{kind=link}

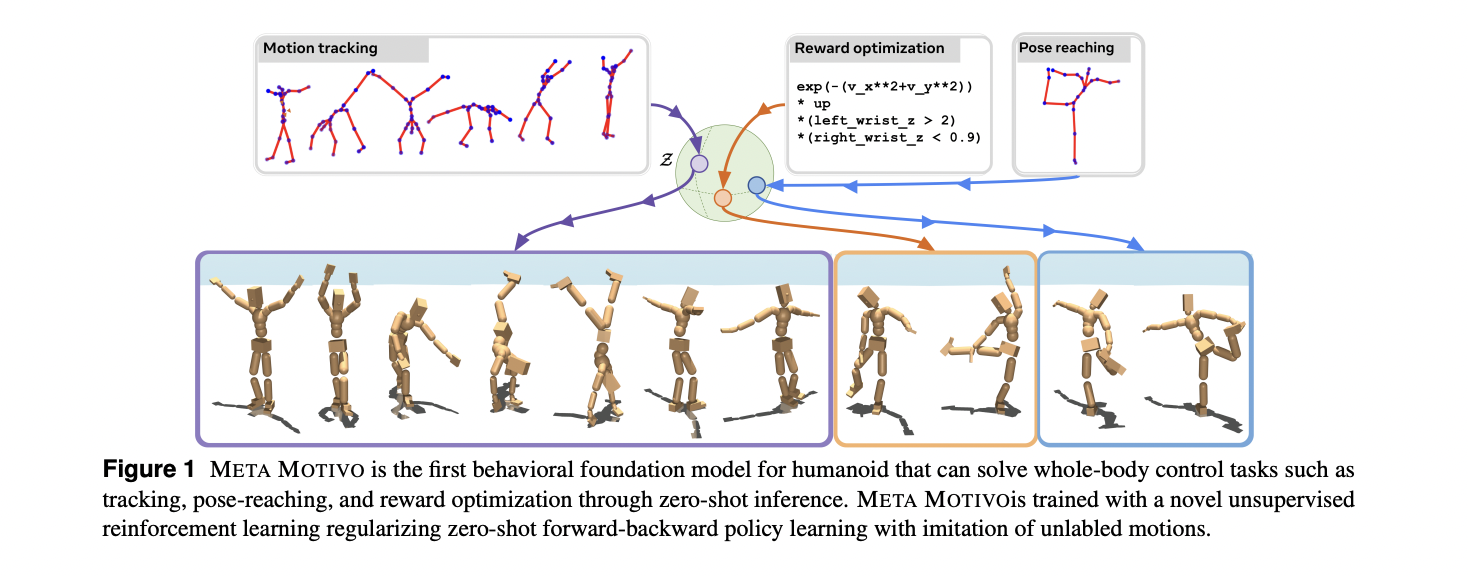
Basis fashions, pre-trained on in depth unlabeled knowledge, have emerged as a cutting-edge strategy for growing versatile AI programs able to fixing complicated duties by means of focused prompts. Researchers at the moment are exploring the potential of extending this paradigm past language and visible domains, specializing in behavioral basis fashions (BFMs) for brokers interacting with dynamic environments. Particularly, the analysis goals to develop BFMs for humanoid brokers, concentrating on whole-body management by means of proprioceptive observations. This strategy addresses a long-standing problem in robotics and AI, characterised by the high-dimensionality and intrinsic instability of humanoid management programs. The last word aim is to create generalized fashions that may categorical numerous behaviors in response to numerous prompts, together with imitation, aim achievement, and reward optimization.
Meta researchers introduce FB-CPR (Ahead-Backward representations with Conditional Coverage Regularization), an modern on-line unsupervised reinforcement studying algorithm designed to floor coverage studying by means of observation-only unlabeled behaviors. The algorithm’s key technical innovation includes using forward-backward representations to embed unlabeled trajectories right into a shared latent house, using a latent-conditional discriminator to encourage insurance policies to comprehensively “cowl” dataset states. Demonstrating the strategy’s effectiveness, the workforce developed META MOTIVO, a behavioral basis mannequin for whole-body humanoid management that may be prompted to unravel numerous duties reminiscent of movement monitoring, aim reaching, and reward optimization in a zero-shot studying state of affairs. The mannequin makes use of the SMPL skeleton and AMASS movement seize dataset to realize outstanding behavioral expressiveness.
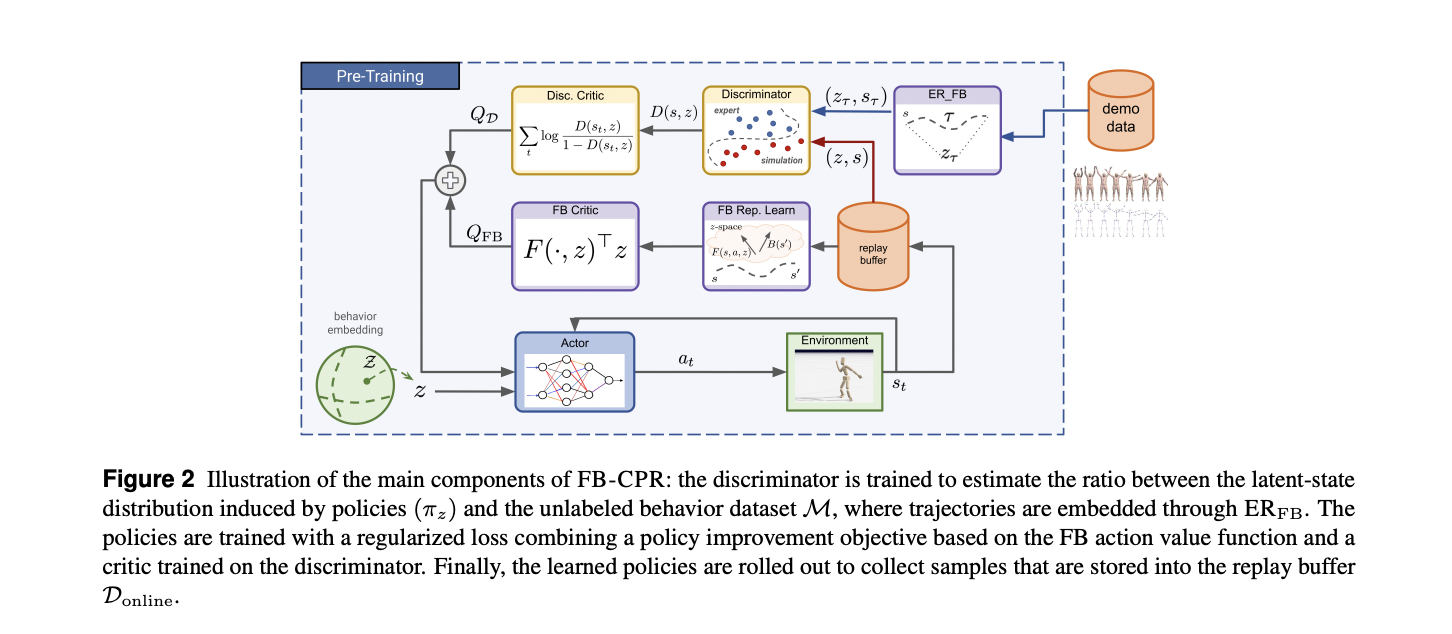
Researchers introduce a strong strategy to forward-backward (FB) illustration studying with conditional coverage regularization. On the pre-training stage, the agent has entry to an unlabeled conduct dataset containing observation-only trajectories. The tactic focuses on growing a steady set of latent-conditioned insurance policies the place latent variables are drawn from a distribution outlined over a latent house. By representing behaviors by means of the joint house of states and latent variables, the researchers goal to seize numerous movement patterns. The important thing innovation lies in inferring latent variables for every trajectory utilizing the ERFB methodology, which permits encoding trajectories right into a shared representational house. The last word aim is to regularize the unsupervised coaching of the behavioral basis mannequin by minimizing the discrepancy between the induced coverage distribution and the dataset distribution.
The analysis presents a complete efficiency analysis of the FB-CPR algorithm throughout a number of job classes. FB-CPR demonstrates outstanding zero-shot capabilities, attaining 73.4% of top-line algorithm efficiency with out specific task-specific coaching. In reward-maximization duties, the strategy outperforms unsupervised baselines, notably attaining 177% of DIFFUSER’s efficiency whereas sustaining considerably decrease computational complexity. For goal-reaching duties, FB-CPR performs comparably to specialised baselines, outperforming zero-shot options by 48% and 118% in proximity and success metrics respectively. A human analysis research additional revealed that whereas task-specific algorithms would possibly obtain greater numerical efficiency, FB-CPR was constantly perceived as extra “human-like”, with individuals score its behaviors as extra pure in 83% of reward-based duties and 69% of goal-reaching eventualities.
This analysis launched FB-CPR, a novel algorithm that mixes zero-shot properties of forward-backward fashions with modern regularization strategies for coverage studying utilizing unlabeled conduct datasets. By coaching the primary behavioral basis mannequin for complicated humanoid agent management, the strategy demonstrated state-of-the-art efficiency throughout numerous duties. Regardless of its important achievements, the strategy has notable limitations. FB-CPR struggles with duties far faraway from motion-capture datasets and sometimes produces imperfect actions, significantly in eventualities involving falling or standing. The present mannequin is restricted to proprioceptive observations and can’t navigate environments or work together with objects. Future analysis instructions embody integrating extra state variables, exploring complicated notion strategies, using video-based human exercise datasets, and growing extra direct language-policy alignment strategies to develop the mannequin’s capabilities and generalizability.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.