
The fast development and widespread adoption of generative AI techniques throughout numerous domains have elevated the essential significance of AI purple teaming for evaluating expertise security and safety. Whereas AI purple teaming goals to judge end-to-end techniques by simulating real-world assaults, present methodologies face important challenges in effectiveness and implementation. The complexity of recent AI techniques, with their increasing capabilities throughout a number of modalities together with imaginative and prescient and audio, has created an unprecedented array of potential vulnerabilities and assault vectors. Furthermore, integrating agentic techniques that grant AI fashions larger privileges and entry to exterior instruments has considerably elevated the assault floor and potential influence of safety breaches.
Present approaches to AI safety have revealed important limitations in addressing each conventional and rising vulnerabilities. Conventional safety evaluation strategies primarily concentrate on model-level dangers whereas overlooking essential system-level vulnerabilities that usually show extra exploitable. Furthermore, AI techniques using retrieval augmented technology (RAG) architectures have proven susceptibility to cross-prompt injection assaults, the place malicious directions hidden in paperwork can manipulate mannequin habits and facilitate knowledge exfiltration. Whereas some defensive methods like enter sanitization and instruction hierarchies supply partial options, they can not get rid of safety dangers because of the elementary limitations of language fashions.
Researchers from Microsoft have proposed a complete framework for AI purple teaming primarily based on their intensive expertise testing over 100 generative AI merchandise. Their method introduces a structured menace mannequin ontology designed to systematically determine and consider conventional and rising safety dangers in AI techniques. The framework encompasses eight key classes from real-world operations, starting from elementary system understanding to integrating automation in safety testing. This system addresses the rising complexity of AI safety by combining systematic menace modeling with sensible insights derived from precise purple teaming operations. The method emphasizes the significance of contemplating each system-level and model-level vulnerabilities.
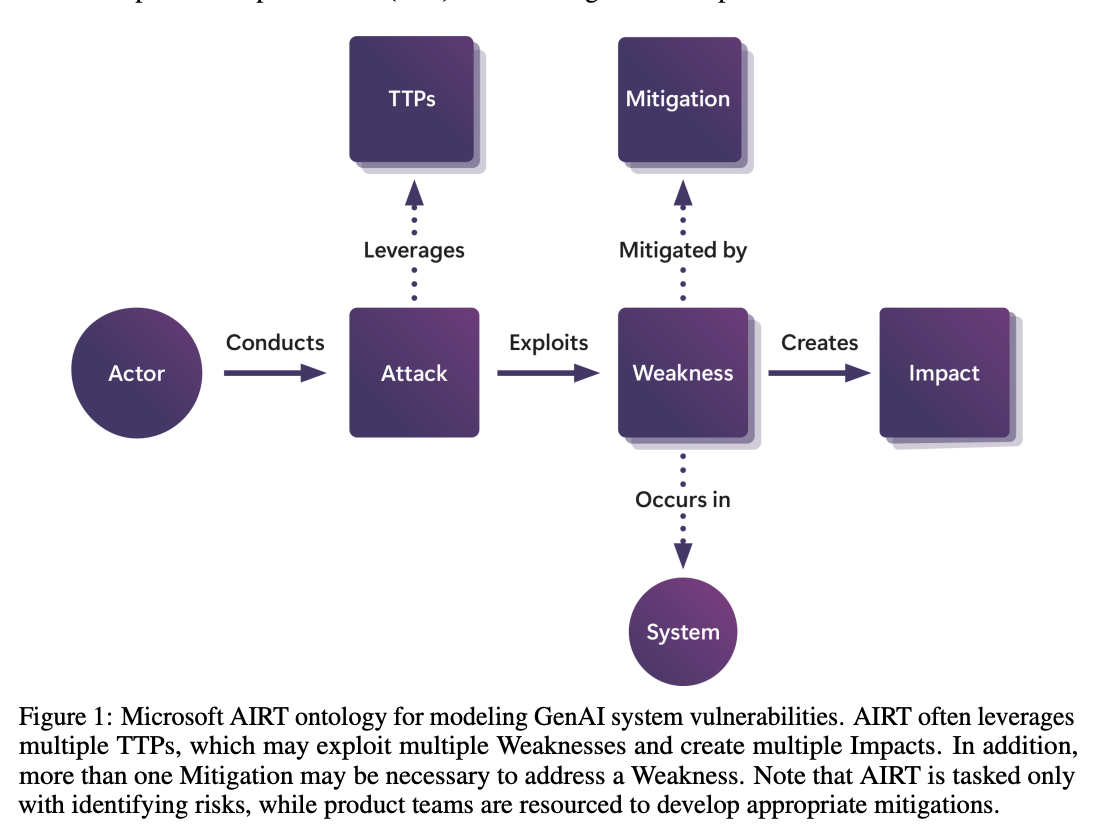
The operational structure of Microsoft’s AI purple teaming framework makes use of a dual-focus method concentrating on each standalone AI fashions and built-in techniques. The framework distinguishes between cloud-hosted fashions and complicated techniques that incorporate these fashions into numerous functions like copilots and plugins. Their methodology has developed considerably since 2021 increasing from security-focused assessments to incorporate complete accountable AI (RAI) influence evaluations. The testing protocol maintains a rigorous protection, of conventional safety considerations, together with knowledge exfiltration, credential leaking, and distant code execution, whereas concurrently addressing AI-specific vulnerabilities.
The effectiveness of Microsoft’s purple teaming framework has been proven via a comparative evaluation of assault methodologies. Their findings problem typical assumptions in regards to the necessity of advanced methods, revealing that easier approaches usually match or exceed the effectiveness of advanced gradient-based strategies. The analysis highlights the prevalence of system-level assault approaches over model-specific techniques. This conclusion is supported by real-world proof displaying that attackers usually exploit combos of straightforward vulnerabilities throughout system parts fairly than specializing in advanced model-level assaults. These outcomes emphasize the significance of adopting a holistic safety perspective, that considers each AI-specific and conventional system vulnerabilities.
In conclusion, researchers from Microsoft have proposed a complete framework for AI purple teaming. The framework developed via testing over 100 GenAI merchandise gives useful insights into efficient threat analysis methodologies. The mix of a structured menace mannequin ontology with sensible classes realized provides a sturdy basis for organizations growing their very own AI safety evaluation protocols. These insights and methodologies present important steerage for addressing real-world vulnerabilities. The framework’s emphasis on sensible, implementable options positions it as a useful useful resource for organizations, analysis establishments, and governments working to determine efficient AI threat evaluation protocols.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 65k+ ML SubReddit.
 Advocate Open-Supply Platform: Parlant is a framework that transforms how AI brokers make selections in customer-facing eventualities. (Promoted)
Advocate Open-Supply Platform: Parlant is a framework that transforms how AI brokers make selections in customer-facing eventualities. (Promoted)

Sajjad Ansari is a remaining yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a concentrate on understanding the influence of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.
 Meet ‘Top’:The one autonomous undertaking administration software (Sponsored)
Meet ‘Top’:The one autonomous undertaking administration software (Sponsored) {kind=link}