

Pure Language processing makes use of massive language fashions (LLMs) to allow functions similar to language translation, sentiment evaluation, speech recognition, and textual content summarization. These fashions depend upon human feedback-based supervised knowledge, however counting on unsupervised knowledge turns into essential as they surpass human capabilities. Nevertheless, the problem of alignment arises because the fashions get extra complicated and nuanced. Researchers at Carnegie Mellon College, Peking College, MIT-IBM Watson AI Lab, College of Cambridge, Max Planck Institute for Clever Techniques, and UMass Amherst have developed the Simple-to-Onerous Generalization (E2H) methodology that tackles the issue of alignment in complicated duties with out counting on human suggestions.
Conventional alignment strategies rely closely on supervised fine-tuning and Reinforcement Studying from Human Suggestions (RLHF). This reliance on human capabilities serves as a hindrance when scaling these techniques, as amassing high-quality human suggestions is labor-intensive and dear. Moreover, the generalization of those fashions to situations past realized behaviors is difficult. Due to this fact, there’s an pressing want for a strategy that may accomplish complicated duties with out requiring exhaustive human supervision.
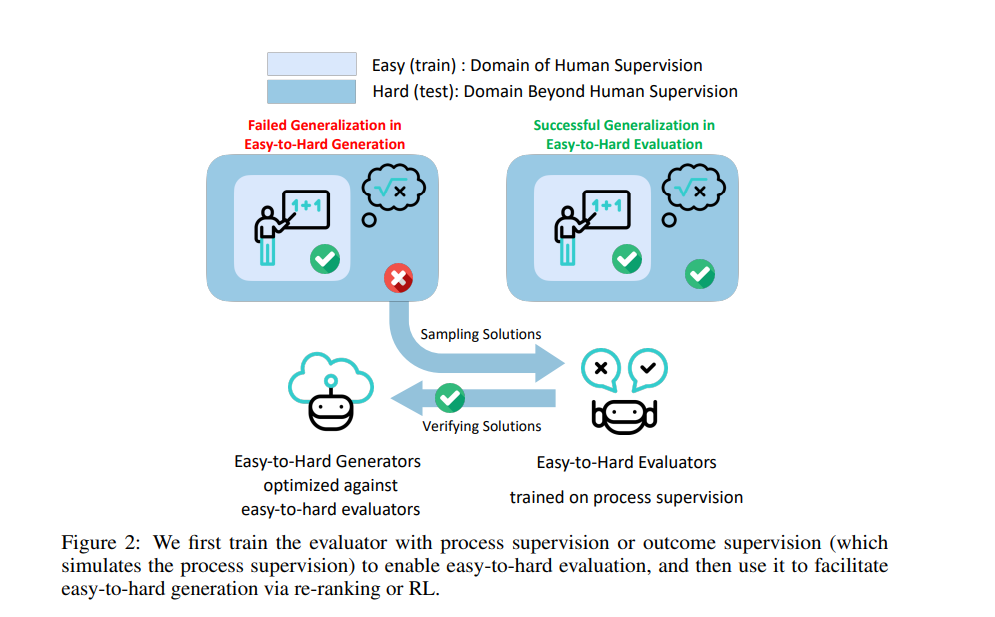
The proposed resolution, Simple-to-Onerous Generalization, employs a three-step methodology to attain scalable activity generalization:
- Course of-Supervised Reward Fashions (PRMs): The fashions are educated on easy human-level duties. These educated fashions then consider and information the problem-solving functionality of AI on higher-level complicated duties.
- Simple-to-Onerous Generalization: The fashions are steadily uncovered to extra complicated duties as they practice. Predictions and evaluations from the simpler duties are used to information studying on more durable ones.
- Iterative Refinement: The fashions are adjusted based mostly on the suggestions offered by the PRMs.
This studying course of with iterative refinement permits AI to shift from human-feedback-dependent fashions to diminished human annotations. Generalization of duties that deviate from the realized conduct is smoother. Thus, this methodology optimizes AI’s efficiency in conditions the place human engagement turns into obscure.
Efficiency comparability reveals vital enhancements on the MATH500 benchmark, a 7b process-supervised RL mannequin achieved 34.0% accuracy, whereas a 34b mannequin reached 52.5% accuracy, utilizing solely human supervision on straightforward issues. The tactic demonstrated effectiveness on the APPS coding benchmark as effectively. These outcomes recommend comparable or superior alignment outcomes to RLHF whereas considerably lowering the necessity for human-labeled knowledge on complicated duties.
This analysis addresses the essential problem of AI alignment past human supervision by introducing an modern, easy-to-hard generalization framework. The proposed methodology demonstrates promising leads to enabling AI techniques to deal with more and more complicated duties whereas aligning with human values. Notable strengths embody its novel method to scalable alignment, effectiveness throughout domains similar to arithmetic and coding, and potential to deal with limitations of present alignment strategies. Nevertheless, additional validation in various, real-world situations is critical. Total, this work marks a big step towards growing AI techniques that may safely and successfully function with out direct human supervision, paving the way in which for extra superior and aligned AI applied sciences.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 60k+ ML SubReddit.

Afeerah Naseem is a consulting intern at Marktechpost. She is pursuing her B.tech from the Indian Institute of Expertise(IIT), Kharagpur. She is obsessed with Knowledge Science and fascinated by the function of synthetic intelligence in fixing real-world issues. She loves discovering new applied sciences and exploring how they will make on a regular basis duties simpler and extra environment friendly.