{kind=link}

FineWeb2 considerably advances multilingual pretraining datasets, masking over 1000 languages with high-quality information. The dataset makes use of roughly 8 terabytes of compressed textual content information and incorporates practically 3 trillion phrases, sourced from 96 CommonCrawl snapshots between 2013 and 2024. Processed utilizing the datatrove library, FineWeb2 demonstrates superior efficiency in comparison with established datasets like CC-100, mC4, CulturaX, and HPLT throughout 9 various languages. The ablation and analysis setup is current on this github repo.
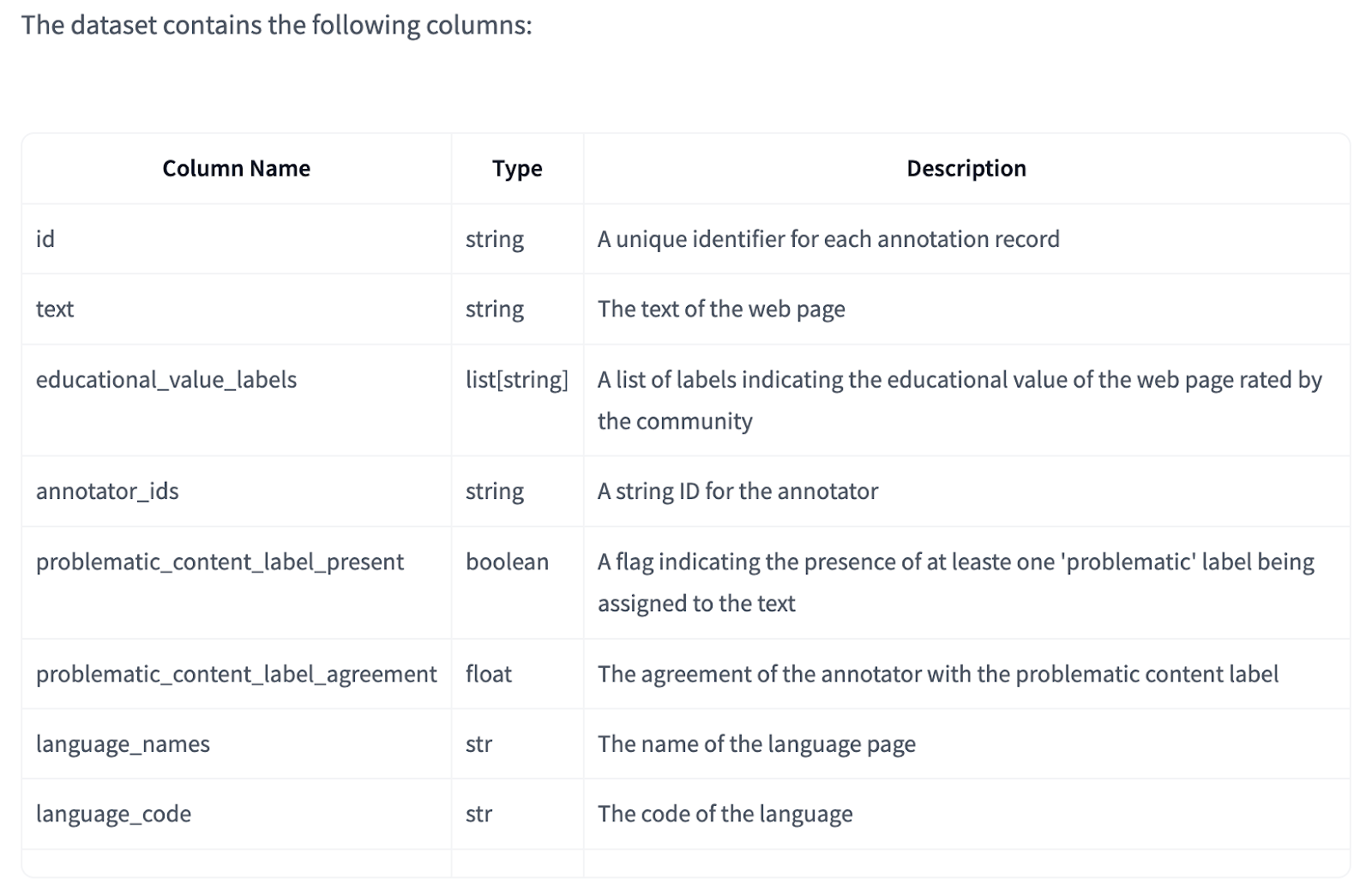
Huggingface neighborhood researchers launched FineWeb-C, a collaborative, community-driven mission that expands upon FineWeb2 to create high-quality instructional content material annotations throughout a whole lot of languages. The mission permits neighborhood members to fee internet content material’s instructional worth and establish problematic components via the Argilla platform. Languages attaining 1,000 annotations qualify for dataset inclusion. This annotation course of serves twin functions: figuring out high-quality instructional content material and bettering LLM improvement throughout all languages.

318 Hugging Face neighborhood members have submitted 32,863 annotations, contributing to growing high-quality LLMs throughout underrepresented languages. FineWeb-Edu is a dataset constructed upon the unique FineWeb dataset and employs an academic high quality classifier skilled on LLama3-70B-Instruct annotations to establish and retain probably the most instructional content material. This method has confirmed profitable, outperforming FineWeb on well-liked benchmarks whereas decreasing the information quantity wanted for coaching efficient LLMs. The mission goals to increase FineWeb-Edu’s capabilities to all world languages by gathering neighborhood annotations to coach language-specific instructional high quality classifiers.
The mission prioritizes human-generated annotations over LLM-based ones, significantly for low-resource languages the place LLM efficiency can’t be reliably validated. This community-driven method parallels Wikipedia’s collaborative mannequin, emphasizing open entry and democratization of AI know-how. Contributors be a part of a broader motion to interrupt language obstacles in AI improvement, as industrial firms sometimes concentrate on worthwhile languages. The dataset’s open nature permits anybody to construct AI techniques tailor-made to particular neighborhood wants whereas facilitating studying about efficient approaches throughout completely different languages.
The FineWeb-Edu makes use of a number of annotations per web page for some languages, permitting versatile calculation of annotator settlement. High quality management measures embody plans to extend annotation overlap in closely annotated languages. The information incorporates a boolean column ‘problematic_content_label_present’ to establish pages with problematic content material flags, typically ensuing from incorrect language detection. Customers can filter content material based mostly on both particular person problematic labels or annotator settlement via the ‘problematic_content_label_agreement’ column. The dataset operates beneath the ODC-By v1.0 license and CommonCrawl’s Phrases of Use.
In conclusion, FineWeb2’s community-driven extension, FineWeb-C, has gathered 32,863 annotations from 318 contributors, specializing in instructional content material labeling. The mission demonstrates superior efficiency in comparison with current datasets with much less coaching information via FineWeb-Edu’s specialised instructional content material classifier. Not like industrial approaches, this open-source initiative prioritizes human annotations over LLM-based ones, significantly for low-resource languages. The dataset options strong high quality management measures, together with a number of annotation layers and problematic content material filtering, whereas working beneath the ODC-By v1.0 license.
Take a look at the particulars. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a concentrate on understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.