{kind=link}

Machine Studying ML affords important potential for accelerating the answer of partial differential equations (PDEs), a crucial space in computational physics. The purpose is to generate correct PDE options quicker than conventional numerical strategies. Whereas ML reveals promise, considerations about reproducibility in ML-based science are rising. Points like knowledge leakage, weak baselines, and inadequate validation undermine efficiency claims in lots of fields, together with medical ML. Regardless of these challenges, curiosity in utilizing ML to enhance or exchange standard PDE solvers continues, with potential advantages for optimization, inverse issues, and decreasing computational time in varied functions.
Princeton College researchers reviewed the machine studying ML literature for fixing fluid-related PDEs and located overoptimistic claims. Their evaluation revealed that 79% of research in contrast ML fashions with weak baselines, resulting in exaggerated efficiency outcomes. Moreover, widespread reporting biases, together with end result and publication biases, additional skewed findings by under-reporting unfavourable outcomes. Though ML-based PDE solvers, reminiscent of physics-informed neural networks (PINNs), have proven potential, they typically fail concerning velocity, accuracy, and stability. The examine concludes that the present scientific literature doesn’t present a dependable analysis of ML’s success in PDE fixing.
Machine-learning-based solvers for PDEs typically examine their efficiency in opposition to commonplace numerical strategies, however many comparisons endure from weak baselines, resulting in exaggerated claims. Two main pitfalls embody evaluating strategies with completely different accuracy ranges and utilizing much less environment friendly numerical strategies as baselines. In a evaluation of 82 articles on ML for PDE fixing, 79% in contrast weak baselines. Moreover, reporting biases had been prevalent, with optimistic outcomes typically highlighted whereas unfavourable outcomes had been under-reported or hid. These biases contribute to an excessively optimistic view of the effectiveness of ML-based PDE solvers.
The evaluation employs a scientific evaluation methodology to analyze the frequency with which the ML literature in PDE fixing compares its efficiency in opposition to weak baselines. The examine particularly focuses on articles using ML to derive approximate options for varied fluid-related PDEs, together with Navier–Stokes and Burgers’ equations. Inclusion standards emphasize the need of quantitative velocity or computational value comparisons whereas excluding a spread of non-fluid-related PDEs, qualitative comparisons with out supporting proof, and articles missing related baselines. The search course of concerned compiling a complete listing of authors within the discipline and using Google Scholar to establish pertinent publications from 2016 onwards, together with 82 articles that met the outlined standards.
The examine establishes important circumstances to make sure honest comparisons, reminiscent of evaluating ML solvers with environment friendly numerical strategies at equal accuracy or runtime. Suggestions are supplied to boost the reliability of comparisons, together with cautious interpretation of outcomes from specialised ML algorithms versus general-purpose numerical libraries and justification of {hardware} selections utilized in evaluations. The evaluation totally highlights the necessity to consider baselines in ML-for-PDE functions, noting the predominance of neural networks within the chosen articles. Finally, the systematic evaluation seeks to light up current shortcomings within the present literature whereas encouraging future research to undertake extra rigorous comparative methodologies.
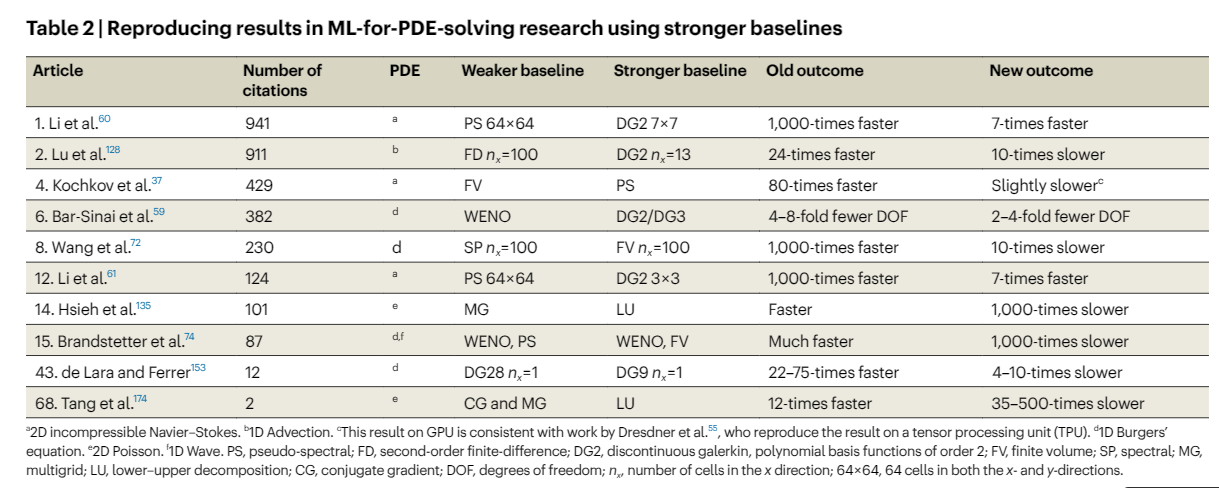
Weak baselines in machine studying for PDE fixing typically stem from a scarcity of ML neighborhood experience, restricted numerical evaluation benchmarking, and inadequate consciousness of the significance of sturdy baselines. To mitigate reproducibility points, it is suggested that ML research examine outcomes in opposition to each commonplace numerical strategies and different ML solvers. Researchers also needs to justify their selection of baselines and comply with established guidelines for honest comparisons. Moreover, addressing biases in reporting and fostering a tradition of transparency and accountability will improve the reliability of ML analysis in PDE functions.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.