{kind=link}

Omni-modality language fashions (OLMs) are a quickly advancing space of AI that permits understanding and reasoning throughout a number of knowledge varieties, together with textual content, audio, video, and pictures. These fashions goal to simulate human-like comprehension by processing various inputs concurrently, making them extremely helpful in advanced, real-world purposes. The analysis on this discipline seeks to create AI programs that may seamlessly combine these different knowledge varieties and generate correct responses throughout completely different duties. This represents a leap ahead in how AI programs work together with the world, making them extra aligned with human communication, the place info is never confined to at least one modality.
A persistent problem in growing OLMs is their inconsistent efficiency when confronted with multimodal inputs. For instance, a mannequin might have to investigate knowledge that features textual content, pictures, and audio to finish a activity in real-world conditions. Nevertheless, many present fashions need assistance when successfully combining these inputs. The primary problem lies within the incapability of those programs to completely purpose throughout modalities, resulting in discrepancies of their outputs. In lots of cases, fashions produce completely different responses when introduced with the identical info in varied codecs, equivalent to a math downside displayed as a picture versus spoken out loud as audio.
Present benchmarks for OLMs are sometimes restricted to easy combos of two modalities, equivalent to textual content and pictures or video and textual content. These assessments should consider the complete vary of capabilities required for real-world purposes, usually involving extra advanced eventualities. For instance, many present fashions carry out properly when dealing with dual-modality duties. Nonetheless, they have to enhance considerably when requested to purpose throughout combos of three or extra modalities, equivalent to integrating video, textual content, and audio to derive an answer. This limitation creates a niche in assessing how properly these fashions really perceive and purpose throughout a number of knowledge varieties.
Researchers from Google DeepMind, Google, and the College of Maryland developed Omni×R, a brand new analysis framework designed to check the reasoning capabilities of OLMs rigorously. This framework stands aside by introducing extra advanced multimodal challenges. Omni×R evaluates fashions utilizing eventualities the place they have to combine a number of types of knowledge, equivalent to answering questions that require reasoning throughout textual content, pictures, and audio concurrently. The framework contains two datasets:
- Omni×Rsynth is an artificial dataset created by robotically changing textual content into different modalities.
- Omni×Rreal is a real-world dataset fastidiously curated from sources like YouTube.
These datasets present a extra complete and difficult check atmosphere than earlier benchmarks.
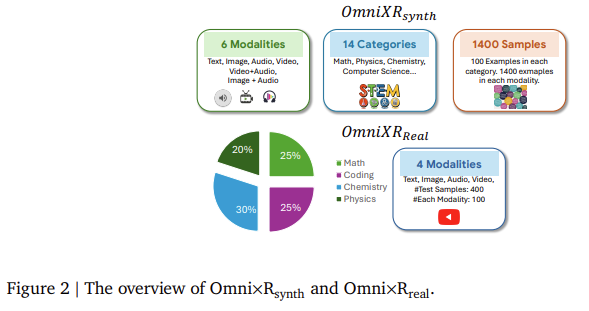
Omni×Rsynth, the artificial element of the framework, is designed to push fashions to their limits by changing textual content into pictures, video, and audio. As an example, the analysis group developed Omnify!, a device to translate textual content into a number of modalities, making a dataset of 1,400 samples unfold throughout six classes, together with math, physics, chemistry, and pc science. Every class contains 100 examples for the six modalities, textual content, picture, video, audio, video+audio, and picture+audio, difficult fashions to deal with advanced enter combos. The researchers used this dataset to check varied OLMs, together with Gemini 1.5 Professional and GPT-4o. Outcomes from these exams revealed that present fashions expertise vital efficiency drops when requested to combine info from completely different modalities.
Omni×Rreal, the real-world dataset, contains 100 movies protecting subjects like math and science, the place the questions are introduced in numerous modalities. For instance, a video could present a math downside visually whereas the reply decisions are spoken aloud, requiring the mannequin to combine visible and auditory info to resolve the issue. The actual-world eventualities additional highlighted the fashions’ difficulties in reasoning throughout modalities, because the outcomes confirmed inconsistencies just like these noticed within the artificial dataset. Notably, fashions that carried out properly with textual content enter skilled a pointy decline in accuracy when tasked with video or audio inputs.

The analysis group carried out intensive experiments and located a number of key insights. As an example, the Gemini 1.5 Professional mannequin carried out properly throughout most modalities, with a textual content reasoning accuracy of 77.5%. Nevertheless, its efficiency dropped to 57.3% on video and 36.3% on picture inputs. In distinction, GPT-4o demonstrated higher ends in dealing with textual content and picture duties however struggled with video, displaying a 20% efficiency drop when tasked with integrating textual content and video knowledge. These underscore the challenges of reaching constant efficiency throughout a number of modalities, an important step towards advancing OLM capabilities.
The outcomes of the Omni×R benchmark revealed a number of notable tendencies throughout completely different OLMs. One of the crucial crucial observations was that even essentially the most superior fashions, equivalent to Gemini and GPT-4o, considerably different their reasoning talents throughout modalities. For instance, the Gemini mannequin achieved 65% accuracy when processing audio, however its efficiency dropped to 25.9% when combining video and audio knowledge. Equally, the GPT-4o-mini mannequin, regardless of excelling in text-based duties, struggled with video, displaying a 41% efficiency hole in comparison with text-based duties. These discrepancies spotlight the necessity for additional analysis and growth to bridge the hole in cross-modal reasoning capabilities.
The findings from the Omni×R benchmark level to a number of key takeaways that underline the present limitations and future instructions for OLM analysis:
- Fashions like Gemini and GPT-4o carry out properly with textual content however battle with multimodal reasoning.
- A big efficiency hole exists between dealing with text-based inputs and complicated multimodal duties, particularly when video or audio is concerned.
- Bigger fashions usually carry out higher throughout modalities, however smaller fashions can typically outperform them in particular duties, displaying a trade-off between mannequin measurement and suppleness.
- The artificial dataset (Omni×Rsynth) precisely simulates real-world challenges, making it a worthwhile device for future mannequin growth.

In conclusion, the Omni×R framework launched by the analysis group provides a crucial step ahead in evaluating and enhancing the reasoning capabilities of OLMs. By rigorously testing fashions throughout various modalities, the research revealed vital challenges that should be addressed to develop AI programs able to human-like multimodal reasoning. The efficiency drops seen in duties involving video and audio integration spotlight the complexities of cross-modal reasoning and level to the necessity for extra superior coaching strategies and fashions to deal with real-world, multimodal knowledge complexities.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Effective-Tuned Fashions: Predibase Inference Engine (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.