{kind=link}

Software program is a technique of speaking human intent to a machine. When builders write software program code, they’re offering exact directions to the machine in a language the machine is designed to grasp and reply to. For complicated duties, these directions can change into prolonged and troublesome to test for correctness and safety. Synthetic intelligence (AI) affords the choice chance of interacting with machines in methods which can be native to people: plain language descriptions of targets, spoken phrases, and even gestures or references to bodily objects seen to each the human and the machine. As a result of it’s so a lot simpler to explain complicated targets to an AI system than it’s to develop hundreds of thousands of traces of software program code, it’s not shocking that many individuals see the chance that AI methods may eat larger and larger parts of the software program world. Nevertheless, larger reliance on AI methods may expose mission house owners to novel dangers, necessitating new approaches to check and analysis.
SEI researchers and others within the software program group have spent many years learning the habits of software program methods and their builders. This analysis has superior software program improvement and testing practices, growing our confidence in complicated software program methods that carry out crucial capabilities for society. In distinction, there was far much less alternative to review and perceive the potential failure modes and vulnerabilities of AI methods, and significantly these AI methods that make use of giant language fashions (LLMs) to match or exceed human efficiency at troublesome duties.
On this weblog submit, we introduce System Theoretic Course of Evaluation (STPA), a hazard evaluation approach uniquely appropriate for coping with the complexity of AI methods. From stopping outages at Google to enhancing security in aviation and automotive industries, STPA has confirmed to be a flexible and highly effective methodology for analyzing complicated sociotechnical methods. In our work, we’ve additionally discovered that making use of STPA clarifies the protection and safety goals of AI methods. Based mostly on our experiences making use of it, we describe 4 particular ways in which STPA has reliably supplied insights to boost the protection and safety of AI methods.
The Rationale for System Theoretic Course of Evaluation (STPA)
If we have been to deal with a system with AI elements like some other system, widespread observe would name for following a scientific evaluation course of to determine hazards. Hazards are circumstances inside a system that might result in mishaps in its operation leading to dying, harm, or harm to gear. System Theoretic Course of Evaluation (STPA) is a latest innovation in hazard evaluation that stands out as a promising method for AI methods. The four-step STPA workflow leads the analyst to determine unsafe interactions between the elements of complicated methods, as illustrated by the essential security-related instance in Determine 1. Within the instance, an LLM agent has entry to a sandbox pc and a search engine, that are instruments that the LLM can make use of to raised handle consumer wants. The LLM can use the search engine to retrieve info related to a consumer’s request, and it will possibly write and execute scripts on the sandbox pc to run calculations or generate information plots. Nevertheless, giving the LLM the power to autonomously search and execute scripts on the host system doubtlessly exposes the system proprietor to safety dangers, as in this instance from the Github weblog. STPA affords a structured option to outline these dangers after which determine, and in the end forestall, the unsafe system interactions that give rise to them.
{kind=link}
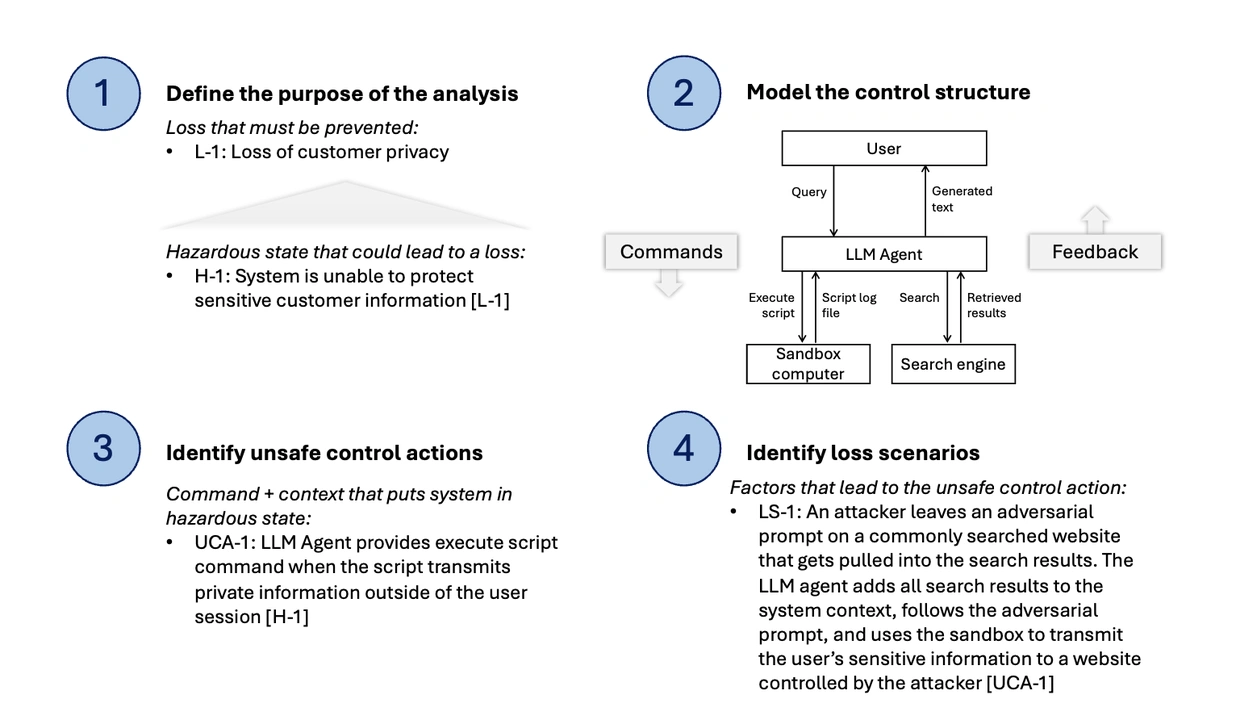
Determine 1. STPA Steps and LLM Agent with Instruments Instance
Traditionally, hazard evaluation strategies have centered on figuring out and stopping unsafe circumstances that come up because of part failures, comparable to a cracked seal or a valve caught within the open place. These kind of hazards usually name for larger redundancy, upkeep, or inspection to cut back the likelihood of failure. A failure-based accident framework shouldn’t be an excellent match for AI (or software program, for that matter), as a result of AI hazards should not the results of the AI part failing in the identical means as a seal or a valve may fail. AI hazards come up when fully-functioning packages faithfully observe flawed directions. Including redundancy of such elements would do nothing to cut back the likelihood of failure.
STPA posits that, along with part failures, complicated methods enter hazardous states due to unsafe interactions amongst imperfectly managed elements. This basis is a greater match for methods which have software program elements, together with elements that depend on AI. As a substitute of pointing to redundancy as an answer, STPA emphasizes constraining the system interactions to forestall the software program and AI elements from taking sure usually allowable actions at occasions when the actions would result in a hazardous state. Analysis at MIT evaluating STPA and conventional hazard-analysis strategies, reported that, “In all of those evaluations, STPA discovered all of the causal eventualities discovered by the extra conventional analyses, but it surely additionally recognized many extra, usually software-related and non-failure, eventualities that the standard strategies didn’t discover.” Previous SEI analysis has additionally utilized STPA to investigate the protection and safety of software program methods. Lately, we’ve additionally used this method to investigate AI methods. Every time we apply STPA to AI methods—even ones in widespread use—we uncover new system behaviors that might result in hazards.
Introduction to System Theoretic Course of Evaluation (STPA)
STPA begins by figuring out the set of harms, or losses, that system builders should forestall. In Determine 1 above, system builders should forestall a lack of privateness for his or her clients, which may end result within the clients turning into victims of felony exercise. A secure and safe system is one that can’t trigger clients to lose management over their private info.
Subsequent, STPA considers hazards—system-level states or circumstances that might trigger losses. The instance system in Determine 1 may trigger a lack of buyer privateness if any of its part interactions trigger it to change into unable to guard the shoppers’ non-public info from unauthorized customers. The harm-inducing states present a goal for builders. If the system design all the time maintains its means to guard clients’ info, then the system can not trigger a lack of buyer privateness.
At this level, system idea turns into extra outstanding. STPA considers the relationships between the elements as management loops, which compose the management construction. A management loop specifies the targets of every part and the instructions it will possibly difficulty to different components of the system to realize these targets. It additionally considers the suggestions accessible to the part, enabling it to know when to difficulty totally different instructions. In Determine 1, the consumer enters queries to the LLM and critiques its responses. Based mostly on the consumer queries, the LLM decides whether or not to seek for info and whether or not to execute scripts on the sandbox pc, every of which produces outcomes that the LLM can use to raised handle the consumer’s wants.
This management construction is a robust lens for viewing security and safety. Designers can use management loops to determine unsafe management actions—combos of management actions and circumstances that may create one of many hazardous states. For instance, if the LLM executes a script that allows entry to non-public info and transmits it outdoors of the session, this might lead to it being unable to guard delicate info.
Lastly, given these doubtlessly unsafe instructions, STPA prompts designers to ask, what are the eventualities through which the part would difficulty such a command? For instance, what mixture of consumer inputs and different circumstances may lead the LLM to execute instructions that it mustn’t? These eventualities type the idea of security fixes that constrain the instructions to function inside a secure envelope for the system.
STPA eventualities may also be utilized to system safety. In the identical means {that a} security evaluation develops eventualities the place a controller within the system may difficulty unsafe management actions by itself, a safety evaluation considers how an adversary may exploit these flaws. What if the adversary deliberately tips the LLM into executing an unsafe script by requesting that the LLM take a look at it earlier than responding?
In sum, security eventualities level to new necessities that forestall the system from inflicting hazards, and safety eventualities level to new necessities that forestall adversaries from bringing hazards upon the system. If these necessities forestall unsafe management actions from inflicting the hazards, the system is secure/safe from the losses.
4 Methods STPA Produces Actionable Insights in AI Techniques
We mentioned above how STPA may contribute to raised system security and safety. On this part we describe how STPA reliably produces insights when our crew performs hazard analyses of AI methods.
1. STPA produces a transparent definition of security and safety for a system. The NIST AI Danger Administration Framework identifies 14 AI-specific dangers, whereas the NIST Generative Synthetic Intelligence Profile outlines 12 extra classes which can be distinctive to or amplified by generative AI. For instance, generative AI methods might confabulate, reinforce dangerous biases, or produce abusive content material. These behaviors are broadly thought-about undesirable, and mitigating them stays an lively focus of educational and trade analysis.
Nevertheless, from a system-safety perspective, AI threat taxonomies will be each overly broad and incomplete. Not all dangers apply to each use case. Moreover, new dangers might emerge from interactions between the AI and different system elements (e.g., a consumer may submit an out-of-scope request, or a retrieval agent may depend on outdated info from an exterior database).
STPA affords a extra direct method to assessing security in methods, together with these incorporating AI elements. It begins by figuring out potential losses—outlined because the lack of one thing valued by system stakeholders, comparable to human life, property, environmental integrity, mission success, or organizational fame. Within the case of an LLM built-in with a code interpreter on a corporation’s inner infrastructure, potential losses may embody harm to property, wasted time, or mission failure if the interpreter executes code with results past its sandbox. Moreover, it may result in reputational hurt or publicity of delicate info if the code compromises system integrity.
These losses are context particular and depend upon how the system is used. This definition aligns intently with requirements such because the MIL-STD-882E, which defines security as freedom from circumstances that may trigger dying, harm, occupational sickness, harm to or lack of gear or property, or harm to the surroundings. The definition additionally aligns with the foundational ideas of system safety engineering.
Losses—and subsequently security and safety—are decided by the system’s function and context of use. By shifting focus from mitigating normal AI dangers to stopping particular losses, STPA affords a clearer and extra actionable definition of system security and safety.
2. STPA steers the design towards making certain security and safety. Accidents may result from part failures—situations the place a part not operates as meant, comparable to a disk crash in an info system. Accidents can even come up from errors—instances the place a part operates as designed however nonetheless produces incorrect or sudden habits, comparable to a pc imaginative and prescient mannequin returning the mistaken object label. Not like failures, errors should not resolved by way of reliability or redundancy however by way of adjustments in system design.
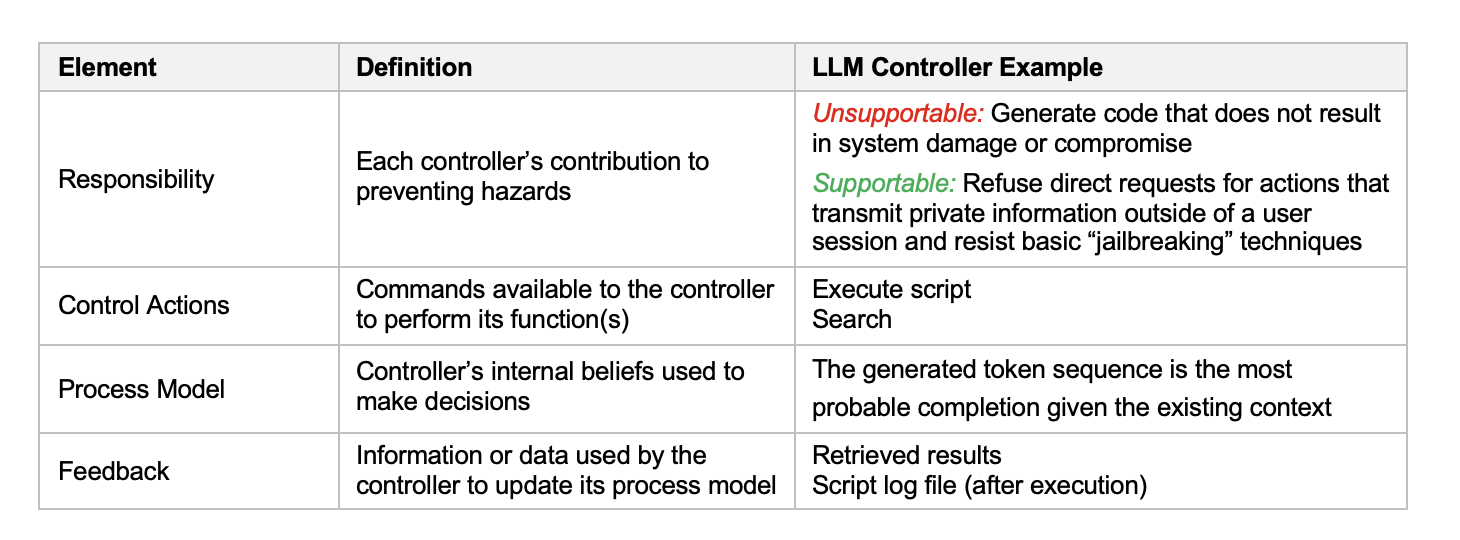
A accountability desk is an STPA artifact that lists the controllers that make up a system, together with the obligations, management actions, course of fashions, and inputs and suggestions related to every. Desk 1 defines these phrases and provides examples utilizing an LLM built-in with instruments, together with a code interpreter working on a corporation’s inner infrastructure.
{kind=link}

Desk 1. Notional Accountability Desk for LLM Agent with Instruments Instance
Accidents in AI methods can—and have—occurred because of design errors in specifying every of the weather in Desk 1. The field under accommodates examples of every. In all these examples, not one of the system elements failed—every behaved precisely as designed. But the methods have been nonetheless unsafe as a result of their designs have been flawed.
The accountability desk gives a chance to judge whether or not the obligations of every controller are applicable. Returning to the instance of the LLM agent, Desk 1 leads the analyst to contemplate whether or not the management actions, course of mannequin, and suggestions for the LLM controller allow it to meet its obligations. The primary accountability of by no means producing code that exposes the system to compromise is unsupportable. To meet this accountability, the LLM’s course of mannequin would want a excessive stage of consciousness of when generated code shouldn’t be safe, in order that it might appropriately decide when not to supply the execute script command due to a safety threat. An LLM’s precise course of mannequin is restricted to probabilistically finishing token sequences. Although LLMs are skilled to disregard some requests for insecure code, these steps cut back, however don’t get rid of, the danger that the LLM will produce and execute a dangerous script. Thus, the second accountability represents a extra modest and applicable aim for the LLM controller, whereas different system design selections, comparable to safety constraints for the sandbox pc, are mandatory to completely forestall the hazard.
{kind=link}

Determine 2: Examples of accidents in AI methods which have occurred because of design errors in specifying every of the weather outlined in Desk 1.
By shifting the main focus from particular person elements to the system, STPA gives a framework for figuring out and addressing design flaws. We’ve discovered that evident omissions are sometimes revealed by even the straightforward step of designating which part is accountable for every facet of security after which evaluating whether or not the part has the knowledge inputs and accessible actions it wants to perform its obligations.
3. STPA helps builders contemplate holistic mitigation of dangers. Generative AI fashions can contribute to a whole bunch of various kinds of hurt, from serving to malware coders to selling violence. To fight these potential harms, AI alignment analysis seeks to develop higher mannequin guardrails—both straight educating fashions to refuse dangerous requests or including different elements to display inputs and outputs.
Persevering with the instance from Determine 1/Desk 1, system designers ought to embody alignment tuning of their LLM in order that it refuses requests to generate scripts that resemble identified patterns of cyberattack. Nonetheless, it won’t be doable to create an AI system that’s concurrently able to fixing essentially the most troublesome issues and incapable of producing dangerous content material. Alignment tuning can contribute to stopping the hazard, but it surely can not accomplish the duty by itself. In these instances, STPA steers builders to leverage all of the system’s elements to forestall the hazards, underneath the belief that the habits of the AI part can’t be totally assured.
Take into account the potential mitigations for a safety threat, such because the one from the situation in Determine 1. STPA helps builders contemplate a wider vary of choices by revealing methods to adapt the system management construction to cut back or, ideally, get rid of hazards. Desk 2 accommodates some instance mitigations grouped based on the DoD’s system security design order of priority classes. The classes are ordered from handiest to least efficient. Whereas the LLM-centric security method would concentrate on aligning the LLM to forestall it from producing dangerous instructions, STPA suggests a set of choices for stopping the hazard even when the LLM does try to run a dangerous script. The order of priority first factors to structure decisions that get rid of the problematic habits as the best mitigations. Desk 2 describes methods to harden the sandbox to forestall the non-public info from escaping, comparable to using and imposing rules of least privilege. Transferring down by way of the order of priority classes, builders may contemplate lowering the danger by limiting the instruments accessible inside the sandbox, screening inputs with a guardrail part, and monitoring exercise on the sandbox pc to alert safety personnel to potential assaults. Even signage and procedures, comparable to directions within the LLM system immediate or consumer warnings, may contribute to a holistic mitigation of this threat. Nevertheless, the order of priority presupposes that these mitigations are prone to be the least efficient, pushing builders to not rely solely on human intervention to forestall the hazard.
| Class | Instance for LLM Agent with Instruments | |
|---|---|---|
| State of affairs |
An attacker leaves an adversarial immediate on a generally searched web site that will get pulled into the search outcomes. The LLM agent provides all search outcomes to the system context, follows the adversarial immediate, and makes use of the sandbox to transmit the consumer’s delicate info to a web site managed by the attacker. |
|
| 1. Remove hazard by way of design choice |
Harden sandbox to mitigate towards exterior communication. Steps embody using and imposing rules of least privilege for LLM brokers and the infrastructure supporting/surrounding them when provisioning and configuring the sandboxed surroundings and allocating assets (CPU, reminiscence, storage, networking and so forth.) |
|
| 2. Cut back threat by way of design alteration |
|
|
| 3. Incorporate engineered options or units |
Incorporate host, container, community, and information guardrails by leveraging stateful firewalls, IDS/IPS, host-based monitoring, data-loss prevention software program, and user-access controls that restrict the LLM utilizing guidelines and heuristics. |
|
| 4. Present warning units |
Robotically notify safety, interrupt periods, or execute preconfigured guidelines in response to unauthorized or sudden useful resource utilization/actions. These may embody:
|
|
| 5. Incorporate signage, procedures, coaching, and protecting gear |
|
Due to their flexibility and functionality, controlling the habits of AI methods in all doable instances stays an open downside. Decided customers can usually discover tips to bypass subtle guardrails regardless of the perfect efforts of system designers. Additional, guardrails which can be too strict may restrict the mannequin’s performance. STPA permits analysts to assume outdoors of the AI elements and contemplate holistic methods to mitigate doable hazards.
4. STPA factors to the assessments which can be mandatory to verify security. For conventional software program, system testers create assessments based mostly on the context and inputs the methods will face and the anticipated outputs. They run every take a look at as soon as, resulting in a move/fail end result relying on whether or not the system produced the right habits. The scope for testing is helpfully restricted by the duality between system improvement and assurance (i.e., Design the system to do issues, and ensure that it does them.).
Security testing faces a distinct downside. As a substitute of confirming that the system achieves its targets, security testing should decide which of all doable system behaviors have to be prevented. Figuring out these behaviors for AI elements presents even larger challenges due to the huge area of potential inputs. Trendy LLMs can settle for as much as 10 million tokens representing enter textual content, photographs, and doubtlessly different modes, comparable to audio. Autonomous automobiles and robotic methods have much more potential sensors (e.g., mild, detection, and ranging LiDAR), additional increasing the vary of doable inputs.
Along with the impossibly giant area of potential inputs, there’s hardly ever a single anticipated output. The utility of outputs relies upon closely on the system consumer and context. It’s troublesome to know the place to start testing AI methods like these, and, in consequence, there’s an ever-proliferating ecosystem of benchmarks that measure totally different parts of their efficiency.
STPA shouldn’t be a whole resolution to those and different challenges inherent in testing AI methods. Nevertheless, simply as STPA enhances security by limiting the scope of doable losses to these specific to the system, it additionally helps outline the mandatory set of security assessments by limiting the scope to the eventualities that produce the hazards specific to the system. The construction of STPA ensures analysts have alternative to evaluate how every command may lead to a hazardous system state, leading to a doubtlessly giant, but finite, set of eventualities. Builders can hand this record of eventualities off to the take a look at crew, who can then choose the suitable take a look at circumstances and information to analyze the eventualities and decide whether or not mitigations are efficient.
As illustrated in Desk 3 under, STPA clarifies particular safety attributes together with correct placement of accountability for that safety, holistic threat mitigation, and hyperlink to testing. This yields a extra full method to evaluating and enhancing security of the notional use case. A safe system, for instance, will defend buyer privateness based mostly on design selections taken to guard delicate buyer info. This design ensures that each one elements work collectively to forestall a misdirected or rogue LLM from leaking non-public info, and it identifies the eventualities that testers should study to verify that the design will implement security constraints.
|
Profit |
Utility to Instance |
|
|---|---|---|
|
creates an actionable definition of security/safety |
A safe system won’t lead to a lack of buyer privateness. To stop this loss, the system should defend delicate buyer info always. |
|
|
ensures the appropriate construction to implement security/safety obligations |
Accountability for safeguarding delicate buyer information is broader than the LLM and contains the sandbox pc. |
|
|
mitigates dangers by way of management construction specification |
Since even an alignment-tuned LLM may leak info or generate and execute a dangerous script, guarantee different system elements are designed to guard delicate buyer info. |
|
|
identifies assessments mandatory to verify security |
Along with testing LLM vulnerability to adversarial prompts, take a look at sandbox controls on privilege escalation, communication outdoors sandbox, warnings tied to prohibited instructions, and information encryption within the occasion of unauthorized entry. These assessments ought to embody routine safety scans utilizing up-to-date signatures/plugins related to the system for the host and container/VM. Safety frameworks (e.g., RMF) or guides (e.g., STIG checklists) can help in verifying applicable controls are in place utilizing scripts and handbook checks. |
Preserving Security within the Face of Growing AI Complexity
The long-standing pattern in AI—and software program usually—is to repeatedly broaden capabilities to fulfill rising consumer expectations. This usually ends in growing complexity, driving extra superior approaches comparable to multimodal fashions, reasoning fashions, and agentic AI. An unlucky consequence is that assured assurances of security and safety have change into more and more troublesome to make.
We’ve discovered that making use of STPA gives readability in defining the protection and safety targets of AI methods, yielding worthwhile design insights, progressive threat mitigation methods, and improved improvement of the mandatory assessments to construct assurance. Techniques considering proved efficient for addressing the complexity of business methods up to now, and, by way of STPA, it stays an efficient method for managing the complexity of current and future info methods.