{kind=link}

In in the present day’s world, CLIP is likely one of the most necessary multimodal foundational fashions. It combines visible and textual indicators right into a shared function house utilizing a easy contrastive studying loss on large-scale image-text pairs. As a retriever, CLIP helps many duties, together with zero-shot classification, detection, segmentation, and image-text retrieval. Additionally, as a function extractor, it has grow to be dominant in just about all cross-modal illustration duties, reminiscent of picture understanding, video understanding, and text-to-image/video era. Its energy primarily comes from its potential to attach photographs with pure language and seize human data as it’s educated on giant net knowledge with detailed textual content descriptions, not like imaginative and prescient encoders. Because the giant language fashions (LLMs) are creating quickly, the boundaries of language comprehension and era are regularly being pushed. LLMs’ robust textual content abilities can assist CLIP higher deal with lengthy, complicated captions, a weak point of the unique CLIP. LLMs even have broad data of huge textual content datasets, making coaching more practical. LLMs have robust understanding abilities, however their means of producing textual content hides skills that make their outputs unclear.
Present developments have prolonged CLIP to deal with different modalities, and its affect within the subject is rising. New fashions like Llama3 have been used to increase CLIP’s caption size and enhance its efficiency by leveraging the open-world data of LLMs. Nevertheless, incorporating LLMs with CLIP takes work as a result of limitations of its textual content encoder. In a number of experiments, it was discovered that straight integrating LLMs into CLIP results in diminished efficiency. Thus, sure challenges exist to beat to discover the potential advantages of incorporating LLMs into CLIP.

Tongji College and Microsoft Company researchers performed detailed analysis and proposed the LLM2CLIP method for enhancing visible illustration studying by integrating giant language fashions (LLMs). This methodology takes a simple step by changing the unique CLIP textual content encoder and enhances the CLIP visible encoder with in depth data of LLMs. It identifies key obstacles related to this progressive thought and suggests an economical fine-tuning technique to beat them. This methodology boldly replaces the unique CLIP textual content encoder. It acknowledges the challenges of this method and suggests an reasonably priced technique to fine-tune the mannequin to handle them.
The LLM2CLIP methodology successfully improved the CLIP mannequin by integrating giant language fashions (LLMs) like Llama. Initially, LLMs struggled as textual content encoders for CLIP as a consequence of their incapability to obviously distinguish picture captions. Researchers launched the caption contrastive fine-tuning approach to handle this, drastically bettering the LLM’s potential to separate captions. This fine-tuning led to a considerable efficiency enhance, surpassing present state-of-the-art fashions. The LLM2CLIP framework mixed the improved LLM with the pretrained CLIP visible encoder, creating a robust cross-modal mannequin. The tactic used giant LLMs however remained computationally environment friendly with minimal added prices.
The experiments primarily targeted on fine-tuning fashions for higher image-text matching utilizing datasets like CC-3M. For LLM2CLIP fine-tuning, three dataset sizes had been examined: small (CC-3M), medium (CC-3M and CC-12M), and giant (CC-3M, CC-12M, YFCC-15M, and Recaption-1B). Coaching with augmented captions improved efficiency, whereas utilizing an untrained language mannequin for CLIP worsened it. Fashions educated with LLM2CLIP outperformed customary CLIP and EVA in duties like image-to-text and text-to-image retrieval, highlighting the benefit of integrating giant language fashions with image-text fashions.
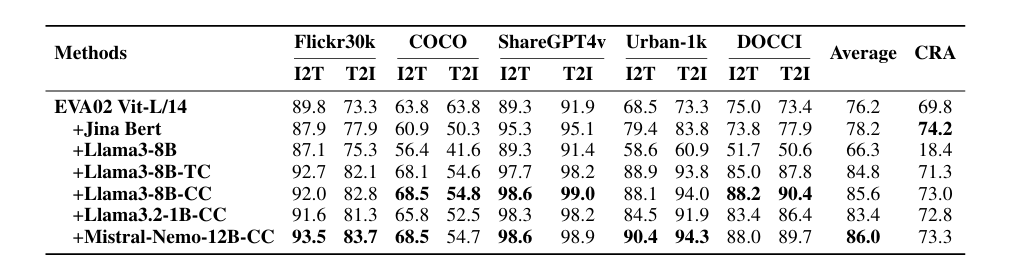
The tactic straight boosted the efficiency of the earlier SOTA EVA02 mannequin by 16.5% on each long-text and short-text retrieval duties, reworking a CLIP mannequin educated solely on English knowledge right into a state-of-the-art cross-lingual mannequin. After integrating multimodal coaching with fashions like Llava 1.5, it carried out higher than CLIP on virtually all benchmarks, displaying vital general enhancements in efficiency.

In conclusion, the proposed methodology permits LLMs to help in CLIP coaching. By adjusting parameters reminiscent of knowledge distribution, size, or classes, the LLM might be modified to repair CLIP’s limitations. It permits LLM to behave as a extra complete trainer for varied duties. Within the proposed work, the LLM gradients had been frozen throughout fine-tuning to take care of a big batch measurement for CLIP coaching. In future works, the LLM2CLIP might be educated from scratch on datasets like Laion-2Band and Recaption-1B for higher outcomes and efficiency. This work can be utilized as a baseline for future analysis in CLIP coaching and its big selection of purposes!
Take a look at the Paper, Code, and Mannequin on Hugging Face. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Clever Doc Processing with GenAI in Monetary Providers and Actual Property Transactions
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and clear up challenges.