{kind=link}

Massive Language Fashions (LLMs) have develop into more and more essential in cybersecurity, significantly of their utility to safe coding practices. As these AI-driven fashions can generate human-like textual content, they’re now being utilized to detect and mitigate safety vulnerabilities in software program. The first aim is to harness these fashions to boost the safety of code, which is crucial in stopping potential cyberattacks and making certain the integrity of software program techniques. The combination of AI in cybersecurity represents a big development in automating the identification and determination of code vulnerabilities, which has historically relied on handbook processes.
A urgent downside in cybersecurity is the persistent presence of vulnerabilities in software program code that malicious actors can exploit. These vulnerabilities typically come up from easy coding errors or neglected safety flaws throughout software program growth. Conventional strategies, akin to handbook code opinions and static evaluation, are solely generally efficient in catching all potential vulnerabilities, particularly as software program techniques develop more and more advanced. The problem lies in growing automated options that may precisely determine and repair these points earlier than they’re exploited, thereby enhancing the general safety of the software program.
Present instruments for safe coding embody static analyzers like CodeQL and Bandit, that are broadly used within the business to scan codebases for identified safety vulnerabilities. These instruments work by analyzing the code with out executing it and figuring out potential safety flaws primarily based on predefined patterns and guidelines. Nonetheless, whereas these instruments successfully detect widespread vulnerabilities, they’re restricted by their reliance on predefined guidelines, which can not account for brand new or advanced safety threats. Moreover, Automated Program Restore (APR) instruments have been developed to repair bugs in code robotically. Nonetheless, these instruments sometimes give attention to less complicated points and infrequently fail to deal with extra advanced vulnerabilities, leaving gaps within the safety of the code.
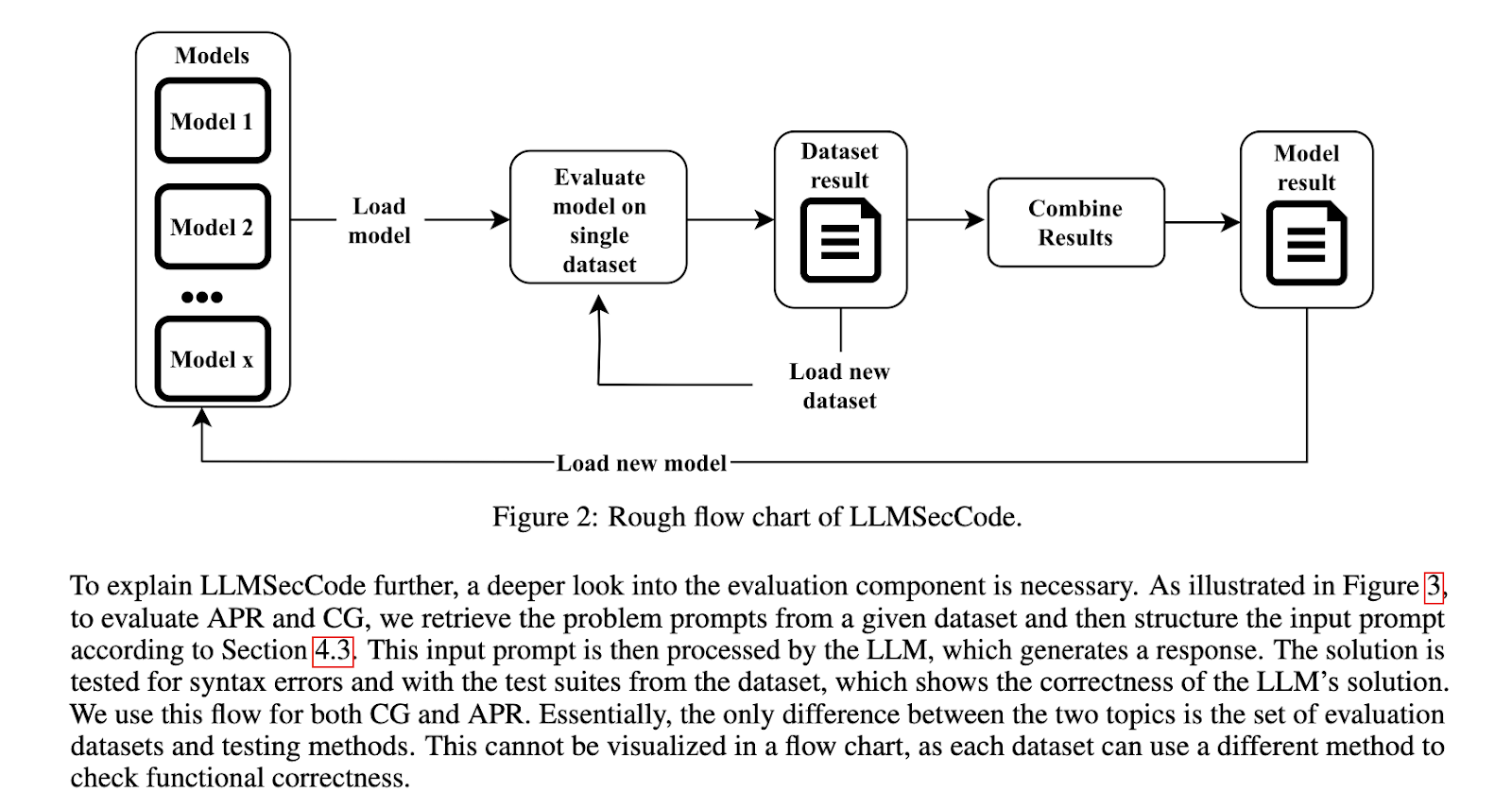
Researchers from Chalmers College of Expertise in Sweden have launched LLMSecCode, an revolutionary open-source framework designed to guage the safe coding capabilities of LLMs. This framework represents a big step ahead within the standardization and benchmarking LLMs for safe coding duties. LLMSecCode supplies a complete platform for assessing how effectively completely different LLMs can generate safe code and restore vulnerabilities. By integrating this framework, researchers purpose to streamline the method of evaluating LLMs, making it simpler to find out which fashions are only for safe coding. The framework’s open-source nature additionally encourages additional growth and collaboration inside the analysis group.
The LLMSecCode framework operates by various key parameters of LLMs, akin to temperature and top-p, that are essential in figuring out the mannequin’s output. By adjusting these parameters, researchers can observe how adjustments have an effect on the LLM’s capability to generate safe code and determine vulnerabilities. The framework helps a number of LLMs, together with CodeLlama and DeepSeekCoder, among the many present state-of-the-art fashions in safe coding. LLMSecCode additionally permits for the customization of prompts, enabling researchers to tailor the duties to particular wants. This customization is crucial in evaluating the mannequin’s efficiency throughout safe coding eventualities. The framework is designed to be adaptable & scalable, making it appropriate for varied safe coding duties.


The efficiency of LLMSecCode was rigorously examined utilizing varied LLMs, yielding important insights into their capabilities. The researchers discovered that DeepSeek Coder 33B Instruct achieved exceptional success in Automated Program Restore (APR) duties, fixing as much as 78.7% of the challenges it was introduced with. In distinction, Llama 2 7B Chat excelled in security-related duties, with 76.5% of its generated code being free from vulnerabilities. These figures spotlight the various strengths of various LLMs and underscore the significance of choosing the correct mannequin for particular duties. Moreover, the framework demonstrated a ten% distinction in efficiency when various mannequin parameters and a 9% distinction when modifying prompts, showcasing the sensitivity of LLMs to those components. The researchers additionally in contrast the outcomes of LLMSecCode with these of dependable exterior actors, discovering solely a 5% distinction, which attests to the framework’s accuracy and reliability.
In conclusion, the analysis carried out by the Chalmers College of Expertise crew presents LLMSecCode as a groundbreaking device for evaluating the safe coding capabilities of LLMs. By offering a standardized evaluation framework, LLMSecCode helps determine the simplest LLMs for safe coding, thereby contributing to the event of safer software program techniques. The findings emphasize the significance of choosing the suitable mannequin for particular coding duties and display that whereas LLMs have made important strides in safe coding, there’s nonetheless room for enchancment and additional analysis.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and LinkedIn. Be part of our Telegram Channel. Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.