{kind=link}

Comprehension and administration of large-scale software program repositories is a recurring drawback in modern software program growth. Though present instruments shine when summarizing small code entities equivalent to features, they battle to scale to repository-level artifacts equivalent to recordsdata and packages. These extra summary summaries are very important for comprehending the intent and conduct of total codebases, notably in enterprise functions the place technical summaries should be aligned with enterprise objectives. In accordance with numerous reviews, this void ends in inefficiencies, with builders spending over 50% of their time understanding present code. These inefficiencies negatively influence productiveness and decelerate the event and upkeep of programs equivalent to Enterprise Help Techniques (BSS) within the telecommunications trade.
Conventional summarization strategies, together with rule-based and template-driven approaches, fail to fulfill the necessities of large-scale codebases. Whereas machine studying developments, equivalent to neural machine translation and transformer-based fashions, have improved summarization for small code items, they typically depend on datasets like CodeSearchNet and CodeXGLUE that target system-level code. This slender focus limits their effectiveness in domain-specific and business-context functions. Code-specific massive language fashions (LLMs), equivalent to CodeLlama and StarCoder, improve efficiency however can not align summaries with broader enterprise intent. In the meantime, closed-source LLMs, together with GPT, provide superior accuracy however elevate privateness issues, making them unsuitable for proprietary enterprise software program. These limitations go away a big hole in repository-level summarization, particularly for large-scale functions that require understanding technical particulars and domain-specific nuances.
Researchers from the TCS Analysis suggest a novel hierarchical framework for summarizing repository-level code, particularly designed for enterprise functions. This technique goals to beat the constraints of present practices via native LLM-based privateness preservation and domain-specific grounding for relevance. The method consists of dividing massive code artifacts into tractable items like features, variables, and constructors through Summary Syntax Tree (AST) parsing. Particular person segments are summarized individually, and their summaries are then mixed into file-level and package-level summations.
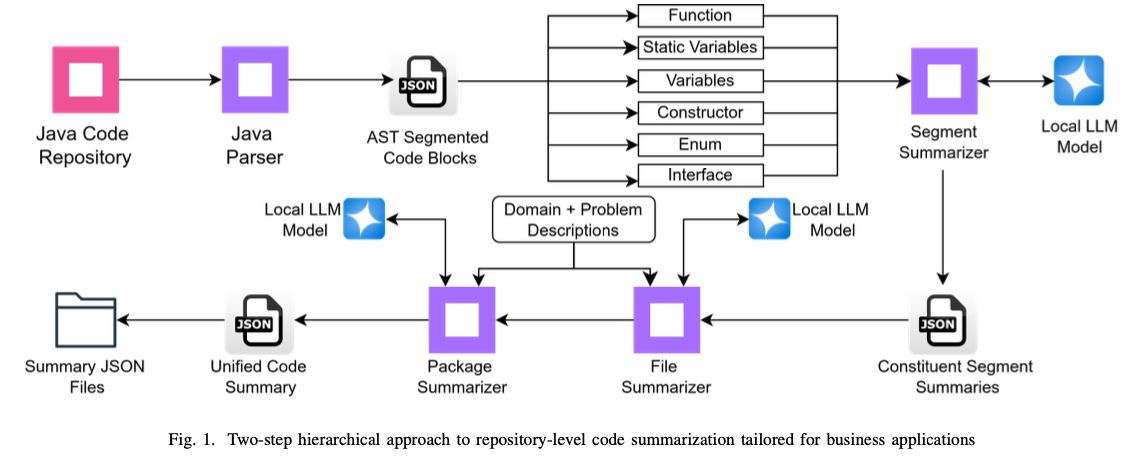
A particular side of this framework is the incorporation of domain-specific and problem-context information via customized prompts. By embedding the summarization course of within the telecommunication sector’s enterprise objectives and working atmosphere, the approach ensures that summaries establish the higher-level intent and usefulness of code artifacts. The approach ensures not solely that summaries are thorough but additionally goal-directed in accordance with the needs of enterprise programs equivalent to BSS, the place comprehension of the code’s goal is as vital as its technical nature.
The method employs AST parsing to establish logical segments from supply recordsdata, together with features, enums, and variables, that are summarized individually with personalized prompts. Capabilities, for instance, are outlined by analyzing their inputs, outputs, workflows, uncomfortable side effects, and basic goal, whereas variables and enums are described when it comes to their perform throughout the bigger utility. These summaries on the section degree are aggregated into file-level summaries, which describe the file’s goal and performance throughout the repository. Likewise, file-level summaries are aggregated into package-level summaries, which give a whole image of the repository’s construction and performance. To make the summaries correct and related, the construction consists of domain-specific descriptions, together with ones about telecommunications and the working atmosphere of BSS. This grounding permits the summaries to seize not solely the technicalities of the code but additionally the alignment of the code with the general enterprise goals, making them very apt to be used in enterprise environments.

The researchers evaluated the framework utilizing a publicly obtainable GitHub repository designed to simulate the traits of a telecommunications BSS. The hierarchical construction of the summarization course of ensured complete protection of all code segments, resolving the omission points noticed with conventional strategies. By systematically summarizing particular person elements, the method captured all related particulars, making certain a whole and correct illustration of the repository. Grounding the summaries in domain-specific and problem-context information considerably enhanced their high quality, bettering area relevance by over 7% and completeness by 13%, all whereas sustaining conciseness and cohesiveness. Efficiency assessments with metrics like ROUGE-L, BLEU, and BERTScore confirmed important beneficial properties over baseline approaches, reflecting the correctness and context-sensitivity of the summaries. Furthermore, skilled assessments from the telecommunication sector validated the informativeness and relevance of the produced summaries, affirming their correspondence to enterprise goals and technical specs. This holistic method was particularly efficient in producing aligned, insightful summaries that meet the actual necessities of enterprise software program growth.
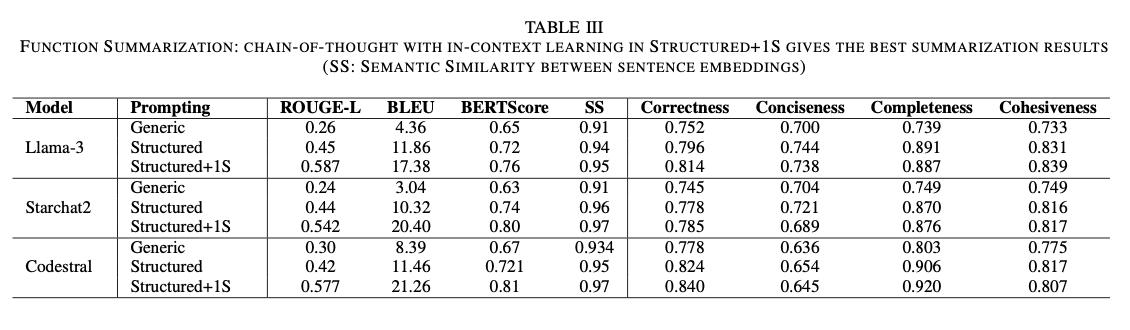
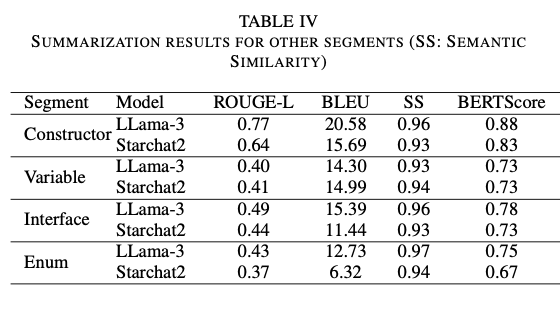

This hierarchical repository-level code summarization framework represents an vital leap ahead within the understanding and upkeep of enterprise functions. Via the decomposition of intricate codebases into understandable items and the inclusion of area experience, the method ensures correct, pertinent, and business-focused summaries. It may well successfully overcome the shortcomings of present strategies, permitting builders to reinforce productiveness and simplify upkeep procedures. The approach guarantees prolonged applicability in different domains like healthcare and finance, with potential future extensions encompassing multimodal performance to additional improve code understanding.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 70k+ ML SubReddit.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s captivated with information science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.