
Synthetic intelligence (AI) analysis has more and more centered on enhancing the effectivity & scalability of deep studying fashions. These fashions have revolutionized pure language processing, pc imaginative and prescient, and information analytics however have vital computational challenges. Particularly, as fashions develop bigger, they require huge computational sources to course of immense datasets. Methods equivalent to backpropagation are important for coaching these fashions by optimizing their parameters. Nevertheless, conventional strategies wrestle to scale deep studying fashions effectively with out inflicting efficiency bottlenecks or requiring extreme computational energy.
One of many foremost points with present deep studying fashions is their reliance on dense computation, which prompts all mannequin parameters uniformly throughout coaching and inference. This technique is inefficient when processing large-scale information, leading to pointless activation of sources that will not be related to the duty at hand. As well as, the non-differentiable nature of some parts in these fashions makes it difficult to use gradient-based optimization, limiting coaching effectiveness. As fashions proceed to scale, overcoming these challenges is essential to advancing the sector of AI and enabling extra highly effective and environment friendly techniques.
Present approaches to scaling AI fashions typically embrace dense and sparse fashions that make use of knowledgeable routing mechanisms. Dense fashions, like GPT-3 and GPT-4, activate all layers and parameters for each enter, making them resource-heavy and tough to scale. Sparse fashions, which purpose to activate solely a subset of parameters primarily based on enter necessities, have proven promise in decreasing computational calls for. Nevertheless, current strategies like GShard and Change Transformers nonetheless rely closely on knowledgeable parallelism and make use of methods like token dropping to handle useful resource distribution. Whereas efficient, these strategies have trade-offs in coaching effectivity and mannequin efficiency.
Researchers from Microsoft have launched an progressive resolution to those challenges with GRIN (GRadient-INformed Combination of Specialists). This strategy goals to deal with the restrictions of current sparse fashions by introducing a brand new technique of gradient estimation for knowledgeable routing. GRIN enhances mannequin parallelism, permitting for extra environment friendly coaching with out the necessity for token dropping, a typical concern in sparse computation. By making use of GRIN to autoregressive language fashions, the researchers have developed a top-2 mixture-of-experts mannequin with 16 consultants per layer, known as the GRIN MoE mannequin. This mannequin selectively prompts consultants primarily based on enter, considerably decreasing the variety of energetic parameters whereas sustaining excessive efficiency.
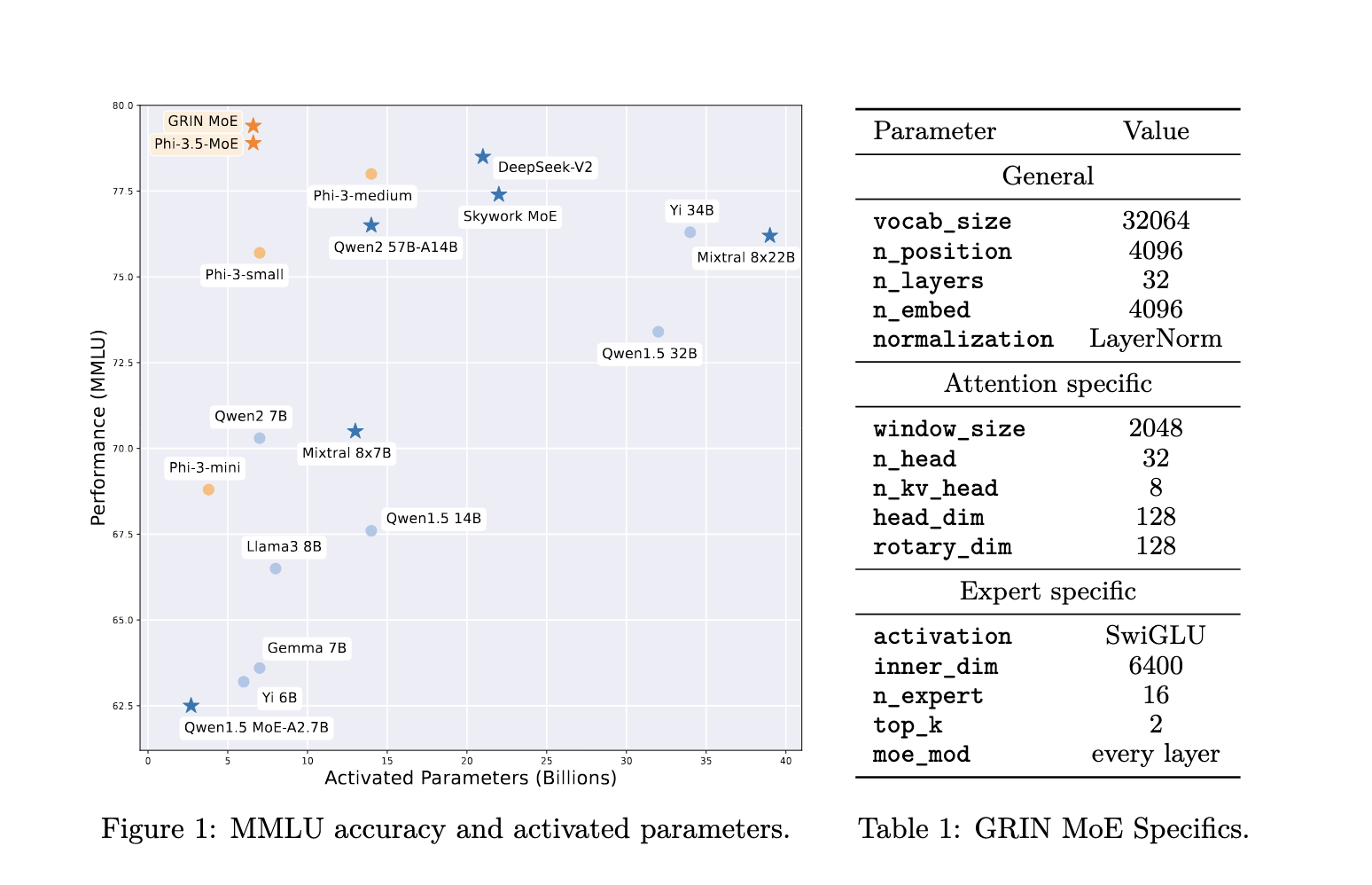
The GRIN MoE mannequin employs a number of superior methods to realize its spectacular efficiency. The mannequin’s structure contains MoE layers the place every layer consists of 16 consultants, and solely the highest 2 are activated for every enter token, utilizing a routing mechanism. Every knowledgeable is applied as a GLU (Gated Linear Unit) community, permitting the mannequin to stability computational effectivity and expressive energy. The researchers launched SparseMixer-v2, a key part that estimates gradients associated to knowledgeable routing, changing typical strategies that use gating gradients as proxies. This enables the mannequin to scale with out counting on token dropping or knowledgeable parallelism, which is widespread in different sparse fashions.
The efficiency of the GRIN MoE mannequin has been rigorously examined throughout a variety of duties, and the outcomes display its superior effectivity and scalability. Within the MMLU (Huge Multitask Language Understanding) benchmark, the mannequin scored a powerful 79.4, surpassing a number of dense fashions of comparable or bigger sizes. It additionally achieved a rating of 83.7 on HellaSwag, a benchmark for commonsense reasoning, and 74.4 on HumanEval, which measures the mannequin’s capacity to unravel coding issues. Notably, the mannequin’s efficiency on MATH, a benchmark for mathematical reasoning, was 58.9, reflecting its power in specialised duties. The GRIN MoE mannequin makes use of solely 6.6 billion activated parameters throughout inference, which is fewer than the 7 billion activated parameters of competing dense fashions, but it matches or exceeds their efficiency. In one other comparability, GRIN MoE outperformed a 7-billion parameter-dense mannequin and matched the efficiency of a 14-billion parameter-dense mannequin on the identical dataset.
The introduction of GRIN additionally brings marked enhancements in coaching effectivity. When educated on 64 H100 GPUs, the GRIN MoE mannequin achieved an 86.56% throughput, demonstrating that sparse computation can scale successfully whereas sustaining excessive effectivity. This marks a big enchancment over earlier fashions, which frequently undergo from slower coaching speeds because the variety of parameters will increase. Moreover, the mannequin’s capacity to keep away from token dropping means it maintains a excessive degree of accuracy and robustness throughout numerous duties, not like fashions that lose info throughout coaching.
General, the analysis crew’s work on GRIN presents a compelling resolution to the continued problem of scaling AI fashions. By introducing a complicated technique for gradient estimation and mannequin parallelism, they’ve efficiently developed a mannequin that not solely performs higher but additionally trains extra effectively. This development might result in widespread purposes in pure language processing, coding, arithmetic, and extra. The GRIN MoE mannequin represents a big step ahead in AI analysis, providing a pathway to extra scalable, environment friendly, and high-performing fashions sooner or later.
Try the Paper, Mannequin Card, and Demo. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.