{kind=link}

Automated differentiation has reworked the event of machine studying fashions by eliminating advanced, application-dependent gradient derivations. This transformation helps to calculate Jacobian-vector and vector-Jacobian merchandise with out creating the complete Jacobian matrix, which is essential for tuning scientific and probabilistic machine studying fashions. In any other case, it will require a column for every neural community parameter. These days, everybody can construct algorithms round matrices of huge sizes by exploiting this matrix-free method. Nonetheless, differentiable linear algebra for Jacobian-vector merchandise and related operations has remained largely unexplored to today and conventional strategies even have some flaws.
Present strategies for evaluating capabilities of huge matrices primarily depend on Lanczos and Arnoldi iterations, which require good computation energy and will not be optimized for differentiation. Generative fashions depended totally on the change-of-variables method, which includes the log-determinant of the Jacobian matrix of a neural community. To optimize mannequin parameters in Gaussian processes, it is very important calculate gradients of log-probability capabilities that contain many giant covariance matrices. Utilizing strategies that mix random hint estimation with the Lanczos iteration helps to extend the pace of convergence. Among the latest work makes use of some mixture of stochastic hint estimation with the Lanczos iteration and agrees on gradients of log determinants. Not like in Gaussian processes, prior work on Laplace approximations tries to simplify the Generalized Gauss-Newton (GGN) matrix by utilizing solely sure teams of community weights or by varied algebraic strategies like diagonal or low-rank approximations. These strategies make it simple to compute log determinants robotically, however they lose vital particulars in regards to the correlation between weights.
To mitigate these challenges and as a step in direction of the exploration of differentiable linear algebra, researchers proposed a brand new matrix-free methodology for robotically differentiating capabilities of matrices.
A bunch of researchers from the Technical College of Denmark and Kongens Lyngby, Denmark, performed detailed analysis and derived beforehand unknown adjoint techniques for Lanczos and Arnoldi iterations, implementing them in JAX, and confirmed that the ensuing code might compete with Diffrax on the subject of differentiating PDEs, GPyTorch for choosing Gaussian course of fashions. Additionally, it beats customary factorization strategies for calibrating Bayesian neural networks.
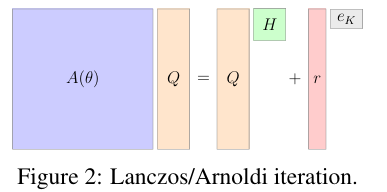
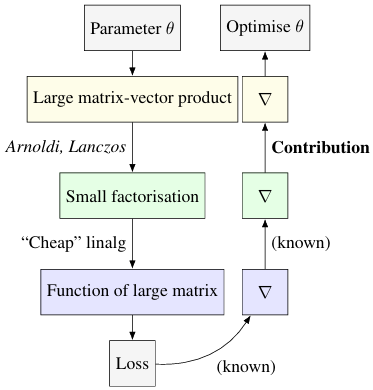
On this, the researchers primarily centered on matrix-free algorithms that keep away from direct matrix storage and as a substitute function by way of matrix-vector merchandise. The Lanczos and Arnoldi iterations are widespread for matrix decomposition in a matrix-free method, which produces smaller and structured matrices that approximate the big matrix, making it simple to guage matrix capabilities. The proposed methodology can effectively discover the derivatives of capabilities associated to giant matrices with out creating the complete Jacobian matrix. This matrix-free method evaluates Jacobian-vector and vector-Jacobian merchandise, making it appropriate for large-scale machine-learning fashions. Additionally, the implementation in JAX ensures excessive efficiency and scalability.
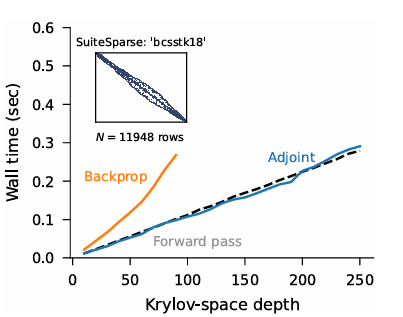
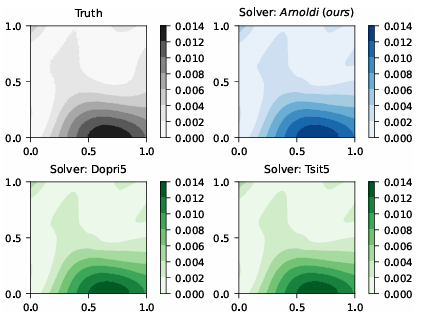
The tactic is just like the adjoint methodology, and this new algorithm is quicker than backpropagation and shares the identical stability advantages as the unique calculations. The code was examined on three advanced machine-learning issues to see the way it compares with present strategies for Gaussian processes, differential equation solvers, and Bayesian neural networks. The findings performed by the researchers present that the mixing of Lanczos iterations and Arnoldi strategies drastically enhances effectivity and accuracy in machine studying, which unlocks new coaching, testing, and calibration strategies and highlights how vital superior math strategies are for making machine studying fashions work higher in numerous areas.
In conclusion, the proposed methodology mitigates issues that the normal methodology faces and doesn’t require creating giant matrices to seek out the variations in capabilities. Additionally, it addresses and solves the computing difficulties of present strategies and enhances the effectivity and accuracy of probabilistic machine studying fashions. Nonetheless, there are specific limitations to this methodology, comparable to challenges with forward-mode differentiation and the belief that the orthogonalized matrix can slot in reminiscence. Future work could lengthen this framework by addressing these constraints and exploring functions in varied fields, particularly in Machine studying, which can require variations for complex-valued matrices!
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Neighborhood Members
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Information Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and resolve challenges.