{kind=link}

Introduction
Giant Language Mannequin Operations (LLMOps) is an extension of MLOps, tailor-made particularly to the distinctive challenges of managing large-scale language fashions like GPT, PaLM, and BERT. Whereas MLOps focuses on the lifecycle of machine studying fashions normally, LLM Ops addresses the complexities launched by fashions with billions of parameters, similar to dealing with resource-intensive computations, optimizing inference, lowering latency, and making certain dependable efficiency in manufacturing environments. Tremendous-tuning these fashions, managing scalability, and monitoring them in real-time are all crucial to their profitable deployment.
This information explores these complexities and affords sensible options for managing giant language fashions successfully. Whether or not you’re scaling fashions, optimizing efficiency, or implementing strong monitoring, this information will stroll you thru key methods for effectively managing giant language fashions in manufacturing environments.
Studying Goals
- Achieve perception into the particular challenges and concerns of managing giant language fashions in comparison with conventional machine studying fashions.
- Discover superior strategies for scaling LLM inference, together with mannequin parallelism, tensor parallelism, and sharding.
- Perceive the crucial elements and greatest practices for creating and sustaining environment friendly LLM pipelines.
- Uncover optimization strategies similar to quantization and mixed-precision inference to enhance efficiency and scale back useful resource consumption.
- Discover ways to combine monitoring and logging instruments to trace efficiency metrics, error charges, and system well being for LLM functions.
- Perceive methods to arrange steady integration and deployment pipelines tailor-made for LLMs, making certain environment friendly mannequin versioning and deployment processes.
This text was revealed as part of the Knowledge Science Blogathon.
Establishing a LLM Pipeline
A typical LLM workflow consists of a number of levels, beginning with information preparation, adopted by mannequin coaching (or fine-tuning if utilizing pre-trained fashions), deployment, and steady monitoring as soon as the mannequin is in manufacturing. Whereas coaching giant language fashions from scratch may be computationally costly and time-consuming, most use instances depend on fine-tuning current fashions like GPT, BERT, or T5 utilizing platforms like Hugging Face.
The core thought behind organising an LLM pipeline is to allow environment friendly interplay between customers and the mannequin by leveraging REST APIs or different interfaces. After deploying the mannequin, monitoring and optimizing efficiency turns into essential to make sure the mannequin is scalable, dependable, and responsive. Beneath, we’ll stroll via a simplified instance of deploying a pre-trained LLM for inference utilizing Hugging Face Transformers and FastAPI to create a REST API service.
Constructing an LLM Inference API with Hugging Face and FastAPI
On this instance, we’ll arrange an LLM inference pipeline that hundreds a pre-trained mannequin, accepts consumer enter (prompts), and returns generated textual content responses via a REST API.
Step 1: Set up Required Dependencies
pip set up fastapi uvicorn transformersThese packages are essential to arrange the API and cargo the pre-trained mannequin. FastAPI is a high-performance net framework, uvicorn is the server to run the API, and transformers is used to load the LLM.
Step 2: Create the FastAPI Software
Right here, we construct a easy FastAPI software that hundreds a pre-trained GPT-style mannequin from Hugging Face’s mannequin hub. The API will settle for a consumer immediate, generate a response utilizing the mannequin, and return the response.
from fastapi import FastAPI
from transformers import AutoModelForCausalLM, AutoTokenizer
app = FastAPI()
# Load pre-trained mannequin and tokenizer
model_name = "gpt2" # You may substitute this with different fashions like "gpt-neo-1.3B" or "distilgpt2"
mannequin = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
@app.put up("/generate/")
async def generate_text(immediate: str):
# Tokenize the enter immediate
inputs = tokenizer(immediate, return_tensors="pt")
# Generate output from the mannequin
outputs = mannequin.generate(inputs["input_ids"], max_length=100, num_return_sequences=1)
# Decode the generated tokens again into textual content
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Return the generated textual content because the API response
return {"response": generated_text}
# To run the FastAPI app, use: uvicorn.run(app, host="0.0.0.0", port=8000)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)Anticipated Output: Whenever you run the FastAPI app, you may work together with it utilizing a software like Postman, cURL, or the Swagger UI offered by FastAPI at http://localhost:8000/docs. Right here’s an instance of the interplay:
Request (POST to /generate/):
{
"immediate": "As soon as upon a time, in a distant land,"
}Response (generated by the mannequin):
{
"response": "As soon as upon a time, in a distant land, the solar was shining,
and the moon was shining, and the celebrities have been shining, and the celebrities have been
shining, and the celebrities have been shining, and the celebrities have been shining, and the celebrities
have been shining, and the celebrities have been shining, and the celebrities have been shining, and the
stars have been shining, and the celebrities have been shining, and the celebrities have been shining,
and the celebrities have been shining, and the celebrities have been shining, and the celebrities have been
shining, and"
}Step 3: Run the Software
As soon as the code is saved, you may run the appliance regionally with the next command:
uvicorn essential:app --reloadIt will launch the FastAPI server on http://127.0.0.1:8000/. The –reload flag ensures the server reloads everytime you make code adjustments.
Anticipated API Conduct
When operating the app, you may entry the Swagger UI at http://localhost:8000/docs. Right here, it is possible for you to to check the /generate/ endpoint by sending totally different prompts and receiving textual content responses generated by the mannequin. The anticipated habits is that for every immediate, the LLM will generate coherent textual content that extends the enter immediate.
For instance:
Immediate: “The way forward for AI is”.
Response: “The way forward for AI is vivid, with developments in machine studying, robotics, and pure language processing driving innovation throughout industries. AI will revolutionize how we reside and work, from healthcare to transportation.”
These are responses for a selected case. Beneath is the screenshot the place you may take a look at out extra such responses. Nevertheless, it could fluctuate from consumer to case thought of.
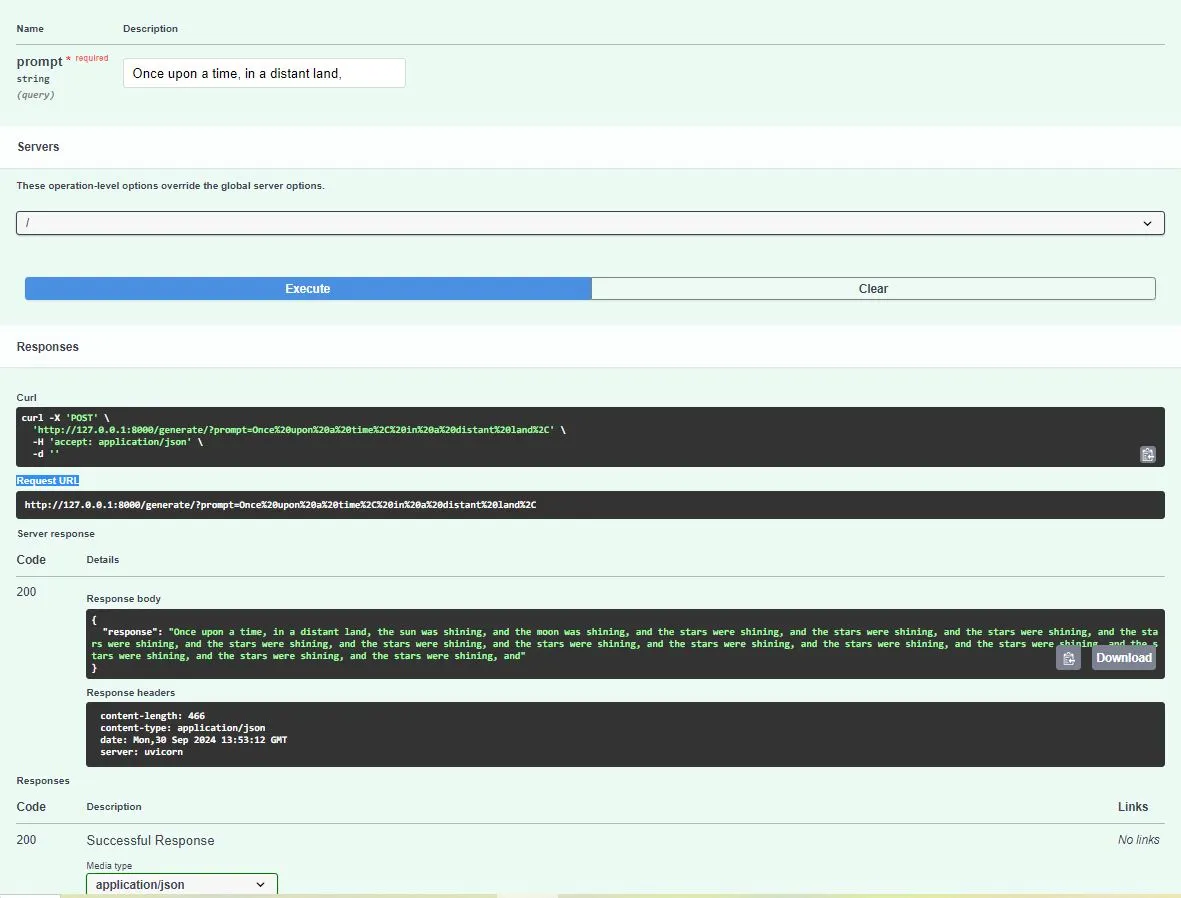
This straightforward pipeline showcases methods to load a pre-trained LLM mannequin, create a REST API for interplay, and deploy it for inference in a production-like setup. It types the idea of extra complicated LLM operations, the place scalability, optimization, and monitoring will likely be crucial, as we’ll discover additional on this weblog.
Scaling LLM Inference for Manufacturing
Scaling giant language fashions (LLMs) for manufacturing is a major problem as a result of their immense computational necessities. LLMs, similar to GPT or BERT derivatives, usually include billions of parameters, demanding giant quantities of reminiscence and computational sources, which might result in gradual inference instances and excessive operational prices. Inference for such fashions may be bottlenecked by GPU reminiscence limits, particularly when coping with bigger fashions (e.g., GPT-3 or PaLM) that won’t match completely into the reminiscence of a single GPU.
Listed here are a few of the essential challenges when scaling LLM inference:
- Excessive Reminiscence Necessities: LLMs require giant quantities of reminiscence (VRAM) to retailer parameters and carry out computations throughout inference, usually exceeding the reminiscence capability of a single GPU.
- Sluggish Inference Instances: Resulting from their measurement, producing responses from LLMs can take important time, affecting the consumer expertise. Every token technology might contain hundreds of matrix multiplications throughout thousands and thousands or billions of parameters.
- Value: Operating giant fashions, particularly in manufacturing environments the place scaling is required for a lot of concurrent requests, may be very costly. This contains each {hardware} prices (e.g., a number of GPUs or specialised accelerators) and vitality consumption.
To handle these challenges, strategies like mannequin parallelism, tensor parallelism, and sharding are employed. These strategies permit the distribution of mannequin parameters and computations throughout a number of gadgets or nodes, enabling bigger fashions to be deployed at scale.
Distributed Inference: Mannequin Parallelism, Tensor Parallelism, and Sharding
We’ll now find out about intimately about distributed inference under:
- Mannequin Parallelism: This method divides the mannequin itself throughout a number of GPUs or nodes. Every GPU is accountable for part of the mannequin’s layers, and information is handed between GPUs as computations progress via the mannequin. This strategy permits the inference of very giant fashions that don’t match into the reminiscence of a single machine.
- Tensor Parallelism: On this strategy, particular person layers of the mannequin are cut up throughout a number of gadgets. For example, the weights of a single layer may be cut up amongst a number of GPUs, permitting parallel computation of that layer’s operations. This methodology optimizes reminiscence utilization by distributing the computation of every layer somewhat than distributing total layers.
- Sharding: Sharding includes dividing the mannequin’s parameters throughout a number of gadgets and executing computations in parallel. Every shard holds part of the mannequin, and computation is finished on the particular subset of the mannequin that resides on a selected machine. Sharding is usually used with strategies like DeepSpeed and Hugging Face Speed up to scale LLMs successfully.
Instance Code: Implementing Mannequin Parallelism Utilizing DeepSpeed
To exhibit distributed inference, we’ll use DeepSpeed, a framework designed to optimize large-scale fashions via strategies like mannequin parallelism and mixed-precision coaching/inference. DeepSpeed additionally handles reminiscence and compute optimizations, enabling the deployment of enormous fashions throughout a number of GPUs.
Right here’s methods to use DeepSpeed for mannequin parallelism with a Hugging Face mannequin.
#Step 1: Set up Required Dependencies
pip set up deepspeed transformers
#Step 2: Mannequin Parallelism with DeepSpeed
import deepspeed
from transformers import AutoModelForCausalLM, AutoTokenizer
# Initialize DeepSpeed configurations
ds_config = {
"train_micro_batch_size_per_gpu": 1,
"optimizer": {
"kind": "AdamW",
"params": {
"lr": 1e-5,
"betas": [0.9, 0.999],
"eps": 1e-8,
"weight_decay": 0.01
}
},
"fp16": {
"enabled": True # Allow mixed-precision (FP16) to scale back reminiscence footprint
}
}
# Load mannequin and tokenizer
model_name = "gpt-neo-1.3B" # You may select bigger fashions like GPT-3
mannequin = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Put together the mannequin for DeepSpeed
mannequin, optimizer, _, _ = deepspeed.initialize(mannequin=mannequin, config=ds_config)
# Perform to generate textual content utilizing the mannequin
def generate_text(immediate):
inputs = tokenizer(immediate, return_tensors="pt")
outputs = mannequin.generate(inputs["input_ids"], max_length=100)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Instance immediate
immediate = "The way forward for AI is"
print(generate_text(immediate))
On this code, DeepSpeed’s configuration allows mixed-precision inference to optimize reminiscence utilization and efficiency. The mannequin and tokenizer are loaded utilizing Hugging Face’s API, and DeepSpeed initializes the mannequin to distribute it throughout GPUs. The generate_text perform tokenizes the enter immediate, runs it via the mannequin, and decodes the generated output into human-readable textual content.
Anticipated Output: Operating the above code will generate textual content primarily based on the immediate utilizing the distributed inference setup with DeepSpeed. Right here’s an instance of the interplay:
Multi-GPU Mannequin Parallelism
To run the mannequin throughout a number of GPUs, you’ll have to launch the script with DeepSpeed’s command-line utility. For instance, when you’ve got two GPUs accessible, you may run the mannequin utilizing each with the next command:
deepspeed --num_gpus=2 your_script.pyIt will distribute the mannequin throughout the accessible GPUs, permitting you to deal with bigger fashions that may not in any other case match right into a single GPU’s reminiscence.
Anticipated Conduct in Manufacturing: Utilizing DeepSpeed for mannequin parallelism permits LLMs to scale throughout a number of GPUs, making it possible to deploy fashions that exceed the reminiscence capability of a single machine. The anticipated final result is quicker inference with decrease reminiscence utilization per GPU and, within the case of bigger fashions like GPT-3, the flexibility to even run them on commodity {hardware}. Relying on the GPU structure and mannequin measurement, this will additionally result in lowered inference latency, enhancing the consumer expertise in manufacturing environments.
Optimizing LLM Efficiency
Quantization is a mannequin optimization approach that reduces the precision of a mannequin’s weights and activations. This enables for sooner inference and decrease reminiscence utilization with out considerably impacting accuracy. By changing 32-bit floating-point numbers (FP32) into 8-bit integers (INT8), quantization drastically reduces the mannequin measurement and hastens computations, making it perfect for deployment on resource-constrained environments or for enhancing efficiency in manufacturing.
Instruments like ONNX Runtime and Hugging Face Optimum make it straightforward to use quantization to transformer fashions and guarantee compatibility with a variety of {hardware} accelerators.
Instance Code: Quantization with Hugging Face Optimum
The next code demonstrates making use of dynamic quantization to a pre-trained mannequin utilizing Hugging Face Optimum.
pip set up optimum[onnxruntime] transformers
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from optimum.onnxruntime import ORTModelForSequenceClassification
from optimum.onnxruntime.configuration import AutoQuantizationConfig
# Load the pre-trained mannequin and tokenizer
model_name = "bert-base-uncased"
mannequin = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Apply dynamic quantization
quantization_config = AutoQuantizationConfig.arm64() # Specify quantization config (e.g., INT8)
ort_model = ORTModelForSequenceClassification.from_transformers(
mannequin, quantization_config=quantization_config
)
# Inference with quantized mannequin
def classify_text(textual content):
inputs = tokenizer(textual content, return_tensors="pt")
outputs = ort_model(**inputs)
return outputs.logits.argmax(dim=-1).merchandise()
# Instance utilization
print(classify_text("The film was implausible!"))
Rationalization: On this code, we use Hugging Face Optimum to use dynamic quantization to a BERT mannequin for sequence classification. The mannequin is loaded utilizing the AutoModelForSequenceClassification API, and quantization is utilized through ONNX Runtime. This reduces the mannequin measurement and will increase inference pace, making it extra appropriate for real-time functions.
Monitoring and Logging in LLM Ops
Monitoring is essential for making certain optimum efficiency and reliability in LLM-based functions. It permits for real-time monitoring of metrics similar to inference latency, token utilization, and reminiscence consumption. Efficient monitoring helps determine efficiency bottlenecks, detects anomalies, and facilitates debugging via error logging. By sustaining visibility into the system, builders can proactively handle points and optimize consumer expertise.
Instruments for Monitoring
You may leverage a number of instruments to watch LLM functions successfully. The next dialogue particulars a number of related instruments, adopted by an overarching thought offered within the subsequent picture.
- Prometheus: A strong monitoring system and time-series database designed for reliability and scalability. It collects and shops metrics as time-series information, making it straightforward to question and analyze efficiency.
- Grafana: A visualization software that integrates with Prometheus, permitting customers to create dynamic dashboards for visualizing metrics and understanding system efficiency in actual time.
- OpenTelemetry: A complete set of APIs, libraries, and brokers for accumulating observability information, together with metrics, logs, and traces. It allows unified monitoring throughout distributed methods.
- LangSmith: A software particularly designed for LLM operations, providing options for monitoring and logging LLM efficiency. It focuses on monitoring immediate effectiveness, mannequin habits, and response accuracy.
- Neptune.ai: A metadata retailer for MLOps that gives monitoring and logging capabilities tailor-made for machine studying workflows, enabling groups to trace experiments, monitor mannequin efficiency, and handle datasets effectively.
These instruments collectively improve the flexibility to watch LLM functions, making certain optimum efficiency and reliability in manufacturing environments.
Steady Integration and Deployment (CI/CD) in LLM Ops
Steady Integration (CI) and Steady Deployment (CD) pipelines are important for sustaining the reliability and efficiency of machine studying fashions, however they require totally different concerns when utilized to giant language fashions (LLMs). Not like conventional machine studying fashions, LLMs usually contain complicated architectures and substantial datasets, which might considerably improve the time and sources required for coaching and deployment.
In LLM pipelines, CI focuses on validating adjustments to the mannequin or information, making certain that any modifications don’t negatively have an effect on efficiency. This could embody operating automated checks on mannequin accuracy, efficiency benchmarks, and compliance with information high quality requirements. CD for LLMs includes automating the deployment course of, together with the mannequin’s packaging, versioning, and integration into functions, whereas additionally accommodating the distinctive challenges of scaling and efficiency monitoring. Rigorously handle specialised {hardware} required for LLMs as a result of their measurement all through the deployment course of.
Model Management for LLM Fashions
Model management for LLMs is essential for monitoring adjustments and managing totally different iterations of fashions. This may be achieved utilizing instruments similar to:
- DVC (Knowledge Model Management): A model management system for information and machine studying initiatives that enables groups to trace adjustments in datasets, fashions, and pipelines. DVC integrates with Git, enabling seamless model management of each code and information artifacts.
- Hugging Face Mannequin Hub: A platform particularly designed for sharing and versioning machine studying fashions, notably transformers. It permits customers to simply add, obtain, and observe mannequin variations, facilitating collaboration and deployment.
These instruments assist groups handle mannequin updates effectively whereas sustaining a transparent historical past of adjustments, making it simpler to revert to earlier variations if wanted.
Utilizing GitHub Actions and Hugging Face Hub for Automated Deployment
Right here’s a simplified instance of methods to arrange a CI/CD pipeline utilizing GitHub Actions to routinely deploy a mannequin to Hugging Face Hub.
Step1: Create a GitHub Actions Workflow File
Create a file named .github/workflows/deploy.yml in your repository.
title: Deploy Mannequin
on:
push:
branches:
- essential
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- title: Checkout Code
makes use of: actions/checkout@v2
- title: Arrange Python
makes use of: actions/setup-python@v2
with:
python-version: '3.8'
- title: Set up Dependencies
run: |
pip set up transformers huggingface_hub
- title: Deploy to Hugging Face Hub
run: |
python deploy.py # A script to deal with the deployment logic
env:
HUGGINGFACE_HUB_TOKEN: ${{ secrets and techniques.HUGGINGFACE_HUB_TOKEN }}Step2: Deployment Script (deploy.py)
This script can add the mannequin to Hugging Face Hub.
from huggingface_hub import HfApi, HfFolder, Repository
# Load your mannequin and tokenizer
model_name = "your_model_directory"
repository_id = "your_username/your_model_name"
api = HfApi()
# Create a repo if it would not exist
api.create_repo(repo_id=repository_id, exist_ok=True)
# Push the mannequin to the Hugging Face Hub
repo = Repository(local_dir=model_name, clone_from=repository_id)
repo.git_pull()
repo.push_to_hub()Rationalization: On this setup, the GitHub Actions workflow is triggered at any time when adjustments are pushed to the principle department. It checks the code, units up the Python setting, and installs essential dependencies. The deployment script (deploy.py) handles the logic for pushing the mannequin to Hugging Face Hub, making a repository if it doesn’t exist already. This CI/CD pipeline streamlines the deployment course of for LLMs, enabling sooner iteration and collaboration inside groups.
Conclusion
Managing giant language fashions (LLMs) in manufacturing includes a complete understanding of assorted operational facets, together with scaling, optimizing, monitoring, and deploying these complicated fashions. As LLMs proceed to evolve and grow to be integral to many functions, the methodologies and instruments for successfully dealing with them may also advance. By implementing strong CI/CD pipelines, efficient model management, and monitoring methods, organizations can make sure that their LLMs carry out optimally and ship useful insights.
Trying forward, future traits in LLM Ops might embody higher immediate monitoring for understanding mannequin habits. Extra environment friendly inference strategies will assist scale back latency and prices. Elevated automation instruments will streamline the complete LLM lifecycle.
Key Takeaways
- LLMs face challenges like excessive reminiscence use and gradual inference, requiring strategies like mannequin parallelism and sharding.
- Implementing methods like quantization can considerably scale back mannequin measurement and improve inference pace with out sacrificing accuracy.
- Efficient monitoring is crucial for figuring out efficiency points, making certain reliability, and facilitating debugging via error logging.
- Tailor steady integration and deployment pipelines to deal with the complexities of LLMs, together with their structure and useful resource wants.
- Instruments like DVC and Hugging Face Mannequin Hub allow efficient model management for LLMs, facilitating collaboration and environment friendly mannequin replace administration.
Incessantly Requested Questions
A. LLM Ops tackles the distinctive challenges of enormous language fashions, like their measurement, excessive inference prices, and sophisticated architectures. Conventional MLOps, alternatively, covers a broader vary of machine studying fashions and doesn’t normally want the identical degree of useful resource administration or scaling as LLMs.
A. Optimize inference pace by making use of strategies like quantization, mannequin parallelism, and utilizing optimized runtime libraries similar to ONNX Runtime or Hugging Face Optimum. These strategies assist scale back the computational load and reminiscence utilization throughout inference.
A. Efficient instruments for monitoring LLMs embody Prometheus for accumulating metrics and Grafana for visualizing information. OpenTelemetry offers complete observability. LangSmith affords specialised monitoring for LLMs, whereas Neptune.ai helps observe experiments and efficiency.
A. Model management for LLMs can use instruments like DVC (Knowledge Model Management) to handle information and fashions in Git repositories. The Hugging Face Mannequin Hub is an alternative choice, permitting straightforward mannequin sharing and model monitoring, particularly for transformer fashions.
A. Future traits in LLM Ops might embody enhancements in immediate monitoring to spice up mannequin interpretability. There’ll doubtless be extra environment friendly inference strategies to scale back prices and latency. Moreover, larger automation in mannequin deployment and administration processes is anticipated. These improvements will assist streamline using LLMs in numerous functions.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.
Interdisciplinary Machine Studying Fanatic searching for alternatives to work on state-of-the-art machine studying issues to assist automate and ease the mundane actions of life and captivated with weaving tales via information