{kind=link}

In giant language fashions (LLMs), processing prolonged enter sequences calls for important computational and reminiscence sources, resulting in slower inference and better {hardware} prices. The eye mechanism, a core element, additional exacerbates these challenges as a result of its quadratic complexity relative to sequence size. Additionally, sustaining the earlier context utilizing a key-value (KV) cache leads to excessive reminiscence overheads, limiting scalability.
A key limitation of LLMs is their incapability to deal with sequences longer than their educated context window. Most fashions degrade in efficiency when confronted with prolonged inputs as a result of inefficient reminiscence administration and rising consideration computation prices. Present options usually depend on fine-tuning, which is resource-intensive and requires high-quality long-context datasets. With out an environment friendly technique for context extension, duties like doc summarization, retrieval-augmented era, and long-form textual content era stay constrained.
A number of approaches have been proposed to deal with the issue of long-context processing. FlashAttention2 (FA2) optimizes reminiscence consumption by minimizing redundant operations throughout consideration computation, but it doesn’t handle computational inefficiency. Some fashions make use of selective token consideration, both statically or dynamically, to scale back processing overhead. KV cache eviction methods have been launched to take away older tokens selectively, however they danger completely discarding essential contextual info. HiP Consideration is one other method that makes an attempt to dump sometimes used tokens to exterior reminiscence; nonetheless, it lacks environment friendly cache administration, resulting in elevated latency. Regardless of these advances, no technique has successfully addressed all three key challenges:
- Lengthy-context generalization
- Environment friendly reminiscence administration
- Computational effectivity
Researchers from the KAIST, and DeepAuto.ai launched InfiniteHiP, a sophisticated framework that permits environment friendly long-context inference whereas mitigating reminiscence bottlenecks. The mannequin achieves this by a hierarchical token pruning algorithm, which dynamically removes much less related context tokens. This modular pruning technique selectively retains tokens that contribute essentially the most to consideration computations, considerably lowering processing overhead. The framework additionally incorporates adaptive RoPE (Rotary Positional Embeddings) changes, permitting fashions to generalize to longer sequences with out extra coaching. Additionally, InfiniteHiP employs a novel KV cache offloading mechanism, transferring much less often accessed tokens to host reminiscence whereas guaranteeing environment friendly retrieval. These methods allow the mannequin to course of as much as 3 million tokens on a 48GB GPU, making it essentially the most scalable long-context inference technique.
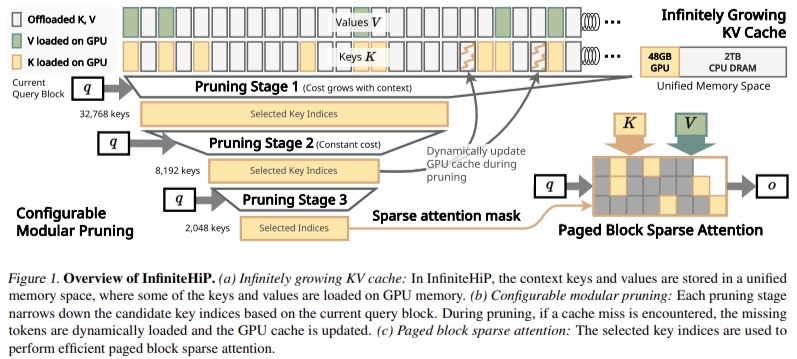
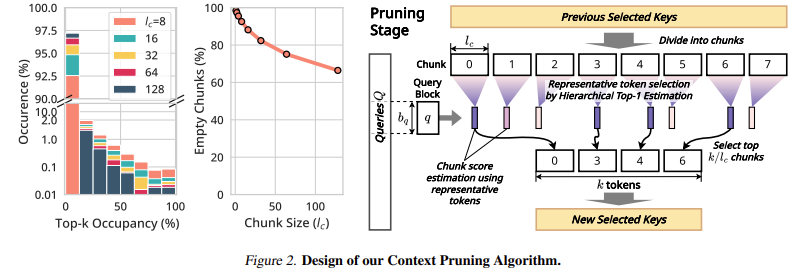
The core innovation of InfiniteHiP is its multi-stage pruning mechanism, which constantly improves context choice all through a number of levels. Tokens are first divided into fixed-length items, and every bit is processed based mostly on its consideration computation contribution. A top-Okay choice method ensures that solely essentially the most vital tokens are retained and others are dropped. The tactic adopted by InfiniteHiP, in contrast to different hierarchical pruning fashions, is totally parallelized, which renders it computationally efficient. The KV cache administration system optimizes reminiscence utilization by dynamically offloading much less essential context tokens whereas sustaining retrieval flexibility. The mannequin additionally makes use of a number of RoPE interpolation strategies at totally different consideration layers, thus facilitating clean adaptation to lengthy sequences.
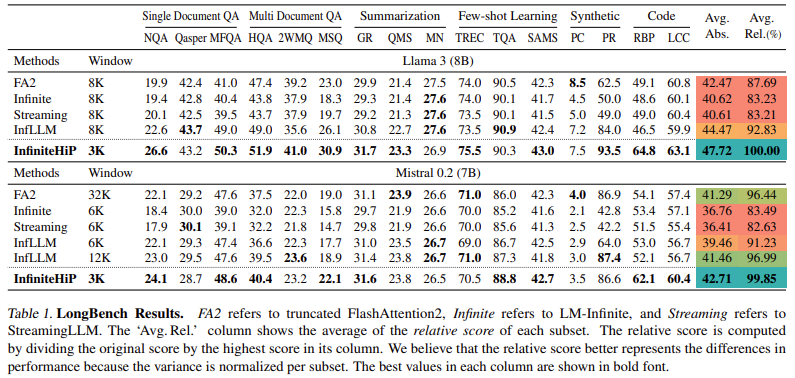
The mannequin demonstrates an 18.95× speedup in consideration decoding for a one million-token context in comparison with conventional strategies with out extra coaching. The KV cache offloading method reduces GPU reminiscence consumption by as much as 96%, making it sensible for large-scale purposes. In benchmark evaluations comparable to LongBench and ∞Bench, InfiniteHiP constantly outperforms state-of-the-art strategies, attaining a 9.99% increased relative rating than InfLLM. Additionally, decoding throughput is elevated by 3.2× on client GPUs (RTX 4090) and seven.25× on enterprise-grade GPUs (L40S).
In conclusion, the analysis group efficiently addressed the key bottlenecks of long-context inference with InfiniteHiP. The framework enhances LLM capabilities by integrating hierarchical token pruning, KV cache offloading, and RoPE generalization. This breakthrough allows pre-trained fashions to course of prolonged sequences with out dropping context or rising computational prices. The tactic is scalable, hardware-efficient, and relevant to varied AI purposes requiring long-memory retention.
Take a look at the Paper, Supply Code and Stay Demo. All credit score for this analysis goes to the researchers of this mission. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 75k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.