{kind=link}

We’re updating this weblog to point out builders easy methods to leverage the most recent options of Databricks and the developments in Spark.
Most knowledge warehouse builders are very aware of the ever-present star schema. Launched by Ralph Kimball within the Nineteen Nineties, a star schema is used to denormalize enterprise knowledge into dimensions (like time and product) and info (like transactions in quantities and portions). A star schema effectively shops knowledge, maintains historical past and updates knowledge by decreasing the duplication of repetitive enterprise definitions, making it quick to combination and filter.
The frequent implementation of a star schema to help enterprise intelligence purposes has change into so routine and profitable that many knowledge modelers can virtually do them of their sleep. At Databricks, we’ve got produced so many knowledge purposes and are continually on the lookout for finest observe approaches to function a rule of thumb, a primary implementation that’s assured to steer us to an incredible final result.
Similar to in a standard knowledge warehouse, there are some easy guidelines of thumb to comply with on Delta Lake that may considerably enhance your Delta star schema joins.
Listed below are the essential steps to success:
- Use Delta Tables to create your reality and dimension tables
- Use Liquid Clustering to supply the most effective file dimension
- Use Liquid Clustering in your reality tables
- Use Liquid Clustering in your bigger dimension desk’s keys and sure predicates
- Leverage Predictive Optimization to keep up tables and collect statistics
1. Use Delta Tables to create your reality and dimension tables
Delta Lake is an open storage format layer that gives the convenience of inserts, updates, deletes, and provides ACID transactions in your knowledge lake tables, simplifying upkeep and revisions. Delta Lake additionally supplies the flexibility to carry out dynamic file pruning to optimize for sooner SQL queries.
The syntax is straightforward on Databricks Runtimes 8.x and newer (the present Lengthy Time period Help runtime is now 15.4) the place Delta Lake is the default desk format. You may create a Delta desk utilizing SQL with the next:
CREATE TABLE MY_TABLE (COLUMN_NAME STRING) CLUSTER BY (COLUMN_NAME);
Earlier than the 8.x runtime, Databricks required creating the desk with the USING DELTA syntax.
CREATE TABLE MY_TABLE (COLUMN_NAME STRING)Earlier than the 8.x runtime, Databricks required creating the desk with the USING DELTA syntax.
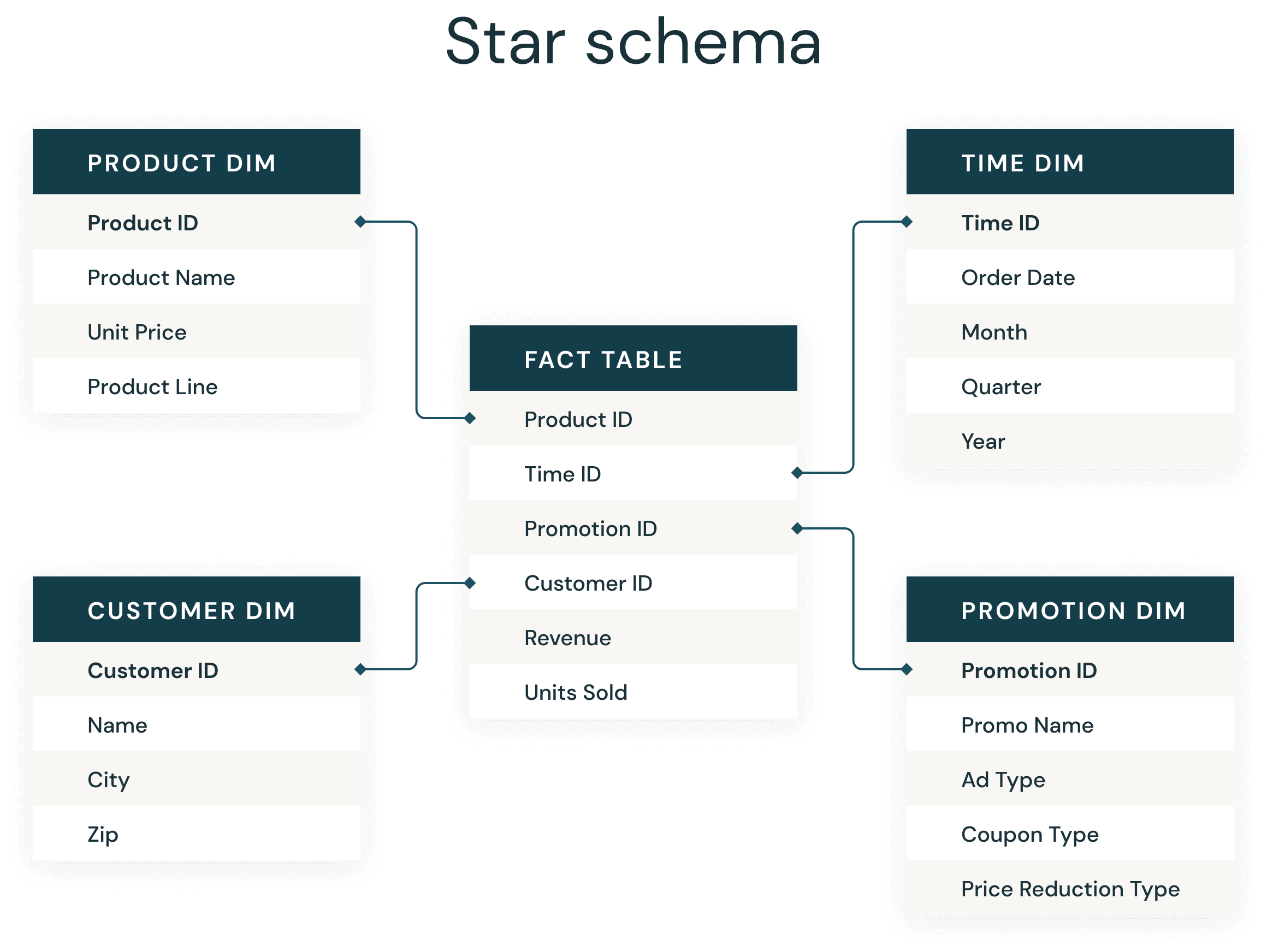
2. Use Liquid Clustering to supply the most effective file dimension
Two of the largest time sinks in an Apache Spark™ question are the time spent studying knowledge from cloud storage and the necessity to learn all underlying recordsdata. With knowledge skipping on Delta Lake, queries can selectively learn solely the Delta recordsdata containing related knowledge, saving important time. Knowledge skipping may help with static file pruning, dynamic file pruning, static partition pruning and dynamic partition pruning.
Earlier than Liquid Clustering, this was a guide setting. There have been guidelines of thumb to ensure that the recordsdata had been appropriately sized and environment friendly for querying. Now with Liquid Clustering, the file sizes are robotically decided and maintained with the optimization routines.
Should you occur to be studying this text (or have learn the earlier model) and you’ve got already created tables with ZORDER, you will want to recreate the tables with the Liquid Clustering.
As well as, Liquid clustering optimizes to stop recordsdata which can be too small, or too massive (skew and stability) and updates the file sizes as new knowledge is appended to maintain your tables optimized.
3. Use Liquid Clustering in your reality tables
To enhance question pace, Delta Lake helps the flexibility to optimize the structure of information saved in cloud storage with Liquid Clustering. Cluster by the columns you’ll use in comparable conditions as clustered indexes within the database world, although they aren’t really an auxiliary construction. A liquid clustered desk will cluster the information within the CLUSTER BY definition in order that rows like column values from the CLUSTER BY definition are collocated within the optimum set of recordsdata.
Most database methods launched indexing as a approach to enhance question efficiency. Indexes are recordsdata, and thus as the information grows in dimension, they will change into one other large knowledge drawback to resolve. As a substitute, Delta Lake orders the information within the Parquet recordsdata to make vary choice on object storage extra environment friendly. Mixed with the stats assortment course of and knowledge skipping, liquid clustered tables are just like search vs. scan operations in databases, which indexes solved, with out creating one other compute bottleneck to search out the information a question is on the lookout for.
For Liquid Clustered tables, the most effective observe is to restrict the variety of columns within the CLUSTER BY clause to the most effective 1-4. We selected the international keys (international keys by use, not really enforced international keys) of the three largest dimensions which had been too massive to broadcast to the employees.
Lastly, Liquid clustering replaces the necessity for each ZORDER and Partitioning, so if you happen to use liquid clustering, you not must, or can, explicitly hive partition the tables.
4. Use Liquid Clustering in your bigger dimension’s keys and sure predicates
Since you’re studying this weblog, you probably have dimensions and a surrogate key or a main key exists in your dimension tables. A key that could be a large integer and is validated and anticipated to be distinctive. After databricks runtime 10.4, Id columns had been typically accessible and are a part of the CREATE TABLE syntax.
Databricks additionally launched unenforced Major Keys and International Keys in Runtime 11.3 and are seen in Unity Catalog enabled clusters and workspaces.
One of many dimensions we had been working with had over 1 billion rows and benefitted from the file skipping and dynamic file pruning after including our predicates into the clustered tables. Our smaller dimensions had been clustered on the dimension key area and had been broadcasted within the be a part of to the info. Much like the recommendation on reality tables, restrict the variety of columns within the Cluster By to the 1-4 fields within the dimension which can be almost certainly to be included in a filter along with the important thing.
Along with the file skipping and ease of upkeep, liquid clustering permits you to add extra columns than ZORDER and is extra versatile than hive fashion partitioning.
5. Analyze Desk to assemble statistics for Adaptive Question Execution Optimizer and allow Predictive Optimization
One of many main developments in Apache Spark™ 3.0 was the Adaptive Question Execution, or AQE for brief. As of Spark 3.0, there are three main options in AQE, together with coalescing post-shuffle partitions, changing sort-merge be a part of to broadcast be a part of, and skew be a part of optimization. Collectively, these options allow the accelerated efficiency of dimensional fashions in Spark.
To ensure that AQE to know which plan to decide on for you, we have to accumulate statistics concerning the tables. You do that by issuing the ANALYZE TABLE command. Prospects have reported that amassing desk statistics has considerably lowered question execution for dimensional fashions, together with advanced joins.
ANALYZE TABLE MY_BIG_DIM COMPUTE STATISTICS FOR ALL COLUMNS
You may nonetheless leverage the Analyze desk as a part of your load routines, however now it’s higher to easily allow Predictive Optimization in your Account, Catalog and Schema.
ALTER CATALOG [catalog_name] DISABLE PREDICTIVE OPTIMIZATION;
ALTER DATABASE schema_name DISABLE PREDICTIVE OPTIMIZATION;
Predictive optimization removes the necessity to manually handle upkeep operations for Unity Catalog managed tables on Databricks.
With predictive optimization enabled, Databricks robotically identifies tables that will profit from upkeep operations and runs them for the person. Upkeep operations are solely run as crucial, eliminating pointless runs for upkeep operations and the burden related to monitoring and troubleshooting efficiency.
At the moment Predictive Optimizations carry out Vacuum and Optimize on tables. Look ahead to updates for Predictive Optimization and keep tuned for when the function incorporates the analyze desk and collect stats along with robotically making use of liquid clustered keys.
Conclusion
By following the above pointers, organizations can cut back question instances – in our instance, we improved question efficiency by 9 instances on the identical cluster. The optimizations tremendously lowered the I/O and ensured that we solely processed the required knowledge. We additionally benefited from the versatile construction of Delta Lake in that it might each scale and deal with the kinds of queries that might be despatched advert hoc from the Enterprise Intelligence instruments.
For the reason that first model of this weblog, Photon is now on by default for our Databricks SQL Warehouse, and is out there on All Function and Jobs clusters. Be taught extra about Photon and the efficiency enhance it can present to all your Spark SQL queries with Databricks.
Prospects can count on their ETL/ELT and SQL question efficiency to enhance by enabling Photon within the Databricks Runtime. Combining the most effective practices outlined right here, with the Photon-enabled Databricks Runtime, you possibly can count on to realize low latency question efficiency that may outperform the most effective cloud knowledge warehouses.
Construct your star schema database with Databricks SQL right this moment.