{kind=link}

Setting up Data Graphs (KGs) from unstructured information is a posh job because of the difficulties of extracting and structuring significant info from uncooked textual content. Unstructured information usually accommodates unresolved or duplicated entities and inconsistent relationships, which complicates its transformation right into a coherent information graph. Moreover, the huge quantity of unstructured information obtainable throughout numerous fields additional emphasizes the necessity for scalable strategies to mechanically course of, extract, and construction this information into KGs. Efficiently addressing these challenges is essential for enabling environment friendly reasoning, inference, and data-driven decision-making in fields starting from scientific analysis to internet information evaluation.
Conventional strategies for constructing KGs from unstructured textual content primarily depend on strategies corresponding to named entity recognition, relation extraction, and entity decision. These approaches are continuously constrained by the necessity for predefined entity sorts and relationships, usually relying on domain-specific ontologies. Moreover, they sometimes contain supervised studying, which requires massive quantities of annotated information. A big limitation of those strategies is their tendency to generate inconsistent graphs with duplicated or unresolved entities, leading to redundancies and ambiguities that necessitate intensive post-processing. Moreover, many present options are topic-dependent, limiting their applicability throughout totally different domains, which restricts their scalability and adaptableness to new use circumstances.
Researchers from INSA Lyon, CNRS, and Universite Claude Bernard Lyon 1 introduce iText2KG, a zero-shot, topic-independent methodology for incrementally developing Data Graphs (KGs) from unstructured information with out the necessity for predefined ontologies or post-processing. This framework consists of 4 distinct modules:
- Doc Distiller: Reforms uncooked paperwork into semantic blocks utilizing massive language fashions (LLMs) guided by a versatile, user-defined schema.
- Incremental Entity Extractor: Extracts distinctive entities from the semantic blocks, guaranteeing no duplications or semantic ambiguities.
- Incremental Relation Extractor: Identifies and extracts semantically distinctive relationships between entities.
- Graph Integrator: Visualizes the entities and relationships in a KG utilizing Neo4j, permitting for structured illustration of knowledge.
This modular design separates entity and relation extraction duties, resulting in improved precision and consistency. Furthermore, the usage of a zero-shot studying paradigm ensures adaptability throughout numerous domains with out the necessity for fine-tuning or retraining, making it a versatile, correct, and scalable resolution for KG development.
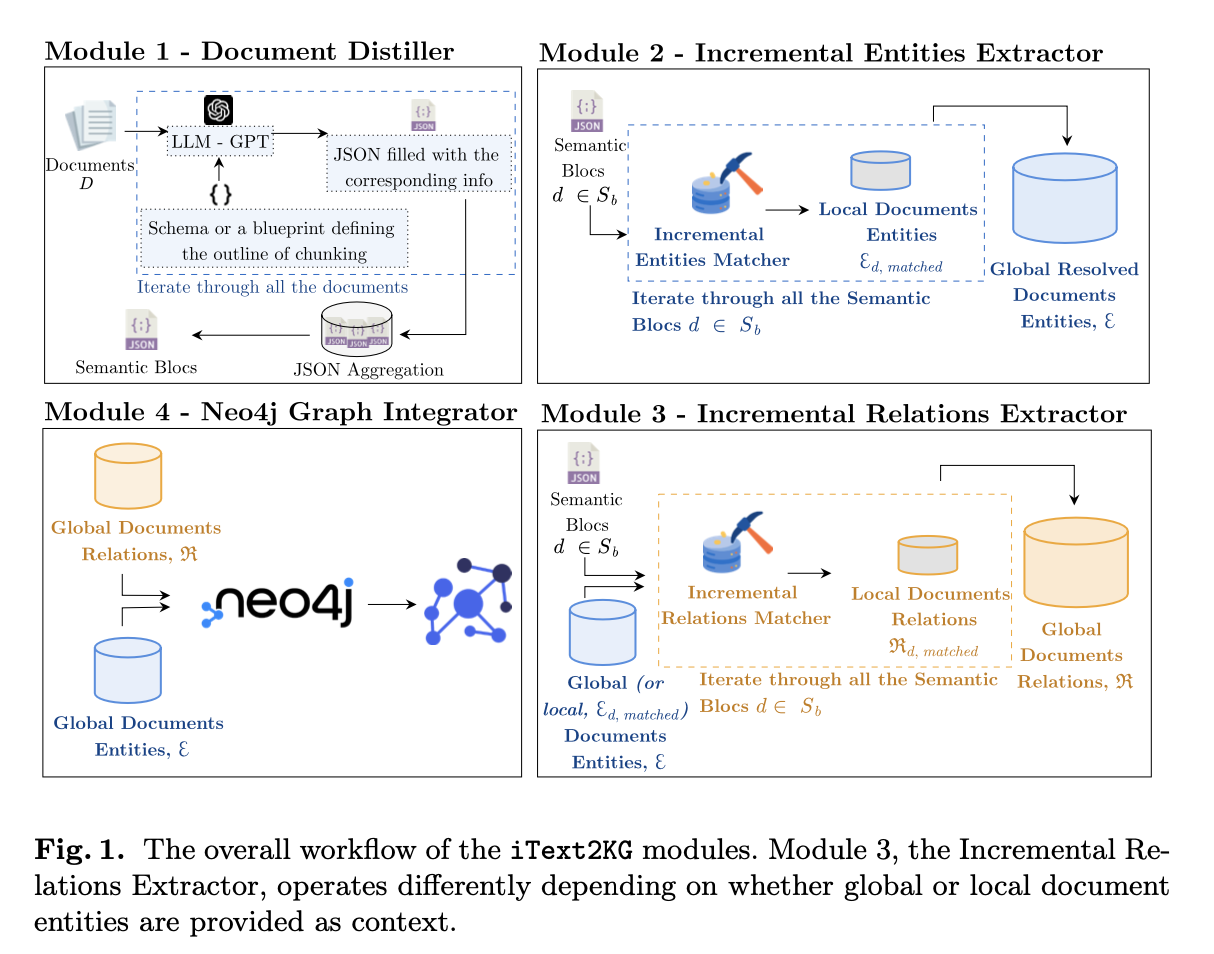
iText2KG processes paperwork incrementally by passing them by means of its 4 core modules. First, the Doc Distiller module restructures uncooked textual content into semantic blocks based mostly on a versatile, user-defined schema, which might be tailored to several types of paperwork corresponding to scientific papers, CVs, or web sites. These semantic blocks are then fed into the Incremental Entity Extractor, which identifies and ensures that every entity is exclusive by resolving potential ambiguities utilizing similarity measures like cosine similarity.
The Incremental Relation Extractor then extracts relationships between the recognized entities, leveraging each native and world doc contexts to make sure the accuracy of the relationships. Lastly, the Graph Integrator consolidates these entities and relationships into a visible information graph utilizing Neo4j, offering a coherent and structured illustration of the info. The system’s efficiency was examined on a wide range of doc sorts, demonstrating its versatility throughout totally different use circumstances with out the necessity for retraining.
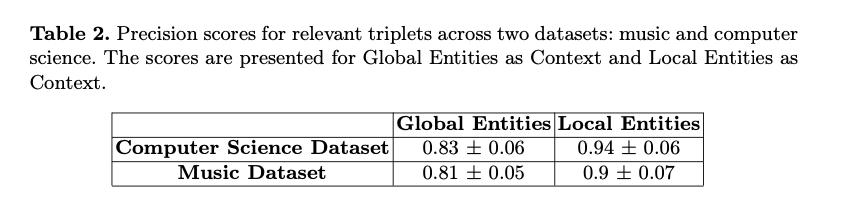
iText2KG exhibited superior efficiency in comparison with baseline strategies, notably in schema consistency, triplet extraction precision, and entity/relation decision. The system achieved excessive consistency in structuring info from numerous varieties of paperwork, corresponding to scientific articles, web sites, and CVs. Precision in extracting related relationships was notably excessive when utilizing native entities, guaranteeing minimal errors within the information graph. Moreover, the method demonstrated a low false discovery fee in entity and relation decision, notably with structured paperwork like scientific papers. General, iText2KG proved to be efficient in developing correct and constant information graphs throughout a number of domains, adapting to totally different information sorts with out the necessity for intensive fine-tuning or post-processing.

In conclusion, iText2KG gives a major development in KG development by offering a versatile, zero-shot method able to structuring unstructured information into constant, topic-independent information graphs. By modularizing the duties of entity and relation extraction and adopting an incremental course of, the strategy overcomes key limitations of conventional approaches, corresponding to reliance on predefined ontologies and intensive post-processing. With robust efficiency throughout a wide range of doc sorts, iText2KG exhibits immense potential for broad software in fields requiring structured information from unstructured textual content, providing a dependable, scalable, and environment friendly resolution for KG development.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s enthusiastic about information science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.