Retrieval-Augmented Technology (RAG) is a framework that enhances language fashions by combining two important elements: Retriever and Generator. A RAG pipeline combines the retriever and generator in an iterative course of and is broadly utilized in open-domain question-answer, knowledge-based chatbots, and specialised data retrieval duties the place the accuracy and relevance of real-world knowledge are essential. Regardless of the supply of assorted RAG pipelines and modules, it’s troublesome to pick out which pipeline is nice for personal knowledge and personal use instances”. Furthermore, making and evaluating all RAG modules could be very time-consuming and laborious to do, however with out it, it’s troublesome to know which RAG pipeline is one of the best for the self-use case.
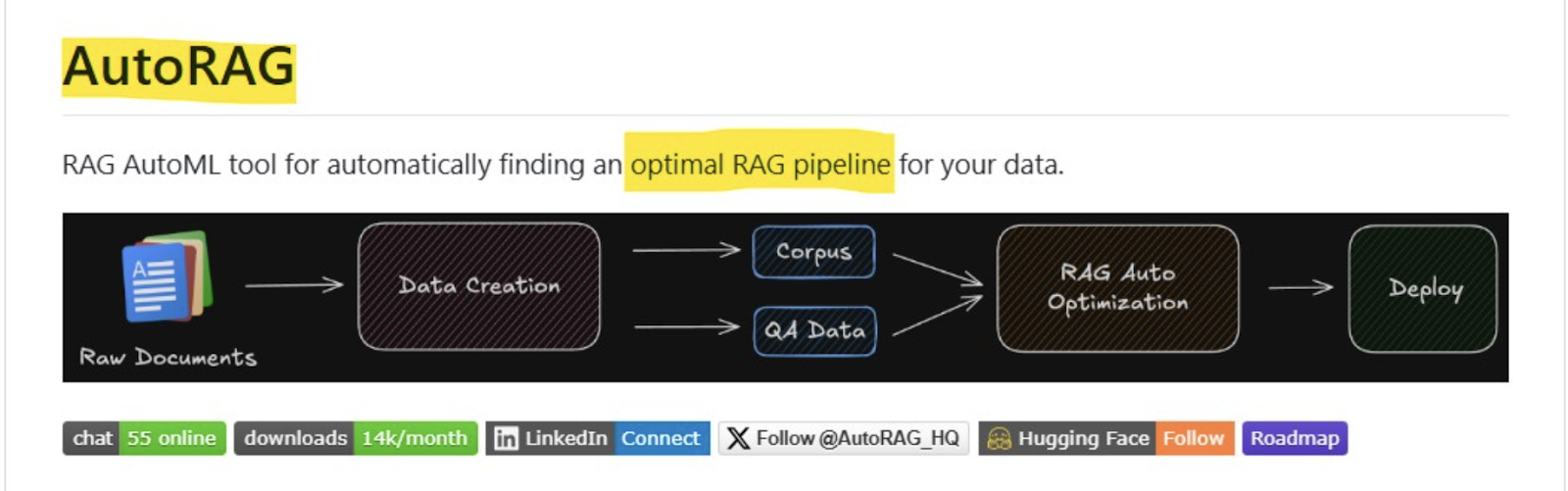
AutoRAG (𝐑𝐀𝐆 𝐀𝐮𝐭𝐨𝐌𝐋 𝐓𝐨𝐨𝐥) is a software for locating optimum RAG pipeline for “self knowledge.” It helps to robotically consider numerous RAG modules with self-evaluation knowledge and discover one of the best RAG pipeline for self-use instances. AutoRAG helps:
- Information Creation: Create RAG analysis knowledge with uncooked paperwork.
- Optimization: Mechanically run experiments to seek out one of the best RAG pipeline for the information.
- Deployment: Deploy one of the best RAG pipeline with a single YAML file and assist the Flask server as properly.
In optimization for a RAG pipeline, a node represents a selected perform, with the results of every node handed to the next node. The core nodes for an efficient RAG pipeline are retrieval, immediate maker, and generator, with further nodes out there to reinforce efficiency. AutoRAG achieves optimization by creating all doable mixtures of modules and parameters inside every node, executing the pipeline with every configuration, and deciding on the optimum consequence in accordance with predefined methods. The chosen consequence from the previous node then turns into the enter for the following, that means every node operates primarily based on one of the best consequence from its predecessor. Every node capabilities independently of how the enter result’s produced, much like a Markov Chain, the place solely the earlier state is required to generate the following state, with out information of the complete pipeline or previous steps.

RAG fashions want knowledge for analysis however most often, there may be little or no appropriate knowledge out there. Nonetheless, with the appearance of huge language fashions (LLMs), producing artificial knowledge has emerged as an efficient resolution to this problem. The next information outlines the best way to use LLMs to create knowledge in a format suitable with AutoRAG:
- Parsing: Set the YAML file and begin parsing. Right here, uncooked paperwork might be parsed with just some traces of code to organize the information.
- Chunking: A single corpus is used to create preliminary QA pairs, after which the remaining corpus is mapped to QA knowledge.
- QA Creation: Every corpus wants a corresponding QA dataset if a number of corpora are generated by means of totally different chunking strategies.
- QA-Corpus Mapping: For a number of corpora, the remaining corpus knowledge might be mapped to the QA dataset. To optimize chunking, RAG efficiency might be evaluated utilizing numerous corpus knowledge.
Sure nodes, resembling query_expansion or prompt_maker, can’t be evaluated instantly. To judge these nodes, it’s essential to ascertain floor fact values, such because the “floor fact of expanded question” or “floor fact of immediate.” On this methodology, paperwork are retrieved throughout the analysis course of utilizing the designated modules, and the query_expansion node is evaluated primarily based on these retrieved paperwork. An identical method applies to the prompt_maker and era nodes, the place the prompt_maker node is evaluated utilizing the outcomes from the era node. AutoRAG is at the moment in its alpha section with quite a few optimization potentialities for future improvement.
In conclusion, AutoRAG is an automatic software designed to determine the optimum RAG pipeline for particular datasets and use instances. It automates the analysis of assorted RAG modules utilizing self-evaluation knowledge, providing assist for knowledge creation, optimization, and deployment. Furthermore, AutoRAG constructions the pipeline into interconnected nodes (retrieval, immediate maker, and generator) and evaluates mixtures of modules and parameters to seek out one of the best configuration. Artificial knowledge from LLMs enhances analysis. Presently in its alpha section, AutoRAG provides vital potential for additional optimization and improvement in RAG pipeline choice and deployment.
Take a look at the GitHub Repo. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An In depth Assortment of Small Language Fashions (SLMs) for Intel PCs

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.