{kind=link}

In lots of real-world functions, knowledge is just not purely textual—it could embrace photos, tables, and charts that assist reinforce the narrative. A multimodal report generator lets you incorporate each textual content and pictures right into a last output, making your studies extra dynamic and visually wealthy.
This text outlines easy methods to construct such a pipeline utilizing:
- LlamaIndex for orchestrating doc parsing and question engines,
- OpenAI language fashions for textual evaluation,
- LlamaParse to extract each textual content and pictures from PDF paperwork,
- An observability setup utilizing Arize Phoenix (by way of LlamaTrace) for logging and debugging.
The top result’s a pipeline that may course of a whole PDF slide deck—each textual content and visuals—and generate a structured report containing each textual content and pictures.
Studying Aims
- Perceive easy methods to combine textual content and visuals for efficient monetary report era utilizing multimodal pipelines.
- Be taught to make the most of LlamaIndex and LlamaParse for enhanced monetary report era with structured outputs.
- Discover LlamaParse for extracting each textual content and pictures from PDF paperwork successfully.
- Arrange observability utilizing Arize Phoenix (by way of LlamaTrace) for logging and debugging advanced pipelines.
- Create a structured question engine to generate studies that interleave textual content summaries with visible parts.
This text was printed as part of the Information Science Blogathon.
Overview of the Course of
Constructing a multimodal report generator entails making a pipeline that seamlessly integrates textual and visible parts from advanced paperwork like PDFs. The method begins with putting in the mandatory libraries, resembling LlamaIndex for doc parsing and question orchestration, and LlamaParse for extracting each textual content and pictures. Observability is established utilizing Arize Phoenix (by way of LlamaTrace) to observe and debug the pipeline.
As soon as the setup is full, the pipeline processes a PDF doc, parsing its content material into structured textual content and rendering visible parts like tables and charts. These parsed parts are then related, making a unified dataset. A SummaryIndex is constructed to allow high-level insights, and a structured question engine is developed to generate studies that mix textual evaluation with related visuals. The result’s a dynamic and interactive report generator that transforms static paperwork into wealthy, multimodal outputs tailor-made for consumer queries.
Step-by-Step Implementation
Comply with this detailed information to construct a multimodal report generator, from organising dependencies to producing structured outputs with built-in textual content and pictures. Every step ensures a seamless integration of LlamaIndex, LlamaParse, and Arize Phoenix for an environment friendly and dynamic pipeline.
Step 1: Set up and Import Dependencies
You’ll want the next libraries operating on Python 3.9.9 :
- llama-index
- llama-parse (for textual content + picture parsing)
- llama-index-callbacks-arize-phoenix (for observability/logging)
- nest_asyncio (to deal with async occasion loops in notebooks)
!pip set up -U llama-index-callbacks-arize-phoenix
import nest_asyncio
nest_asyncio.apply()Step 2: Set Up Observability
We combine with LlamaTrace – LlamaCloud API (Arize Phoenix). First, acquire an API key from llamatrace.com, then arrange surroundings variables to ship traces to Phoenix.
Phoenix API key may be obtained by signing up for LlamaTrace right here , then navigate to the underside left panel and click on on ‘Keys’ the place you need to discover your API key.
For instance:
PHOENIX_API_KEY = ""
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
) Step 3: Load the info – Get hold of Your Slide Deck
For demonstration, we use ConocoPhillips’ 2023 investor assembly slide deck. We obtain the PDF:
import os
import requests
# Create the directories (ignore errors in the event that they exist already)
os.makedirs("knowledge", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/information/2023-conocophillips-aim-presentation.pdf"
# Obtain and save to knowledge/conocophillips.pdf
response = requests.get(url)
with open("knowledge/conocophillips.pdf", "wb") as f:
f.write(response.content material)
print("PDF downloaded to knowledge/conocophillips.pdf")Examine if the pdf slide deck is within the knowledge folder, if not place it within the knowledge folder and identify it as you need.
Step 4: Set Up Fashions
You want an embedding mannequin and an LLM. On this instance:
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding(mannequin="text-embedding-3-large")
llm = OpenAI(mannequin="gpt-4o")Subsequent, you register these because the default for LlamaIndex:
from llama_index.core import Settings
Settings.embed_model = embed_model
Settings.llm = llmStep 5: Parse the Doc with LlamaParse
LlamaParse can extract textual content and pictures (by way of a multimodal massive mannequin). For every PDF web page, it returns:
- Markdown textual content (with tables, headings, bullet factors, and so forth.)
- A rendered picture (saved domestically)
print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("knowledge/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"]
print(md_json_list[10]["md"])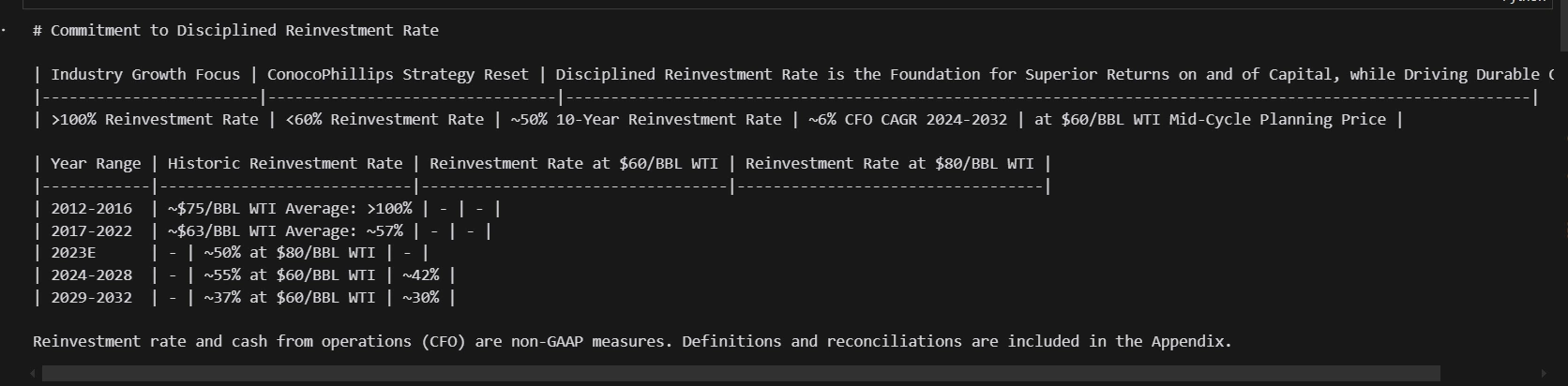
print(md_json_list[1].keys())
image_dicts = parser.get_images(md_json_objs, download_path="data_images")
Step 6: Affiliate Textual content and Photographs
We create an inventory of TextNode objects (LlamaIndex’s knowledge construction) for every web page. Every node has metadata in regards to the web page quantity and the corresponding picture file path:
from llama_index.core.schema import TextNode
from typing import Elective
# get pages loaded by llamaparse
import re
def get_page_number(file_name):
match = re.search(r"-page-(d+).jpg$", str(file_name))
if match:
return int(match.group(1))
return 0
def _get_sorted_image_files(image_dir):
"""Get picture information sorted by web page."""
raw_files = [f for f in list(Path(image_dir).iterdir()) if f.is_file()]
sorted_files = sorted(raw_files, key=get_page_number)
return sorted_files
from copy import deepcopy
from pathlib import Path
# connect picture metadata to the textual content nodes
def get_text_nodes(json_dicts, image_dir=None):
"""Break up docs into nodes, by separator."""
nodes = []
image_files = _get_sorted_image_files(image_dir) if image_dir is just not None else None
md_texts = [d["md"] for d in json_dicts]
for idx, md_text in enumerate(md_texts):
chunk_metadata = {"page_num": idx + 1}
if image_files is just not None:
image_file = image_files[idx]
chunk_metadata["image_path"] = str(image_file)
chunk_metadata["parsed_text_markdown"] = md_text
node = TextNode(
textual content="",
metadata=chunk_metadata,
)
nodes.append(node)
return nodes
# this can break up into pages
text_nodes = get_text_nodes(md_json_list, image_dir="data_images")
print(text_nodes[10].get_content(metadata_mode="all"))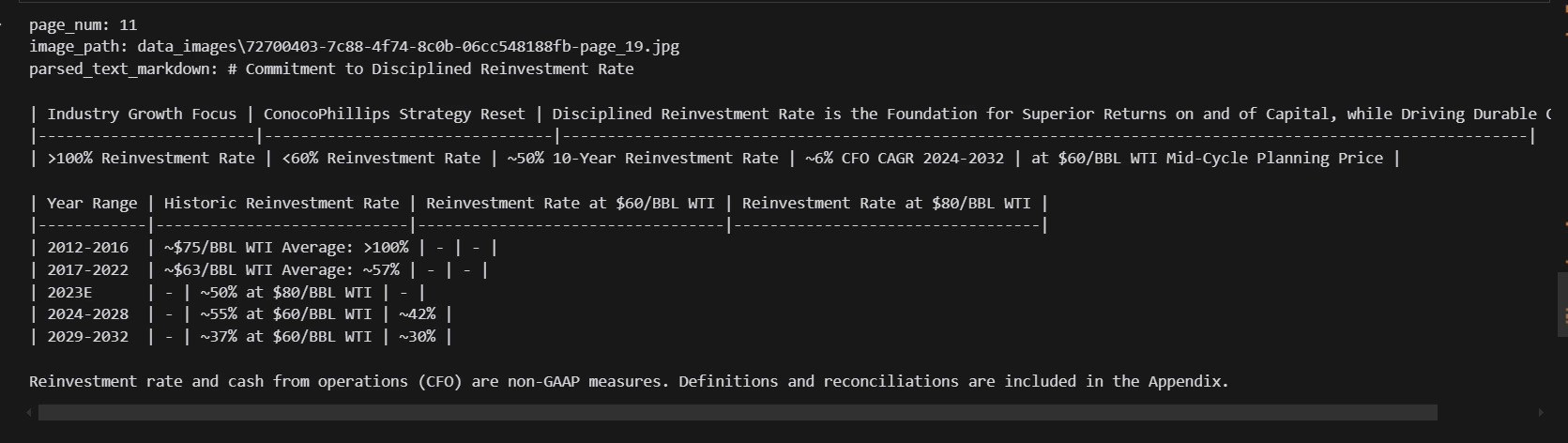
Step 7: Construct a Abstract Index
With these textual content nodes in hand, you’ll be able to create a SummaryIndex:
import os
from llama_index.core import (
StorageContext,
SummaryIndex,
load_index_from_storage,
)
if not os.path.exists("storage_nodes_summary"):
index = SummaryIndex(text_nodes)
# save index to disk
index.set_index_id("summary_index")
index.storage_context.persist("./storage_nodes_summary")
else:
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage_nodes_summary")
# load index
index = load_index_from_storage(storage_context, index_id="summary_index")The SummaryIndex ensures you’ll be able to simply retrieve or generate high-level summaries over your entire doc.
Step 8: Outline a Structured Output Schema
Our pipeline goals to supply a last output with interleaved textual content blocks and picture blocks. For that, we create a customized Pydantic mannequin (utilizing Pydantic v2 or making certain compatibility) with two block varieties—TextBlock and ImageBlock—and a mum or dad mannequin ReportOutput:
from llama_index.llms.openai import OpenAI
from pydantic import BaseModel, Discipline
from typing import Listing
from IPython.show import show, Markdown, Picture
from typing import Union
class TextBlock(BaseModel):
"""Textual content block."""
textual content: str = Discipline(..., description="The textual content for this block.")
class ImageBlock(BaseModel):
"""Picture block."""
file_path: str = Discipline(..., description="File path to the picture.")
class ReportOutput(BaseModel):
"""Information mannequin for a report.
Can include a mixture of textual content and picture blocks. MUST include at the very least one picture block.
"""
blocks: Listing[Union[TextBlock, ImageBlock]] = Discipline(
..., description="A listing of textual content and picture blocks."
)
def render(self) -> None:
"""Render as HTML on the web page."""
for b in self.blocks:
if isinstance(b, TextBlock):
show(Markdown(b.textual content))
else:
show(Picture(filename=b.file_path))
system_prompt = """
You're a report era assistant tasked with producing a well-formatted context given parsed context.
You may be given context from a number of studies that take the type of parsed textual content.
You're chargeable for producing a report with interleaving textual content and pictures - within the format of interleaving textual content and "picture" blocks.
Since you can not instantly produce a picture, the picture block takes in a file path - you need to write within the file path of the picture as a substitute.
How are you aware which picture to generate? Every context chunk will include metadata together with a picture render of the supply chunk, given as a file path.
Embrace ONLY the pictures from the chunks which have heavy visible parts (you will get a touch of this if the parsed textual content accommodates lots of tables).
You MUST embrace at the very least one picture block within the output.
You MUST output your response as a software name with a purpose to adhere to the required output format. Do NOT give again regular textual content.
"""
llm = OpenAI(mannequin="gpt-4o", api_key="OpenAI_API_KEY", system_prompt=system_prompt)
sllm = llm.as_structured_llm(output_cls=ReportOutput)The important thing level: ReportOutput requires at the very least one picture block, making certain the ultimate reply is multimodal.
Step 9: Create a Structured Question Engine
LlamaIndex lets you use a “structured LLM” (i.e., an LLM whose output is robotically parsed into a particular schema). Right here’s how:
query_engine = index.as_query_engine(
similarity_top_k=10,
llm=sllm,
# response_mode="tree_summarize"
response_mode="compact",
)
response = query_engine.question(
"Give me a abstract of the monetary efficiency of the Alaska/Worldwide phase vs. the decrease 48 phase"
)
response.response.render()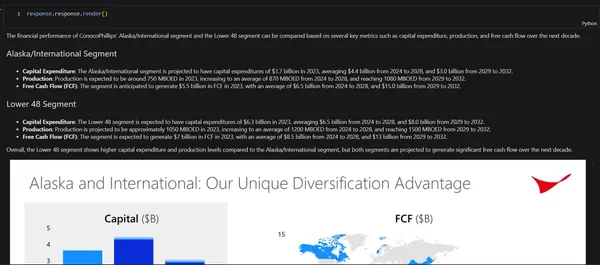
# Output
The monetary efficiency of ConocoPhillips' Alaska/Worldwide phase and the Decrease 48 phase may be in contrast primarily based on a number of key metrics resembling capital expenditure, manufacturing, and free money stream over the following decade.
Alaska/Worldwide Section
Capital Expenditure: The Alaska/Worldwide phase is projected to have capital expenditures of $3.7 billion in 2023, averaging $4.4 billion from 2024 to 2028, and $3.0 billion from 2029 to 2032.
Manufacturing: Manufacturing is predicted to be round 750 MBOED in 2023, growing to a median of 870 MBOED from 2024 to 2028, and reaching 1080 MBOED from 2029 to 2032.
Free Money Circulation (FCF): The phase is anticipated to generate $5.5 billion in FCF in 2023, with a median of $6.5 billion from 2024 to 2028, and $15.0 billion from 2029 to 2032.
Decrease 48 Section
Capital Expenditure: The Decrease 48 phase is predicted to have capital expenditures of $6.3 billion in 2023, averaging $6.5 billion from 2024 to 2028, and $8.0 billion from 2029 to 2032.
Manufacturing: Manufacturing is projected to be roughly 1050 MBOED in 2023, growing to a median of 1200 MBOED from 2024 to 2028, and reaching 1500 MBOED from 2029 to 2032.
Free Money Circulation (FCF): The phase is predicted to generate $7 billion in FCF in 2023, with a median of $8.5 billion from 2024 to 2028, and $13 billion from 2029 to 2032.
General, the Decrease 48 phase exhibits greater capital expenditure and manufacturing ranges in comparison with the Alaska/Worldwide phase, however each segments are projected to generate vital free money stream over the following decade.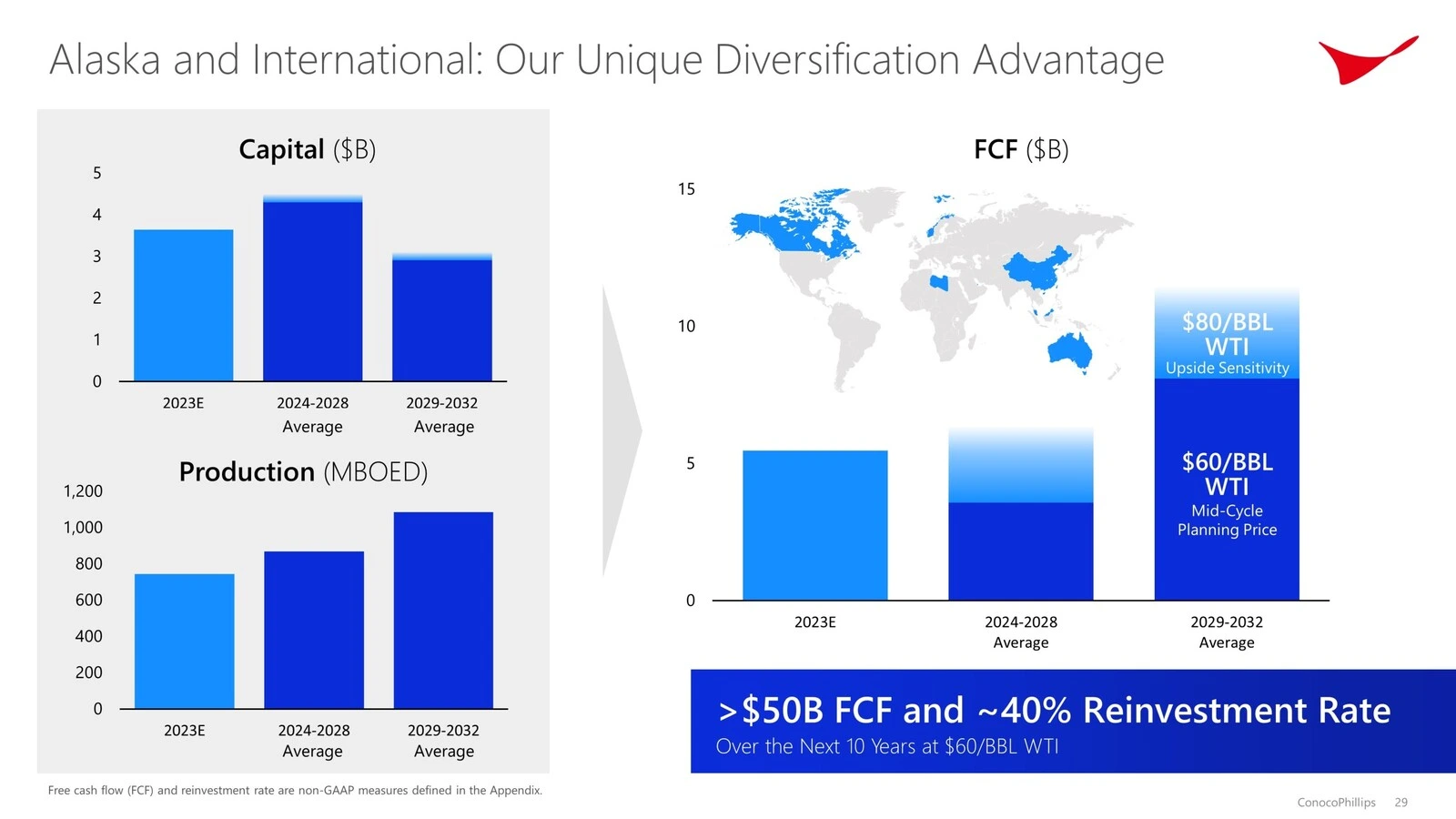
# Attempting one other question
response = query_engine.question(
"Give me a abstract of whether or not you suppose the monetary projections are secure, and if not, what are the potential threat elements. "
"Assist your analysis with sources."
)
response.response.render()
Conclusion
By combining LlamaIndex, LlamaParse, and OpenAI, you’ll be able to construct a multimodal report generator that processes a whole PDF (with textual content, tables, and pictures) right into a structured output. This method delivers richer, extra visually informative outcomes—precisely what stakeholders must glean vital insights from advanced company or technical paperwork.
Be happy to adapt this pipeline to your personal paperwork, add a retrieval step for big archives, or combine domain-specific fashions for analyzing the underlying photos. With the foundations laid out right here, you’ll be able to create dynamic, interactive, and visually wealthy studies that go far past easy text-based queries.
An enormous because of Jerry Liu from LlamaIndex for growing this superb pipeline.
Key Takeaways
- Rework PDFs with textual content and visuals into structured codecs whereas preserving the integrity of unique content material utilizing LlamaParse and LlamaIndex.
- Generate visually enriched studies that interweave textual summaries and pictures for higher contextual understanding.
- Monetary report era may be enhanced by integrating each textual content and visible parts for extra insightful and dynamic outputs.
- Leveraging LlamaIndex and LlamaParse streamlines the method of economic report era, making certain correct and structured outcomes.
- Retrieve related paperwork earlier than processing to optimize report era for big archives.
- Enhance visible parsing, incorporate chart-specific analytics, and mix fashions for textual content and picture processing for deeper insights.
Regularly Requested Questions
A. A multimodal report generator is a system that produces studies containing a number of forms of content material—primarily textual content and pictures—in a single cohesive output. On this pipeline, you parse a PDF into each textual and visible parts, then mix them right into a single last report.
A. Observability instruments like Arize Phoenix (by way of LlamaTrace) allow you to monitor and debug mannequin conduct, monitor queries and responses, and determine points in actual time. It’s particularly helpful when coping with massive or advanced paperwork and a number of LLM-based steps.
A. Most PDF textual content extractors solely deal with uncooked textual content, typically dropping formatting, photos, and tables. LlamaParse is able to extracting each textual content and pictures (rendered web page photos), which is essential for constructing multimodal pipelines the place you might want to refer again to tables, charts, or different visuals.
A. SummaryIndex is a LlamaIndex abstraction that organizes your content material (e.g., pages of a PDF) so it will probably shortly generate complete summaries. It helps collect high-level insights from lengthy paperwork with out having to chunk them manually or run a retrieval question for every bit of knowledge.
A. Within the ReportOutput Pydantic mannequin, implement that the blocks checklist requires at the very least one ImageBlock. That is said in your system immediate and schema. The LLM should comply with these guidelines, or it won’t produce legitimate structured output.
The media proven on this article is just not owned by Analytics Vidhya and is used on the Creator’s discretion.
Hello! I am Adarsh, a Enterprise Analytics graduate from ISB, presently deep into analysis and exploring new frontiers. I am tremendous enthusiastic about knowledge science, AI, and all of the progressive methods they’ll remodel industries. Whether or not it is constructing fashions, engaged on knowledge pipelines, or diving into machine studying, I really like experimenting with the newest tech. AI is not simply my curiosity, it is the place I see the long run heading, and I am at all times excited to be part of that journey!