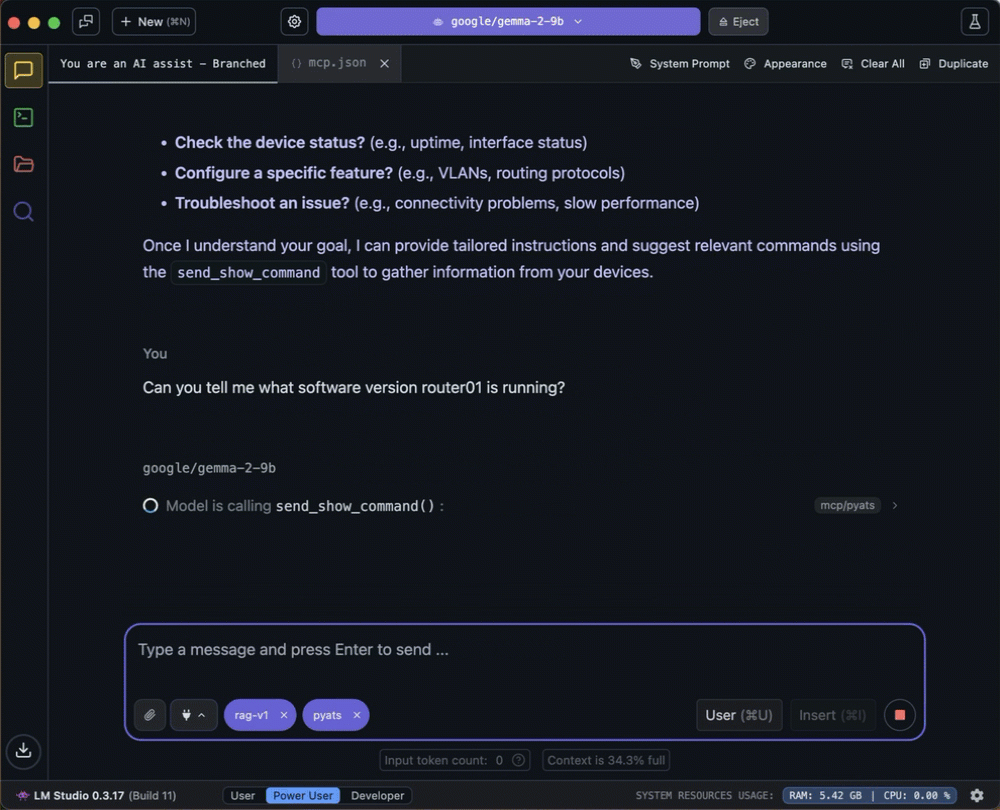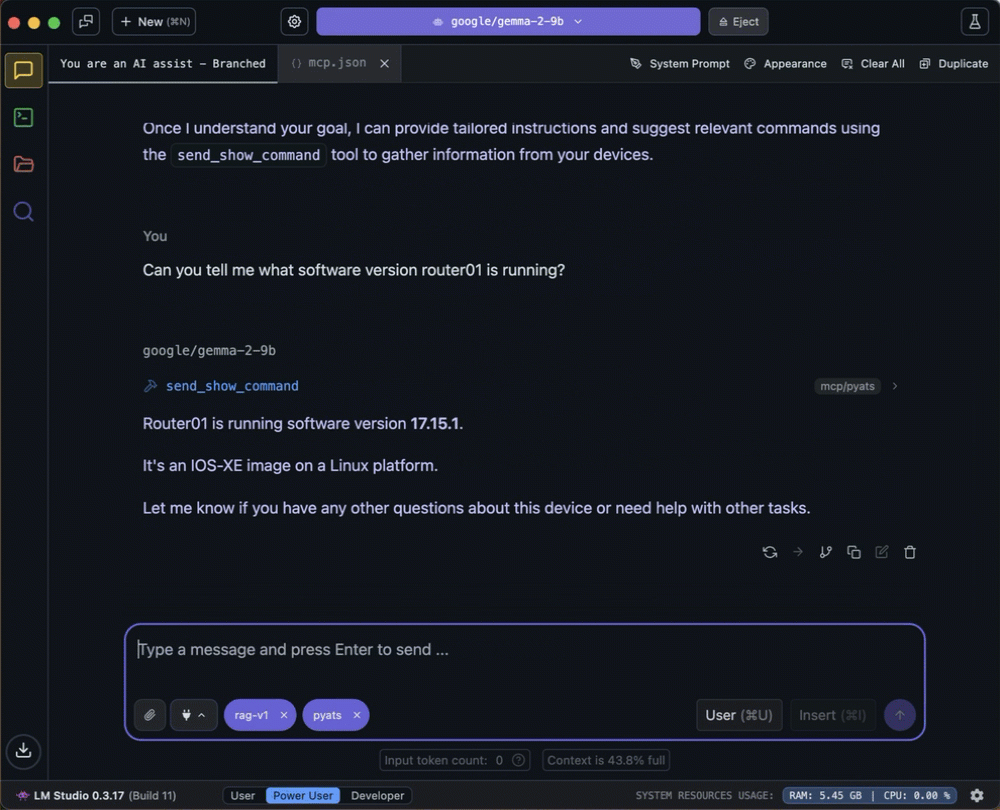
The MCP server processes the referred to as request from the LLM and returns the consequence.
The LLM takes the returned outcomes, together with the unique immediate/query as the brand new enter to make use of to generate the response.
The LLM generates and returns a response to the question.
This isn’t all that completely different from what you may do if you happen to had been requested the identical query.
You’d take into account the query, “What software program model is router01 working?”
You’d take into consideration the other ways you might get the knowledge wanted to reply the query. Your “instruments,” so to talk.
You’d determine on a device and use it to collect the knowledge you wanted. Most likely SSH to the router and run “present model.”
You’d assessment the returned output from the command.
You’d then reply to whoever requested you the query with the correct reply.
Hopefully, this helps demystify a bit of about how these “AI Brokers” work underneath the hood.
How about yet one more instance? Maybe one thing a bit extra complicated than merely “present model.” Let’s see if the NetAI agent can assist establish which swap port the host is related to by describing the essential course of concerned.
Right here’s the query—sorry, immediate, that I undergo the LLM:
Immediate asking a multi-step query of the LLM.
What we should always discover about this immediate is that it’ll require the LLM to ship and course of present instructions from two completely different community units. Identical to with the primary instance, I do NOT inform the LLM which command to run. I solely ask for the knowledge I would like. There isn’t a “device” that is aware of the IOS instructions. That data is a part of the LLM’s coaching information.
Let’s see the way it does with this immediate:
The LLM efficiently executes the multi-step plan.
And take a look at that, it was in a position to deal with the multi-step process to reply my query. The LLM even defined what instructions it was going to run, and the way it was going to make use of the output. And if you happen to scroll again as much as the CML community diagram, you’ll see that it accurately identifies interface Ethernet0/2 because the swap port to which the host was related.
So what’s subsequent, Hank?
Hopefully, you discovered this exploration of agentic AI device creation and experimentation as attention-grabbing as I’ve. And possibly you’re beginning to see the chances to your personal day by day use. In case you’d prefer to attempt a few of this out by yourself, you could find every little thing you want on my netai-learning GitHub challenge.
The mcp-pyats code for the MCP Server. You’ll discover each the straightforward “hiya world” instance and a extra developed work-in-progress device that I’m including further options to. Be at liberty to make use of both.
The CML topology I used for this weblog submit. Although any community that’s SSH reachable will work.
The mcp-server-config.json file that you would be able to reference for configuring LMStudio
A “System Immediate Library” the place I’ve included the System Prompts for each a primary “Mr. Packets” community assistant and the agentic AI device. These aren’t required for experimenting with NetAI use instances, however System Prompts will be helpful to make sure the outcomes you’re after with LLM.
A few “gotchas” I needed to share that I encountered throughout this studying course of, which I hope may prevent a while:
First, not all LLMs that declare to be “educated for device use” will work with MCP servers and instruments. Or no less than those I’ve been constructing and testing. Particularly, I struggled with Llama 3.1 and Phi 4. Each appeared to point they had been “device customers,” however they did not name my instruments. At first, I believed this was because of my code, however as soon as I switched to Gemma 2, they labored instantly. (I additionally examined with Qwen3 and had good outcomes.)
Second, when you add the MCP Server to LMStudio’s “mcp.json” configuration file, LMStudio initiates a connection and maintains an energetic session. Which means if you happen to cease and restart the MCP server code, the session is damaged, providing you with an error in LMStudio in your subsequent immediate submission. To repair this problem, you’ll must both shut and restart LMStudio or edit the “mcp.json” file to delete the server, reserve it, after which re-add it. (There’s a bug filed with LMStudio on this downside. Hopefully, they’ll repair it in an upcoming launch, however for now, it does make improvement a bit annoying.)
As for me, I’ll proceed exploring the idea of NetAI and the way AI brokers and instruments could make our lives as community engineers extra productive. I’ll be again right here with my subsequent weblog as soon as I’ve one thing new and attention-grabbing to share.
Within the meantime, how are you experimenting with agentic AI? Are you excited concerning the potential? Any options for an LLM that works nicely with community engineering data? Let me know within the feedback under. Speak to you all quickly!
The mannequin is Google’s quickest and least expensive mannequin, costing $0.10/1M tokens for enter and $0.40/1M tokens for output (in comparison with $1.25/1M tokens for enter and $10/1M tokens for output in Gemini 2.5 Professional).
“We constructed 2.5 Flash-Lite to push the frontier of intelligence per greenback, with native reasoning capabilities that may be optionally toggled on for extra demanding use instances. Constructing on the momentum of two.5 Professional and a couple of.5 Flash, this mannequin rounds out our set of two.5 fashions which are prepared for scaled manufacturing use,” Google wrote in a weblog publish.
GitLab Duo Agent Platform enters beta
GitLab Duo Agent Platform is an orchestration platform for AI brokers that work throughout DevSecOps in parallel. For example, a person might delegate a refactoring job to a Software program Developer Agent, have a Safety Analyst Agent scan for vulnerabilities, and have a Deep Analysis Agent analyze progress throughout the repository.
A few of the different brokers that GitLab is constructing as a part of this embrace a Chat Agent, Product Planning Agent, Software program Take a look at Engineer Agent, Code Reviewer Agent, Platform Engineer Agent, and Deployment Engineer Agent.
The primary beta is on the market for GitLab.com and self-managed GitLab Premium and Final clients. It features a VS Code extension and JetBrains IDEs plugins, and subsequent month the corporate plans so as to add it to GitLab and broaden IDE help.
Google provides up to date workspace templates in Firebase Studio that leverage new Agent mode
Google is including a number of new options to its cloud-based AI workspace Firebase Studio, following its replace a number of weeks in the past when it added new Agent modes, help for MCP, and integration with the Gemini CLI.
Now it’s asserting up to date workspace templates for Flutter, Angular, React, Subsequent.js, and common Net that use the Agent mode by default. Customers will nonetheless have the ability to toggle between the “Ask” and Agent mode, relying on what the duty at hand requires.
The templates now have an airules.md file to offer Gemini with directions for code technology, like particular coding requirements, dealing with strategies, dependencies, and improvement finest practices.
Google says it is going to be updating templates for frameworks like Go, Node.js, and .NET over the following few weeks as nicely.
ChatGPT now has an agent mode
OpenAI is bringing the ability of agentic AI to ChatGPT in order that it might deal with complicated requests from customers autonomously.
It leverages two of OpenAI’s present capabilities: Operator, which might work together with web sites, and deep analysis, which might synthesize data. In response to OpenAI, these capabilities have been finest suited to completely different conditions, with Operator scuffling with complicated evaluation and deep analysis being unable to work together with web sites to refine outcomes or entry content material that required authentication.
“By integrating these complementary strengths in ChatGPT and introducing extra instruments, we’ve unlocked fully new capabilities inside one mannequin. It might probably now actively interact web sites—clicking, filtering, and gathering extra exact, environment friendly outcomes. You may also naturally transition from a easy dialog to requesting actions instantly inside the identical chat,” the corporate wrote in a weblog publish.
YugabyteDB provides new capabilities for AI builders
The corporate added new vector search capabilities, an MCP Server, and built-in Connection Pooling to help tens of 1000’s of connections per node.
Moreover, it introduced help for LangChain, OLLama, LlamaIndex, AWS Bedrock, and Google Vortex AI. Lastly, YugabyteDB now has multi-modal API help with the addition of help for the MongoDB API.
“Immediately’s launch is one other key step in our quest to ship the database of selection for builders constructing mission-critical AI-powered purposes,” stated Karthik Ranganathan, co-founder and CEO, Yugabyte. “As we repeatedly improve YugabyteDB’s compatibility with PostgreSQL, the expanded multi-modal help, a brand new YugabyteDB MCP server, and wider integration with the AI ecosystem present AI app builders with the instruments and suppleness they want for future success.”
Composio raises $29 million in Collection A funding
The corporate is making an attempt to construct a shared studying layer for AI brokers in order that they’ll study from expertise. “You’ll be able to spend tons of of hours constructing LLM instruments, tweaking prompts, and refining directions, however you hit a wall,” stated Soham Ganatra, CEO of Composio. “These fashions don’t get higher at their jobs the way in which a human worker would. They will’t construct context, study from errors, or develop the refined understanding that makes human employees invaluable. We’re fixing this on the infrastructure stage.”
This funding spherical might be used to speed up the event of Composio’s studying infrastructure. The spherical was led by Lightspeed Enterprise Companions, with participation from Vercel’s CEO Guillermo Rauch, HubSpot’s CTO and founder Dharmesh Shah, investor Gokul Rajaram, Rubrik’s co-founder Soham Mazumdar, V Angel, Blitzscaling Ventures, Operator Companions, and Agent Fund by Yohei Nakajima, along with present traders Elevation Capital and Collectively Fund.
Parasoft brings agentic AI to service virtualization in newest launch
The corporate added an agentic AI assistant to its digital testing simulation resolution Virtualize, permitting clients to create digital providers utilizing pure language prompts.
For instance, a person might write the immediate: “Create a digital service for a fee processing API. There must be a POST and a GET operation. The operations ought to require an account id together with different knowledge associated to fee.”
The platform will then draw from the supplied API service definitions, pattern requests/responses, and written descriptions of a service to generate a digital service with dynamic conduct, parameterized responses, and the proper default values.
Are you maximizing your Cisco options? The ‘How I Cisco’ sequence showcases actual tales of organizations fixing huge challenges and driving spectacular outcomes with Cisco. After that includes United Airways’ journey to digital resilience, our subsequent story shifts gears to the world of motorsport.
The Excessive-Stakes World of Formulation 1 and McLaren Formulation 1 Crew
Enter the fast-paced world of Formulation 1 with the McLaren Formulation 1 Crew, a spot the place each second is pivotal and digital efficiency can affect the result of a race. At the McLaren’s Formula 1 Crew, success relies upon not solely on engineering brilliance but additionally on seamless know-how operations, high-speed connectivity and real-time visibility.
International Operations and Unrelenting Knowledge Calls for
With a world fan base and races spanning 5 continents, the McLaren Formulation 1 Crew operates in one of the vital demanding digital environments on this planet. Every race weekend, the workforce units up a trackside information heart that connects on tothe McLaren Expertise Centre in Woking, UK. The McLaren IT workforce manages the continual setup and deconstruction of this cellular information heart at totally different international places, adapting to unpredictable and ranging community circumstances at every racetrack. Throughout the Formulation 1 season, this cellular data heart is assembled and disassembled 24 instances, as soon as for every Grand Prix race.
Engineers and analysts depend on this infrastructure to course of and share huge volumes of information, between trackside operations and the McLaren Expertise Centre. The dimensions of this setup is substantial: the McLaren Formulation 1 Crew transmits roughly transmits roughly 2.3 TB of information between observe and manufacturing unit each race weekend. Of this, 1.5 terabytes are generated on the observe alone and transferred by means of a devoted 100 Mbps MPLS connection. In Formulation 1, any delay in information switch can imply the distinction between victory and defeat, making flawless information movement paramount.
Dan Keyworth, Director of Enterprise Expertise, McLaren Racing
Addressing Crucial Efficiency Wants with Cisco ThousandEyes
To deal with these crucial calls for, the McLaren Formulation 1 Crew enlisted Cisco ThousandEyes for assurance. Particularly, the McLaren Formulation 1 Crew deployed Enterprise Brokers inside its information heart connecting again to Mission Management, previous to the Montreal Grand Prix 2023. The setup course of was remarkably quick and environment friendly, taking solely a few hours, with fast outcomes.
Cisco ThousandEyes supplies full visibility into each hyperlink of the digital provide chain, from the circuit and paddock, throughout the Web, to the workforce’s headquarters. This degree of perception is essential for proactively figuring out and pinpointing the basis reason behind community or software efficiency points, permitting the McLaren Formulation 1 Crew to optimize efficiency and allow dependable digital experiences.
Key advantages the McLaren Formulation 1 Crew has realized with Cisco ThousandEyes:
Complete, Finish-to-Finish Visibility: Cisco ThousandEyes permits the McLaren Formulation 1 Crew to proactively monitor the efficiency of all crucial purposes, together with telemetry, video feeds, and collaboration platforms. The platform presents unprecedented perception into each owned and unowned networks by mapping dependencies throughout all the digital supply chain, from supply to consumer.
Quicker Troubleshooting: Earlier than Cisco ThousandEyes, diagnosing IT points at a race may take hours. Now, with real-time monitoring enhanced by path visualization, cross-domain correlation, and clear metrics highlighting the place degradation happens, the McLaren’s Formulation 1 Crew can rapidly pinpoint community bottlenecks and root causes. This allows them to resolve points inside minutes, minimizing disruption and sustaining concentrate on race operations.
Empowered Distant Operations: The hybrid work mannequin adopted by McLaren Racing Crew signifies that key personnel, together with engineers and strategists, usually work remotely. Cisco ThousandEyes helps keep a seamless digital expertise throughout international places, serving to guarantee no delay in crucial decision-making. That is particularly important for sustaining dependable community connections for distant operations by way of devoted MPLS networks.
One of many people behind these technological developments is Dan Keyworth, McLaren Racing’s Director of Enterprise Expertise, who leads the workforce’s technique throughout know-how infrastructure, structure, and real-time efficiency. His objective is to assist make sure that each piece of know-how capabilities easily with out interruption, whether or not within the manufacturing unit or on the racetrack. Hearken to him talk about how the McLaren Formulation 1 Crew makes use of Cisco ThousandEyes to attain this.
A Complete Cisco Digital Basis
Cisco ThousandEyes is a vital element of a bigger suite of Cisco applied sciences supporting the McLaren Formulation 1 Crew’s international operations. McLaren makes use of a complete digital basis powered by Cisco, together with:
AI-Prepared Knowledge Facilities: On the coronary heart of McLaren Formulation 1 Crew’s digital technique is an AI-capable information heart infrastructure which is supported by Cisco. Throughout the McLaren Expertise Centre, superior telemetry methods stream huge portions of information from the automobile in actual time. With AI perception and Cisco’s infrastructure, that information turns into actionable intelligence.
Seamless Collaboration: On the planet of Formulation 1, international teamwork is important. With employees and companions situated throughout totally different international locations, the McLaren Formulation 1 Crew makes use of Cisco’s safe and user-friendly collaboration platform Cisco Webex to operate as one cohesive unit. Whether or not engineers are working within the storage or from the McLaren Expertise Centre, Cisco Webex supplies easy video conferencing and messaging. Moreover, Cisco ThousandEyes helps make sure that collaboration platforms like Webex carry out reliably, particularly throughout races when each second counts.
Superior Cybersecurity: Past community efficiency, Cisco has additionally grow to be an Official Cybersecurity Accomplice of the McLaren Formulation 1 Crew. The McLaren Formulation 1 Crew makes use of Cisco Safety options, together with Cisco Safe Firewall,by means of a mix of on-premises {hardware} and cloud-based software program. Cisco Safe Firewall supplies end-to-end visibility, simplified safety administration, and community segmentation throughout the McLaren Formulation 1 Crew’s hybrid and distributed networks.
With Cisco enabling quick connectivity, fixed monitoring, and innovation, the McLaren Formulation 1 Crew continues to innovateeach on the observe and within the cloud.
That is how they Cisco.
Able to creator your personal “How I Cisco” story? Drop us a notice and we’ll join you with the Cisco dream workforce bringing these tales to life.
The report reveals that AI is being deployed sometimes in high-volume, repetitive duties. Troubleshooting and log evaluation prepared the ground, with 41% and 35% of sysadmins, respectively, reporting use of AI in these areas—up considerably from 2024.
Respondents reported that the next duties are almost definitely to be automated with AI within the subsequent two years:
Vulnerability prioritization: 67%
Monitoring of server CPU and reminiscence utilization: 67%
Detecting and remediating incidents: 66%
Patch administration processes: 66%
Safety controls and compliance evaluation: 65%
Performing post-incident evaluations: 57%
Offering IT employees with steerage and coaching: 55%
Troubleshooting: 55%
In distinction, sysadmins surveyed reported that the next duties are much less more likely to be automated with AI within the subsequent two years:
Managing SSO and passwords: 48%
Administering person permissions: 44%
Managing recordsdata: 38%
Defining system utilization insurance policies and procedures: 34%
Offering finish customers with first-level IT assist: 30%
Putting in and sustaining software program: 29%
Troubleshooting: 24%
Performing post-incident evaluations: 23% Offering IT employees with steerage and coaching: 23%
AI considerations persist
Sysadmins indicated they fear about falling behind friends. Some 40% expressed concern about being left behind by extra AI-literate friends, a slight enchancment from 45% in 2024. The highest three causes sysadmins are hesitant to embrace AI are:
79% fear about accuracy and reliability.
78% cite information privateness and safety dangers.
60% worry lack of management over automated actions.
As AI adoption will increase, so does the visibility of its shortcomings. Troubleshooting, the commonest use case, can also be the subject the place AI struggles probably the most—30% of sysadmins reported failures on this space, a determine that’s almost double from final yr’s survey. One other 20% of sysadmins stated AI implementations have brought on operational disruptions.
Different areas that present AI isn’t but performing as much as expectations are: log evaluation with 12% failure experiences, and first-level IT assist duties additionally with 12% citing it as an space for AI failures. Even assist for IT employees, comparable to coaching steerage, is falling brief for some customers as 10% cited this as an space during which AI has failed.









")




