
Massive Language Fashions (LLMs) are primarily designed for text-based duties, limiting their capacity to interpret and generate multimodal content material resembling photos, movies, and audio. Conventionally, multimodal operations are task-specific fashions educated on massive quantities of labeled information, which makes them resource-hungry and inflexible. Zero-shot strategies are additionally restricted to pretraining with paired multimodal datasets, limiting their flexibility to new duties. The problem is to make LLMs carry out multimodal reasoning and technology with out task-specific coaching, curated information, or mannequin adaptation. Overcoming this problem would considerably improve the applicability of LLMs to multimodal content material processing and technology dynamically throughout a number of domains.
Standard multimodal AI programs are primarily based on fashions like CLIP for image-text alignment or diffusion fashions for media technology. Nonetheless, these strategies are restricted to in depth coaching on curated information. Zero-shot captioning fashions like ZeroCap and MeaCap attempt to overcome this however are nonetheless restricted to fastened architectures and gradient-based optimization, proscribing their generalization functionality throughout totally different modalities. These strategies have three limitations: they’re restricted to in depth labeled information, they can not generalize past the coaching distribution, and they’re primarily based on gradient-based strategies that limit their flexibility to new duties. With out overcoming these limitations, multimodal AI is restricted to fastened duties and datasets, proscribing its potential for additional functions.
Researchers from Meta suggest MILS (Multimodal Iterative LLM Solver), a test-time optimization framework that enhances LLMs with multimodal reasoning capabilities with out requiring extra coaching. Relatively than adjusting the LLM or retraining it on multimodal information, MILS makes use of an iterative optimization cycle with a GENERATOR and a SCORER. The GENERATOR, an LLM, produces candidate options for multimodal duties like picture captions, video descriptions, or stylized picture prompts, whereas the SCORER, a pre-trained multimodal mannequin, ranks the generated options by relevance, coherence, and alignment with enter information. Alternating between the 2, MILS repeatedly refines its outputs with real-time suggestions, regularly bettering efficiency. This permits zero-shot generalization throughout a number of modalities, together with textual content, photos, movies, and audio, making it an especially versatile answer for multimodal AI functions.

MILS is applied as a gradient-free optimization technique, using pre-trained fashions with out tuning their parameters. The framework has been utilized in quite a lot of multimodal duties. For picture captioning, MILS employs Llama 3.1 8B because the GENERATOR and CLIP-based fashions because the SCORER to iteratively discover optimum captions till essentially the most correct and descriptive caption is generated. The identical iterative course of is employed for video frames, with ViCLIP getting used for analysis, and for captioning audio, MILS extends the method to audio information with using ImageBind because the SCORER, permitting LLMs to generate pure language descriptions of sounds. For text-to-image technology, MILS optimizes picture technology prompts by optimizing textual descriptions previous to sending them to diffusion-based fashions, producing extra high-quality photos. The framework even extends to fashion switch, the place it generates optimized enhancing prompts that direct fashion switch fashions to generate extra visually constant transformations. As well as, it proposes cross-modal arithmetic, which mixes heterogeneous modalities, resembling an audio caption and a picture description, into one multimodal illustration. Utilizing pre-trained fashions as scoring features, MILS may keep away from express multimodal coaching whereas being task-agnostic.
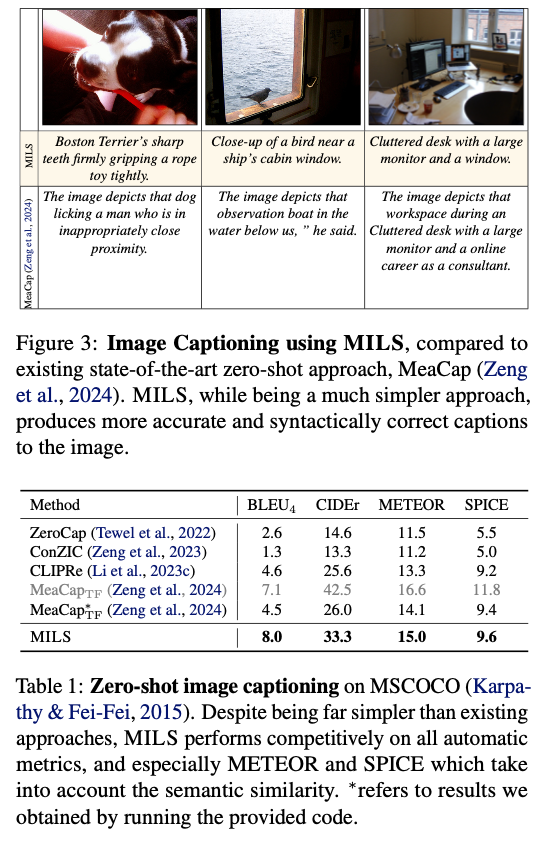

MILS achieves strong zero-shot efficiency on quite a lot of multimodal duties and outperforms earlier work on each captioning and technology. For picture captioning, it’s extra semantically correct than earlier zero-shot fashions and generates extra pure and informative captions. For captioning video and audio, it outperforms fashions educated on large-scale datasets even with zero task-specific coaching. For text-to-image technology, MILS improves picture high quality and constancy, and human evaluators want its synthesized photos in an awesome majority of instances. MILS can also be efficient for fashion switch, studying optimum prompts for higher visible transformation. Lastly, MILS achieves new cross-modal arithmetic options, permitting mixed data from modalities to generate coherent outputs. These findings display the pliability and effectivity of MILS, making it a paradigm-breaking different to multimodal AI programs primarily based on fastidiously curated coaching information.
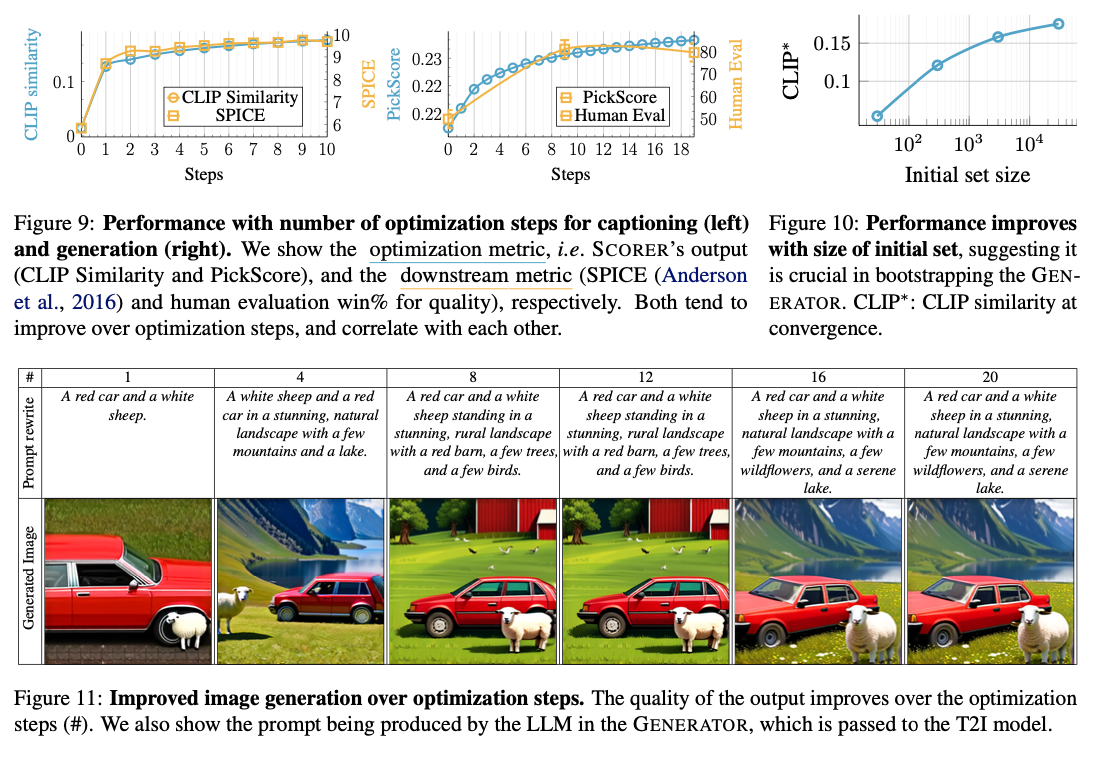
MILS presents a brand new paradigm for multimodal AI in its capacity to let LLMs generate and course of textual content, picture, video, and audio content material with out coaching and fine-tuning. Its test-time iterative optimization mechanism permits emergent zero-shot generalization, outperforming earlier zero-shot strategies however staying easy. Utilizing pre-trained LLMs and multimodal fashions in adaptive suggestions, MILS creates a brand new state-of-the-art for multimodal AI, permitting for extra adaptive and scalable AI programs that may dynamically course of multimodal reasoning and technology duties.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 75k+ ML SubReddit.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s captivated with information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.