{kind=link}

Transformer-based Massive Language Fashions (LLMs) face important challenges in effectively processing lengthy sequences as a result of quadratic complexity of the self-attention mechanism. This can improve their computational and reminiscence calls for exponentially with sequence size, so scaling up these fashions to life like purposes like multi-document summarization, retrieval-based reasoning, and even fine-grained code evaluation on the repository stage proves unimaginable. Present approaches fail to handle sequences extending to hundreds of thousands of tokens with out appreciable computational overhead or loss in accuracy, which creates a serious impediment to their efficient deployment in various use circumstances.
Numerous methods have been proposed to handle these inefficiencies. Sparse consideration mechanisms are designed to cut back computational depth however usually fail to protect probably the most crucial international dependencies, leading to degraded activity efficiency. Strategies for enhancing reminiscence effectivity, similar to key-value cache compression and low-rank approximations, cut back useful resource utilization at the price of scalability and accuracy. Distributed methods such because the Ring Consideration enhance scalability by distributing computations throughout a number of units. Nevertheless, these approaches incur important communication overhead and thus restrict their effectiveness in extraordinarily lengthy sequences. Such limitations level to the pressing want for an revolutionary mechanism that may steadiness effectivity, scalability, and efficiency with accuracy.
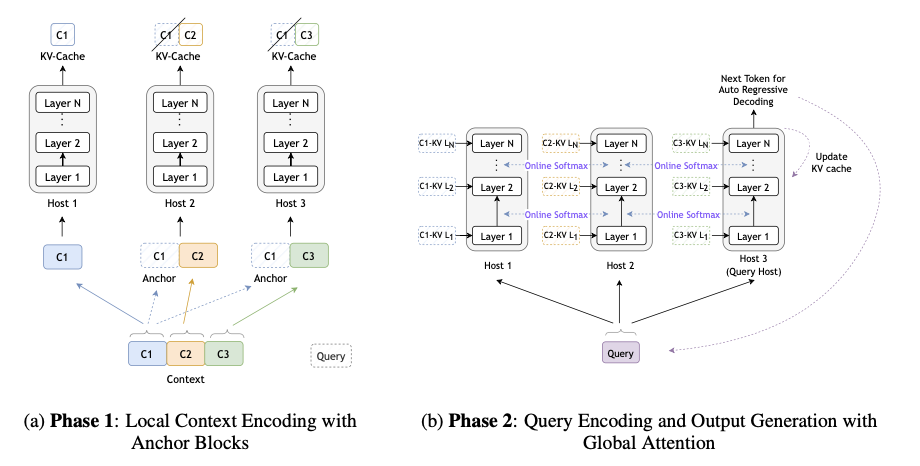
Researchers from NVIDIA launched Star Consideration, an revolutionary block-sparse consideration mechanism designed to handle these challenges. Star Consideration primarily breaks an enter sequence into smaller blocks, which is preceded by what researchers name an “anchor block,” which holds a lot data globally. Then blocks course of independently on many hosts to considerably cut back computation complexity with the aptitude to seize patterns globally. The inference processes mix the eye scores for every block utilizing a distributed softmax algorithm that allows environment friendly international consideration whereas minimizing the info transmission. The mixing of the mannequin with prior Transformer-based frameworks is non-intrusive and fine-tuning is just not necessary, making it a fairly sensible resolution to handle prolonged sequences in real-world apply. The technical basis of Star Consideration is a break up course of. Within the first part, context encoding, every enter block is augmented with an anchor block that ensures the mannequin captures international consideration patterns. After processing, key-value caches for anchor blocks are discarded to preserve reminiscence. Within the second part, question encoding, and token technology, consideration scores are computed domestically on every host and mixed by way of distributed softmax, permitting the mannequin to keep up computational effectivity and scalability.
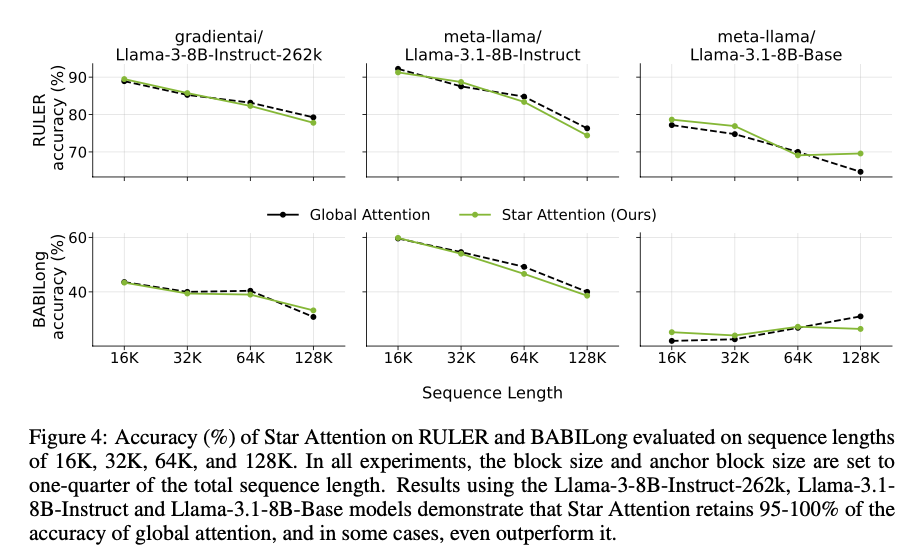
Star Consideration was evaluated on benchmarks similar to RULER, which incorporates retrieval and reasoning duties, and BABILong, which checks long-context reasoning. Over sequences between 16,000 to 1 million tokens lengthy, the fashions examined – Llama-3.1-8B and Llama-3.1-70B – are being examined, utilizing HuggingFace Transformers and the A100 GPU, which takes benefit of bfloat16 for max pace.
Star Consideration delivers important developments in each pace and accuracy. It achieves as much as 11 occasions quicker inference in comparison with baselines whereas sustaining 95-100% accuracy throughout duties. On the RULER benchmark, it shines in retrieval duties however its accuracy degrades by a mere 1-3% in additional complicated multi-hop reasoning eventualities. The BABILong benchmark targeted on testing reasoning over longer contexts, and the outcomes are at all times inside the 0-3% vary in contrast with the baseline. It’s additionally scalable as much as 1 million tokens sequence size, making it a robust and versatile candidate that adapts effectively to extremely sequence-dependent purposes.

Star Consideration establishes a transformative framework for environment friendly inference in Transformer-based LLMs, addressing key limitations in processing lengthy sequences. Block-sparse consideration plus anchor blocks strike the appropriate steadiness between computational effectivity and accuracy, enabling speedups with important efficiency preservation. This advance brings scalable, sensible options to a variety of AI purposes: reasoning, retrieval, and summarization. Future work will contain designing refinements to anchor mechanisms and bettering bottleneck efficiency in inter-block-communication-dependent duties with it.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 55k+ ML SubReddit.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s captivated with knowledge science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.