{kind=link}

Transformer fashions have pushed groundbreaking developments in synthetic intelligence, powering functions in pure language processing, laptop imaginative and prescient, and speech recognition. These fashions excel at understanding and producing sequential knowledge by leveraging mechanisms like multi-head consideration to seize relationships inside enter sequences. The rise of huge language fashions (LLMs) constructed upon transformers has amplified these capabilities, enabling duties starting from advanced reasoning to inventive content material technology.
Nonetheless, LLMs’ growing measurement and complexity come at the price of computational effectivity. These fashions rely closely on totally linked layers and multi-head consideration operations, which demand important sources. In most sensible eventualities, totally linked layers dominate the computational load, making it difficult to scale these fashions with out incurring excessive power and {hardware} prices. This inefficiency restricts their accessibility and scalability throughout broader industries and functions.
Numerous strategies have been proposed to sort out the computational bottlenecks in transformer fashions. Strategies like mannequin pruning and weight quantization have reasonably improved effectivity by decreasing mannequin measurement and precision. Redesigning the self-attention mechanism, resembling linear and flash-attention, has diminished its computational complexity from quadratic to linear regarding sequence size. Nonetheless, these approaches usually have to pay extra consideration to the contribution of totally linked layers, leaving a considerable portion of the computation unoptimized.
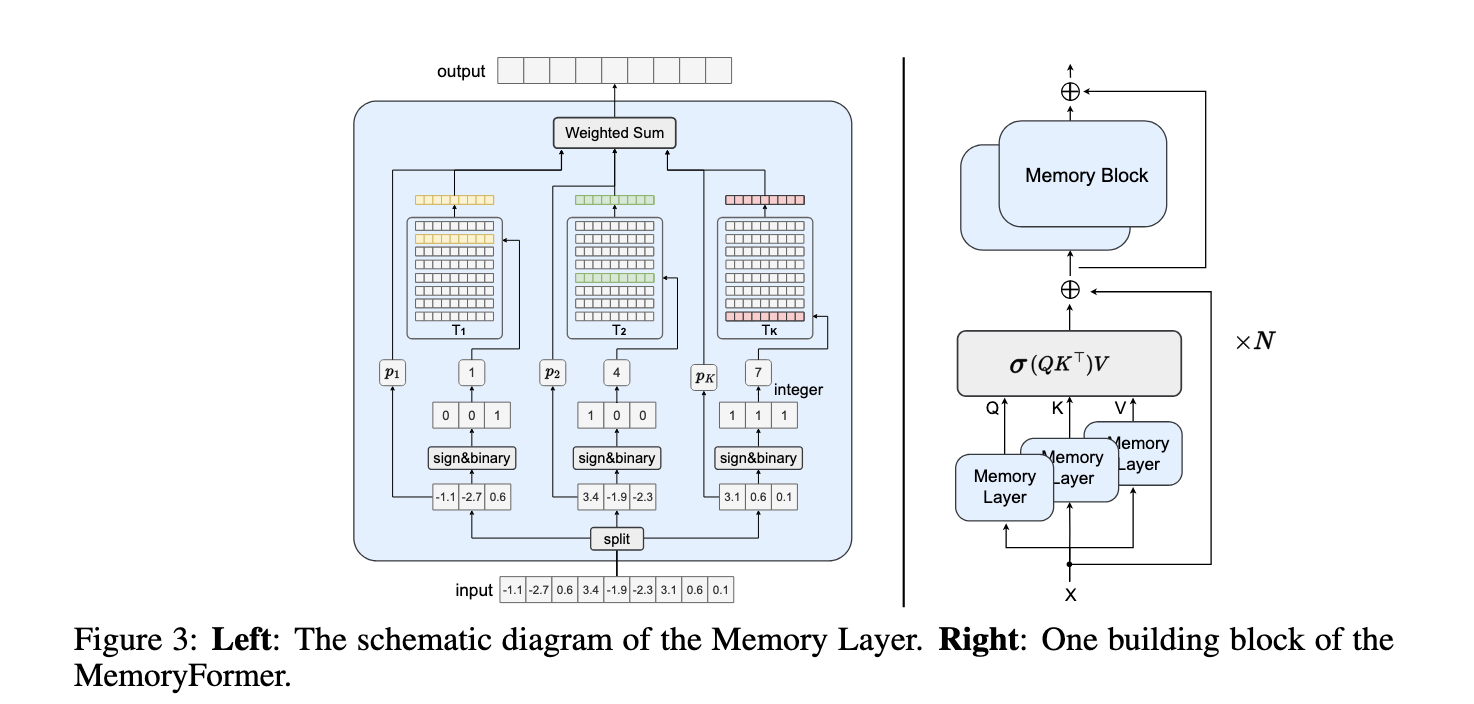
Researchers from Peking College, Huawei Noah’s Ark Lab, and Huawei HiSilicon launched MemoryFormer. This transformer structure eliminates the computationally costly fully-connected layers, changing them with Reminiscence Layers. These layers make the most of in-memory lookup tables and locality-sensitive hashing (LSH) algorithms. MemoryFormer goals to remodel enter embeddings by retrieving pre-computed vector representations from reminiscence as an alternative of performing typical matrix multiplications.
The core innovation in MemoryFormer lies in its Reminiscence Layer design. As an alternative of straight performing linear projections, enter embeddings are hashed utilizing a locality-sensitive hashing algorithm. This course of maps related embeddings to the identical reminiscence areas, permitting the mannequin to retrieve pre-stored vectors that approximate the outcomes of matrix multiplications. By dividing embeddings into smaller chunks and processing them independently, MemoryFormer reduces reminiscence necessities and computational load. The structure additionally incorporates learnable vectors inside hash tables, enabling the mannequin to be educated end-to-end utilizing back-propagation. This design ensures that MemoryFormer can deal with various duties whereas sustaining effectivity.
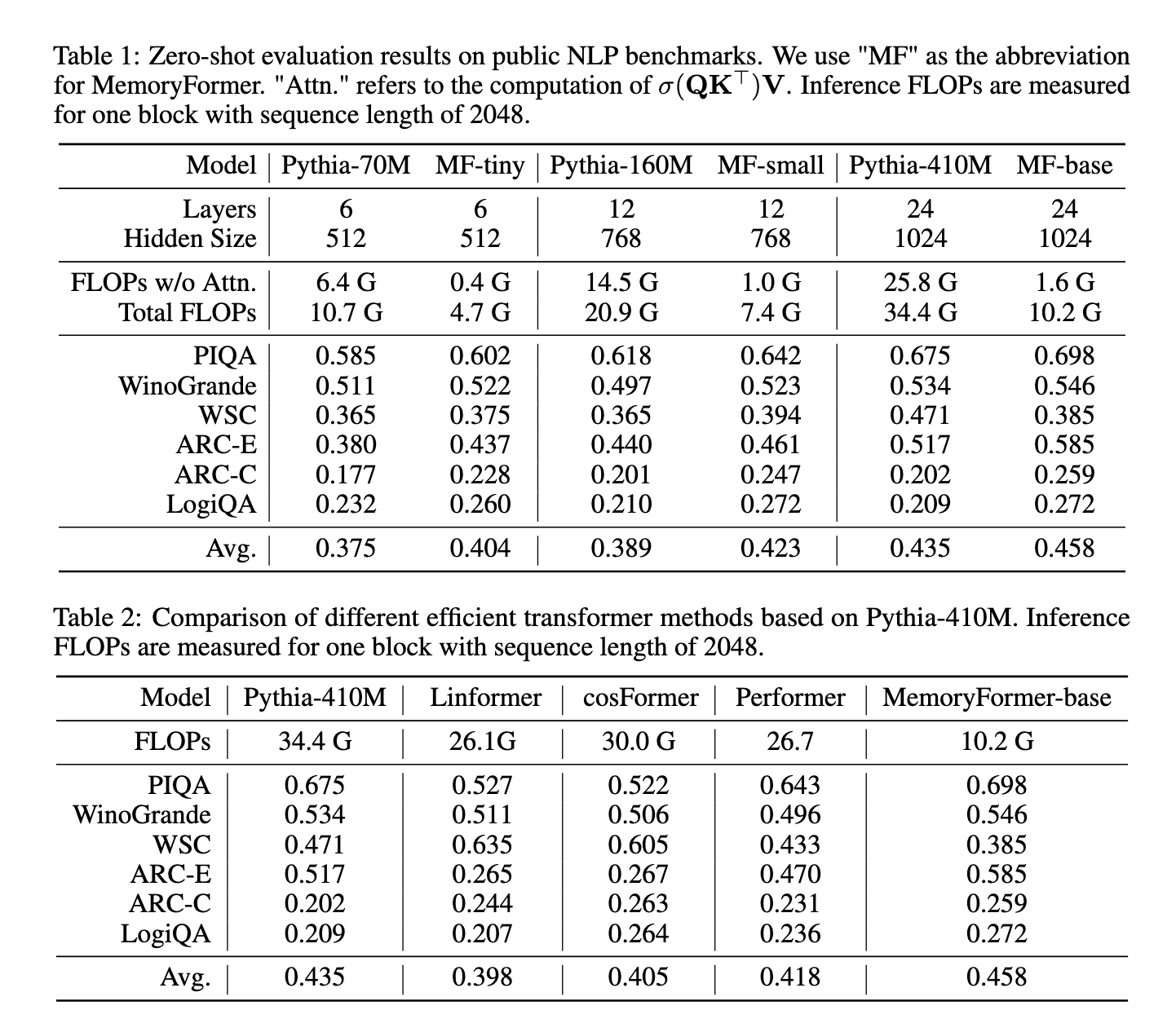
MemoryFormer demonstrated distinctive efficiency and effectivity throughout experiments carried out throughout a number of NLP benchmarks. For sequence lengths of 2048 tokens, MemoryFormer decreased the computational complexity of totally linked layers by over an order of magnitude. The computational FLOPs for MemoryFormer have been decreased to only 19% of a normal transformer block’s necessities. On particular duties, resembling PIQA and ARC-E, the MemoryFormer achieved accuracy scores of 0.698 and 0.585, respectively, surpassing the baseline transformer fashions. The general common accuracy throughout evaluated duties additionally improved, highlighting the mannequin’s capability to take care of or improve efficiency whereas considerably decreasing computational overhead.
The researchers in contrast MemoryFormer with present environment friendly transformer strategies, together with Linformer, Performer, and Cosformer. MemoryFormer constantly outperformed these fashions when it comes to computational effectivity and benchmark accuracy. For instance, in comparison with Performer and Linformer, which achieved common accuracies of 0.418 and 0.398, respectively, MemoryFormer reached 0.458 whereas using fewer sources. Such outcomes underline the effectiveness of its Reminiscence Layer in optimizing transformer architectures.
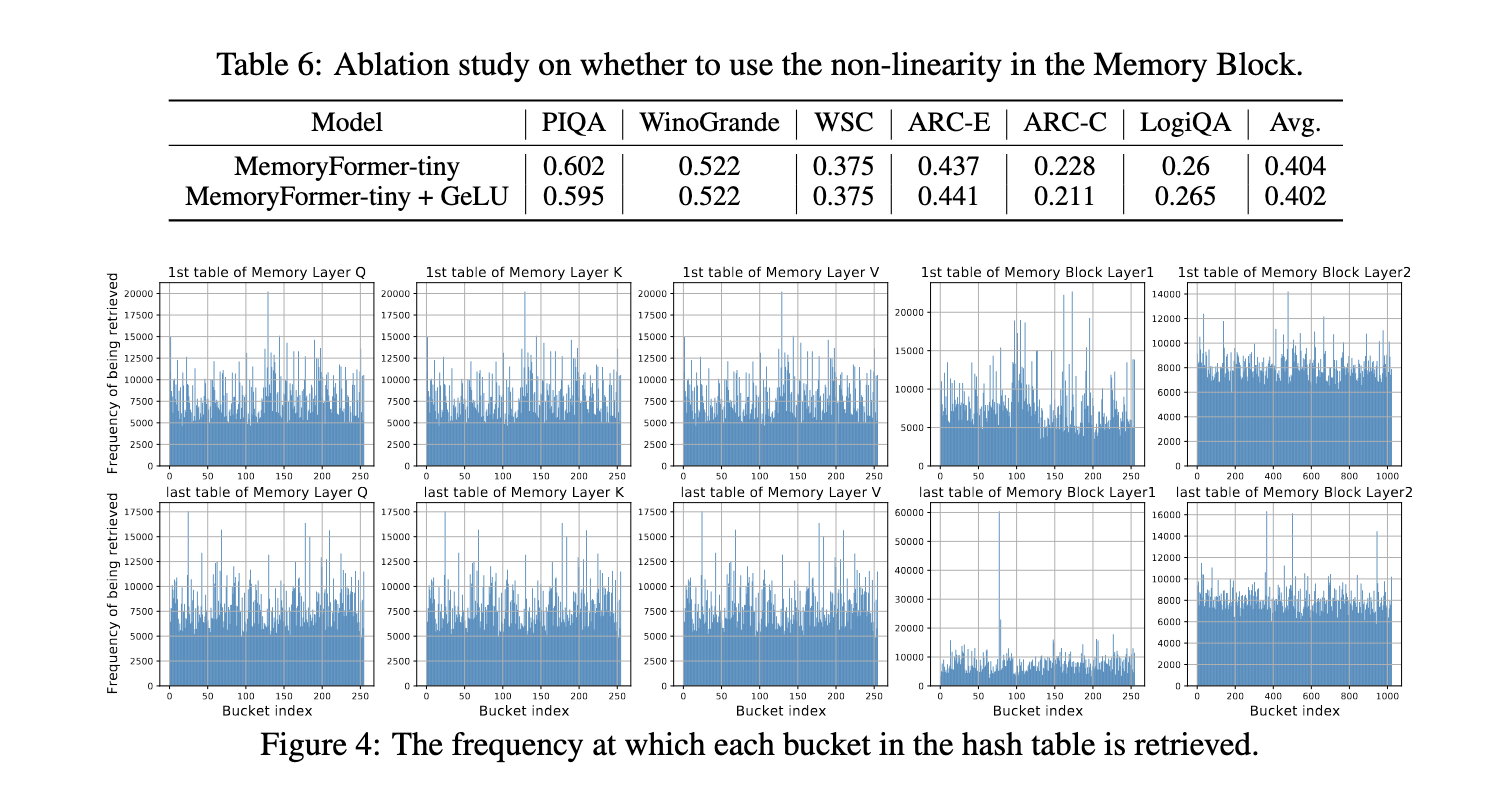
In conclusion, MemoryFormer addresses the constraints of transformer fashions by minimizing computational calls for by means of the progressive use of Reminiscence Layers. The researchers demonstrated a transformative method to balancing efficiency and effectivity by changing fully-connected layers with memory-efficient operations. This structure supplies a scalable pathway for deploying massive language fashions throughout various functions, guaranteeing accessibility and sustainability with out compromising accuracy or functionality.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Digital GenAI Convention ft. Meta, Mistral, Salesforce, Harvey AI & extra. Be a part of us on Dec eleventh for this free digital occasion to be taught what it takes to construct large with small fashions from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and extra.
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.