{kind=link}

AI has considerably impacted healthcare, significantly in illness analysis and therapy planning. One space gaining consideration is the event of Medical Massive Imaginative and prescient-Language Fashions (Med-LVLMs), which mix visible and textual knowledge for superior diagnostic instruments. These fashions have proven nice potential for enhancing the evaluation of advanced medical photographs, providing interactive and clever responses that may help docs in scientific decision-making. Nevertheless, as promising as these instruments are, they don’t seem to be with out essential challenges that restrict their widespread adoption in healthcare.
A big situation confronted by Med-LVLMs is the tendency to supply inaccurate or “hallucinated” medical data. These factual hallucinations can severely have an effect on affected person outcomes if fashions generate inaccurate diagnoses or misread medical photographs. The first causes for these points are the necessity for giant, high-quality labeled medical datasets and the distribution gaps between the information used to coach these fashions and the information encountered in real-world scientific environments. This mismatch between coaching knowledge and precise deployment knowledge creates important reliability issues, making it troublesome to belief these fashions in essential medical situations. Additionally, present options like fine-tuning and retrieval-augmented technology (RAG) strategies have limitations, particularly when utilized throughout various medical fields equivalent to radiology, pathology, and ophthalmology.
Present strategies to enhance the efficiency of Med-LVLMs primarily deal with two approaches: fine-tuning and RAG. High quality-tuning includes adjusting mannequin parameters primarily based on smaller, extra specialised datasets to enhance accuracy, however the restricted availability of high-quality labeled knowledge hampers this methodology. Additionally, fine-tuned fashions usually have to carry out higher when utilized to new, unseen knowledge. Conversely, RAG permits fashions to retrieve exterior information through the inference course of, providing real-time references that would assist enhance factual accuracy. Nevertheless, this method may very well be even higher. Present RAG-based programs usually need assistance to generalize throughout completely different medical domains, which limits their reliability and causes potential misalignment between the retrieved data and the precise medical drawback being addressed.
Researchers from UNC-Chapel Hill, Stanford College, Rutgers College, College of Washington, Brown College, and PloyU launched a brand new system referred to as MMed-RAG, a flexible multimodal retrieval-augmented technology system designed particularly for medical vision-language fashions. MMed-RAG goals to considerably enhance the factual accuracy of Med-LVLMs by implementing a domain-aware retrieval mechanism. This mechanism can deal with numerous medical picture varieties, equivalent to radiology, ophthalmology, and pathology, making certain that the retrieval mannequin is suitable for the precise medical area. The researchers additionally developed an adaptive context choice methodology that fine-tunes the variety of retrieved contexts throughout inference, making certain that the mannequin makes use of solely related and high-quality data. This adaptive choice helps keep away from frequent pitfalls the place fashions retrieve an excessive amount of or too little knowledge, probably resulting in inaccuracies.
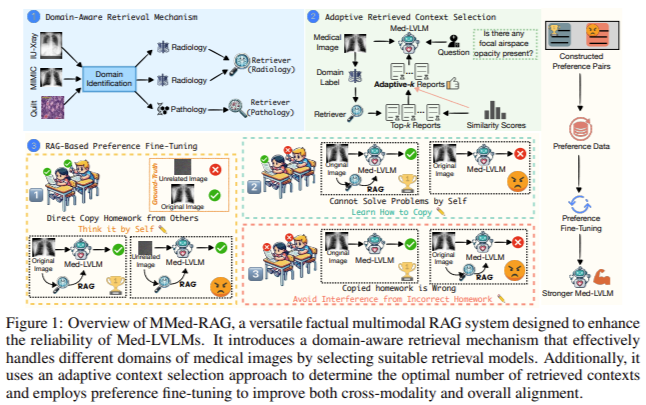
The MMed-RAG system is constructed on three key parts:
- The domain-aware retrieval mechanism ensures the mannequin retrieves domain-specific data that aligns carefully with the enter medical picture. For instance, radiology photographs can be paired with applicable radiology-based data, whereas pathology photographs can be pulled from pathology-specific databases.
- The adaptive context choice methodology improves the standard of the retrieved data by utilizing similarity scores to filter out irrelevant or low-quality knowledge. This dynamic strategy ensures that the mannequin solely considers essentially the most related contexts, decreasing the chance of factual hallucination.
- The RAG-based desire fine-tuning optimizes the mannequin’s cross-modality alignment, making certain that the retrieved data and the visible enter are appropriately aligned with the bottom fact, thereby enhancing general mannequin reliability.
MMed-RAG was examined throughout 5 medical datasets, masking radiology, pathology, and ophthalmology, with excellent outcomes. The system achieved a 43.8% enchancment in factual accuracy in comparison with earlier Med-LVLMs, highlighting its functionality to boost diagnostic reliability. In medical question-answering duties (VQA), MMed-RAG improved accuracy by 18.5%, and in medical report technology, it achieved a outstanding 69.1% enchancment. These outcomes display the system’s effectiveness in closed and open-ended duties, the place retrieved data is essential for correct responses. Additionally, the desire fine-tuning method utilized by MMed-RAG addresses cross-modality misalignment, a typical situation in different Med-LVLMs, the place fashions battle to steadiness visible enter with retrieved textual data.

Key takeaways from this analysis embody:
- MMed-RAG achieved a 43.8% improve in factual accuracy throughout 5 medical datasets.
- The system improved medical VQA accuracy by 18.5% and medical report technology by 69.1%.
- The domain-aware retrieval mechanism ensures that medical photographs are paired with the right context, enhancing diagnostic accuracy.
- Adaptive context choice helps scale back irrelevant knowledge retrieval, rising the reliability of the mannequin’s output.
- RAG-based desire fine-tuning successfully addresses misalignment between visible inputs and retrieved data, enhancing general mannequin efficiency.

In conclusion, MMed-RAG considerably advances medical vision-language fashions by addressing key challenges associated to factual accuracy and mannequin alignment. By incorporating domain-aware retrieval, adaptive context choice, and desire fine-tuning, the system improves the factual reliability of Med-LVLMs and enhances their generalizability throughout a number of medical domains. This method has proven substantial enhancements in diagnostic accuracy and the standard of generated medical studies. These developments place MMed-RAG as an important step ahead in making AI-assisted medical diagnostics extra dependable and reliable.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication.. Don’t Neglect to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving High quality-Tuned Fashions: Predibase Inference Engine (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.