{kind=link}

Understanding monetary data means analyzing numbers, monetary phrases, and arranged information like tables for helpful insights. It requires math calculations and data of financial ideas, guidelines, and relationships between monetary phrases. Though subtle AI fashions have proven glorious common reasoning capability, their suitability for monetary duties is questionable. Such duties require greater than easy mathematical calculations since they contain deciphering domain-specific vocabulary, recognizing relationships between monetary factors, and analyzing structured monetary information.
Typically, reasoning approaches like chain-of-thought fine-tuning and reinforcement studying enhance efficiency on a number of duties however collapse with monetary rationale. They enhance logical reasoning however can’t replicate the complexity of financial data, which requires numerical comprehension, data of the sphere, and information interpretation in an organized method. Whereas massive language fashions are broadly utilized in finance for duties like sentiment evaluation, market prediction, and automatic buying and selling, common fashions aren’t optimized for monetary reasoning. Finance-specific fashions, equivalent to BloombergGPT and FinGPT, assist perceive monetary phrases however nonetheless face challenges in reasoning over monetary paperwork and structured information.
To unravel this, researchers from TheFinAI proposed Fino1, a monetary reasoning mannequin based mostly on Llama-3.1-8B-Instruct. Present fashions struggled with monetary textual content, tabular information, and equations, exhibiting poor efficiency in long-context duties and multi-table reasoning. Easy dataset enhancements and common strategies like CoT fine-tuning didn’t carry constant outcomes. This framework employed reinforcement studying and iterative CoT fine-tuning to reinforce monetary reasoning, logical step refinement, and decision-making accuracy. Logical sequences have been constructed systematically so the mannequin may analyze monetary points step-by-step, and verification mechanisms examined reliability to find out right monetary conclusions. Two-stage LoRA fine-tuning resolved contradictions in numerical reasoning and equation fixing, with the primary stage fine-tuning the mannequin to monetary rules and the second stage fine-tuning intricate calculations. Organized coaching on varied finance datasets, equivalent to studies and tabular information, enhanced interpretation to offer extra correct monetary statements and transaction data evaluation.
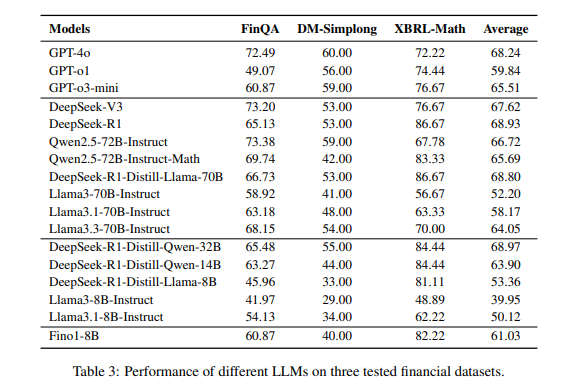
Researchers evaluated language fashions on monetary reasoning duties and located DeepSeek-R1 carried out greatest (68.93) as a result of sturdy XBRL–Math outcomes, adopted by DeepSeek-R1-Distill-Llama-70B and DeepSeek-R1-Distill-Qwen-32B. GPT-4o carried out properly however lagged as a result of decrease XBRL-Math scores. Basic-purpose fashions like Llama3.3-70B outperformed some reasoning-focused fashions, exhibiting that common reasoning didn’t at all times improve monetary duties. Researchers discovered that logical-task fine-tuning struggled with financial information, whereas mathematical enhancements improved XBRL-Math however harm FinQA and DM-Simplong accuracy. Scaling mannequin measurement didn’t at all times assist, as smaller fashions typically carried out higher. Increasing pre-training information and refining post-training strategies improved monetary reasoning. Fino1-8B, educated with reasoning paths from GPT-4o, outperformed others, proving financial-specific coaching was efficient. These outcomes highlighted the significance of domain-specific coaching to enhance monetary understanding and multi-step numerical reasoning.
In abstract, the brand new method improved monetary considering in LLMs. By making the most of reasonability paths from GPT-4o on FinQA, Fino1 was 10% higher throughout three monetary checks. Though formal mathematical fashions carried out greatest on numerical duties equivalent to XBRL-Math, they fell wanting expectations in processing monetary textual content and lengthy contexts, with area adaptation essential. Regardless of the mannequin scale and dataset variety limitations, this framework can act as a baseline for future analysis. Developments in dataset growth, retrieval-augmented strategies, and multi-step reasoning can additional improve monetary LLMs for real-world purposes.
Take a look at the Paper and Mannequin on Hugging Face. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 75k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Information Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and remedy challenges.
