{kind=link}

For safety-critical techniques in areas reminiscent of protection and medical gadgets, software program assurance is essential. Analysts can use static evaluation instruments to judge supply code with out operating it, permitting them to determine potential vulnerabilities. Regardless of their usefulness, the present era of heuristic static evaluation instruments require important handbook effort and are vulnerable to producing each false positives (spurious warnings) and false negatives (missed warnings). Latest analysis from the SEI estimates that these instruments can determine as much as one candidate error (“weak spot”) each three strains of code, and engineers typically select to prioritize fixing the commonest and extreme errors.
Nonetheless, much less widespread errors can nonetheless result in essential vulnerabilities. For instance, a “flooding” assault on a network-based service can overwhelm a goal with requests, inflicting the service to crash. Nonetheless, neither of the associated weaknesses (“improper useful resource shutdown or launch” or “allocation of assets with out limits or throttling”) is on the 2023 High 25 Harmful CWEs checklist, the Recognized Exploited Vulnerabilities (KEV) High 10 checklist, or the Cussed High 25 CWE 2019-23 checklist.
In our analysis, giant language fashions (LLMs) present promising preliminary ends in adjudicating static evaluation alerts and offering rationales for the adjudication, providing potentialities for higher vulnerability detection. On this weblog submit, we talk about our preliminary experiments utilizing GPT-4 to judge static evaluation alerts. This submit additionally explores the constraints of utilizing LLMs in static evaluation alert analysis and alternatives for collaborating with us on future work.
What LLMs Provide
Latest analysis signifies that LLMs, reminiscent of GPT-4, could also be a major step ahead in static evaluation adjudication. In one latest research, researchers have been in a position to make use of LLMs to determine greater than 250 sorts of vulnerabilities and cut back these vulnerabilities by 90 p.c. Not like older machine studying (ML) methods, newer fashions can produce detailed explanations for his or her output. Analysts can then confirm the output and related explanations to make sure correct outcomes. As we talk about beneath, GPT-4 has additionally typically proven the power to appropriate its personal errors when prompted to examine its work.
Notably, now we have discovered that LLMs carry out significantly better when given particular directions, reminiscent of asking the mannequin to resolve a selected difficulty on a line of code fairly than prompting an LLM to search out all errors in a codebase. Based mostly on these findings, now we have developed an strategy for utilizing LLMs to adjudicate static evaluation alerts. The preliminary outcomes present an enchancment in productiveness in dealing with the numerous alerts from current static evaluation instruments, although there’ll proceed to be false positives and false negatives.
Our Strategy in Motion
{kind=link}

Determine 1: A mannequin for utilizing an LLM to adjudicate static evaluation alerts
In our strategy, illustrated in Determine 1, an LLM-based instrument ingests supply code and static evaluation alerts. From there, for every alert, the instrument creates a immediate that features the alert from the static analyzer, the supply code of the related perform, and directions on how one can adjudicate the alert. The immediate is supplied as enter to the LLM, which then adjudicates the alert (as true optimistic, false optimistic, or unsure) and gives its remaining reply in a JSON format.
To check this strategy, we requested GPT-4 to adjudicate an alert for vulnerability CVE-2022-41674, an integer overflow that results in a buffer overflow in Linux. Our script added feedback to determine the code places from the alert and gave GPT-4 the next immediate:
I would like you to adjudicate whether or not a static-analysis alert is appropriate or a false alarm. The alert warns of a buffer overflow throughout memcpy on the road ending with “// ALERT-2” that occurs if there may be an integer overflow on the road ending with “// ALERT-1”.
We then included the supply code of the perform we needed GPT-4 to adjudicate. Lastly, our immediate ended with the next textual content:
If you happen to can decide whether or not the alert is appropriate or a false alarm, please point out this willpower and clarify your reasoning, and on the finish of your response, say both {“reply”: “true optimistic”} or {“reply”: “false optimistic”}. First determine whether or not integer overflow can occur. If it could actually’t, then report the alert is fake optimistic. If it could actually occur, then study whether or not it could actually result in a buffer overflow. Be aware: u8 right here denotes an unsigned 8-bit integer kind.
The total immediate and output are out there on-line.
In response, GPT-4 recognized the place and the way an integer overflow might happen:
For an integer overflow to happen, we’d like the sum of
mbssid[1]and2to exceed the bounds of theu8kind (unsigned 8-bit integer).On condition that
u8can symbolize values between 0 and 255, the utmost worthmbssid[1]can have is 255. Nonetheless, ifmbssid[1]was 255, including 2 would certainly trigger an overflow, leading to a worth of 1.Line:
cpy_len = mbssid[1] + 2; // ALERT-1This line may cause an integer overflow if
mbssid[1]is the same as 255.
GPT-4 then defined how an integer overflow can result in a buffer overflow, concluding that the alert is a real optimistic:
If the integer overflow happens,
cpy_lencan be set to 1. The subsequent line of curiosity is:memcpy(pos, mbssid + cpy_len, ((ie + ielen) – (mbssid + cpy_len))); // ALERT-2
The third argument of memcpy is the variety of bytes to repeat. If cpy_len is about to 1 because of an overflow, the worth being copied from will begin 1 byte after mbssid.
The quantity being copied ((ie + ielen) – (mbssid + cpy_len)) would then be nearly the whole thing of the buffer, minus just some bytes.
The vacation spot buffer, pos, is part of new_ie, which has been allotted with a dimension of new_ie_len.
The essential query is: can (ie + ielen) – (mbssid + cpy_len) exceed new_ie_len?
Nonetheless, because of earlier operations, we have adjusted new_ie_len with statements like new_ie_len -= trans_ssid[1] and new_ie_len -= mbssid[1]. Within the case the place mbssid[1] is 255 (and overflows), this may cut back new_ie_len by 255.
The code is attempting to make sure that new_ie_len is all the time appropriately adjusted to symbolize the overall anticipated dimension. But when mbssid[1] overflows, we’re subtracting 255 from new_ie_len after which including nearly the complete size of the buffer again because of the overflow in cpy_len, probably copying extra knowledge into new_ie than it could actually maintain.
Lastly, we prompted GPT-4 with a patched model of the code. The LLM declared that the vulnerability was now not current and returned that the alert was a false optimistic.
LLM Limitations and Mitigations
Restricted Context Window
A big limitation for LLMs is the slender context window. Whereas LLMs can ingest a single perform, they sometimes can not ingest a whole codebase. To make sure the LLM has the required context, prompts must summarize essentially the most related components of a codebase. Methods for offering this context embrace utilizing outputs from conventional static evaluation and utilizing the LLM itself to generate perform summaries.
We’ve got additionally examined extra methods to mitigate the restricted context window. In a single check, we prompted GPT-4 to ask for required info, reminiscent of definitions of referred to as capabilities. We then equipped the perform’s definition, and the LLM correctly adjudicated the alert as a false optimistic.
In one other check, we used the LLM to generate a precondition needed and ample for proving the absence of buffer overflow. We then requested the LLM to examine if the precondition was fulfilled. On this instance, we prompted GPT-4 with a perform referred to as greet_user that takes a string as an argument and requested it to adjudicate an alert a few buffer overflow. GPT-4 decided {that a} buffer overflow might happen if the enter string was too lengthy and returned a precondition for avoiding a buffer overflow. On this case, the string wanted to be lower than or equal to 52 characters in size.
[
{"precond": "strlen(username) <= 52", "is_necessary": "true", "is_sufficient": "true"}
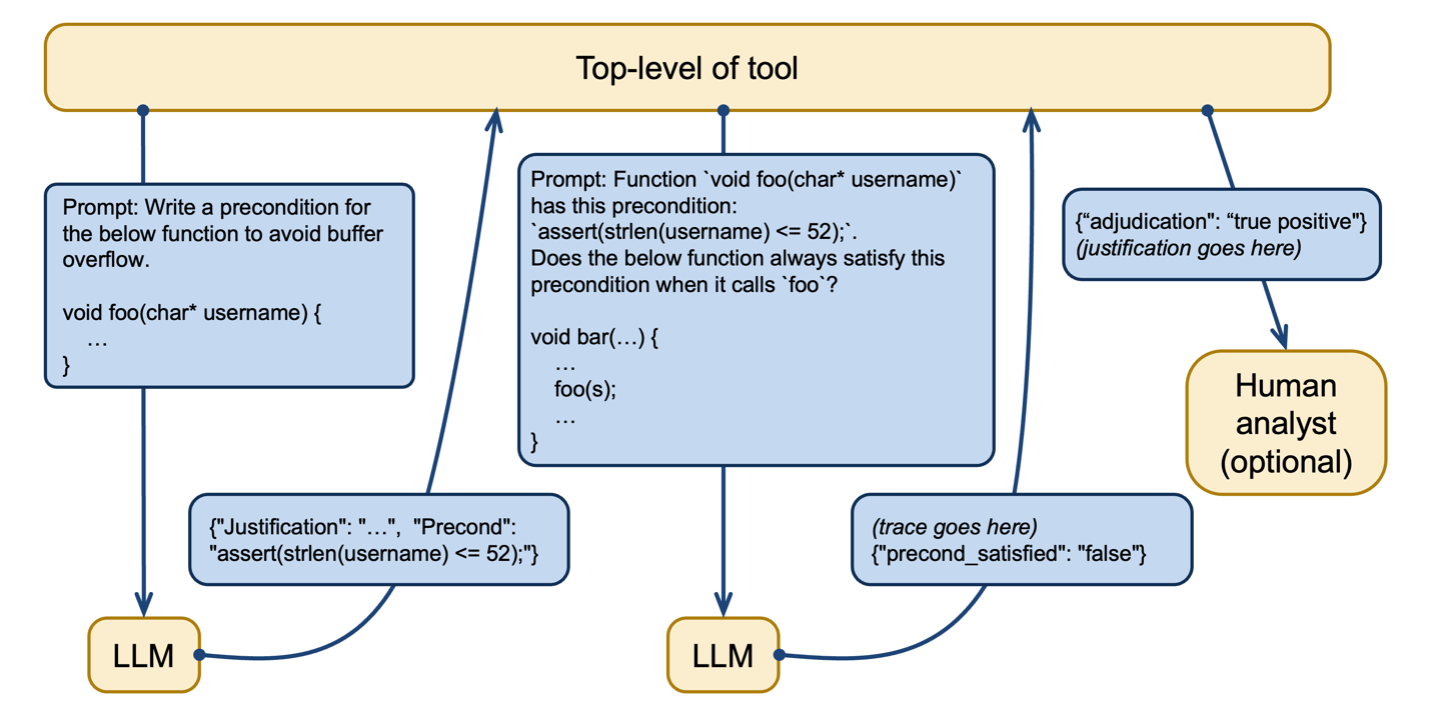
]GPT-4 was then prompted to analyze a perform that calls the greet_user perform to find out if it met the precondition. On this case, the LLM appropriately decided that the perform might violate the precondition. Determine 2 illustrates this course of of making and utilizing preconditions in LLM prompts. As an additional examine, a human analyst can consider the LLM’s output to evaluate accuracy.
{kind=link}
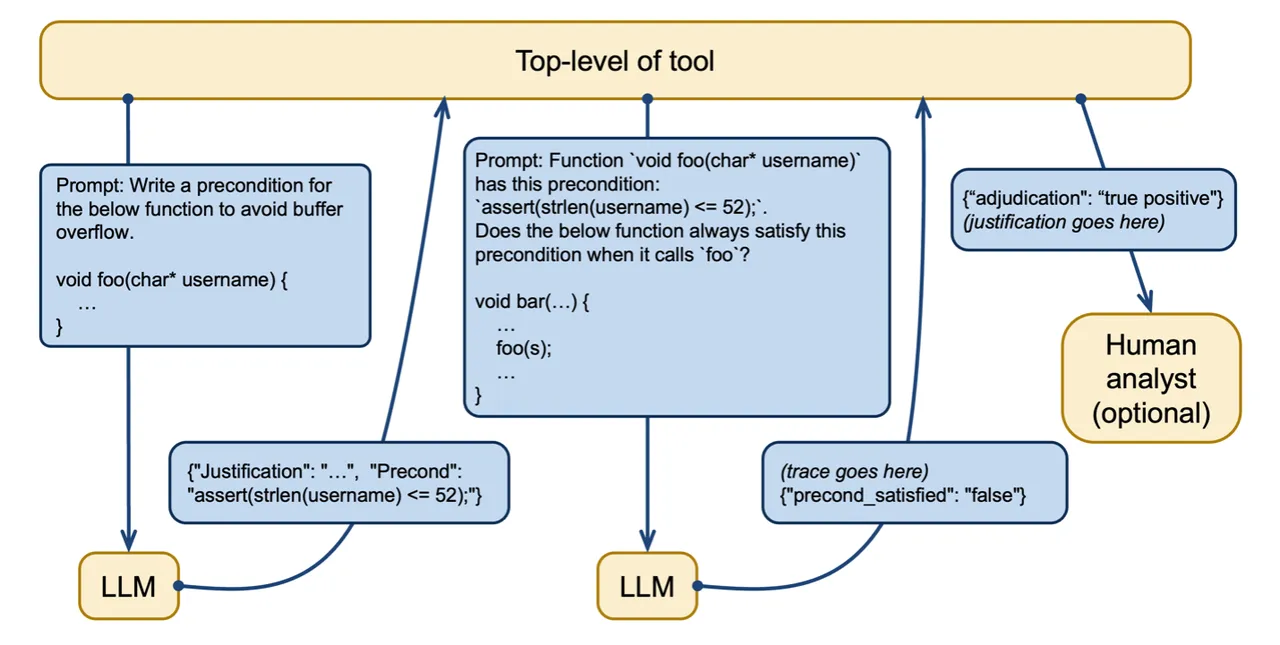
Determine 2: Creating and utilizing preconditions to mitigate a restricted context window
Mitigating LLM Errors
One other barrier is the well-known tendency of LLMs to generally make errors. In our analysis, we discovered that one usually efficient mitigation technique is to ask the LLM to double-check its work. In one experiment, GPT-4 incorrectly recognized a use-after-free vulnerability. We then requested GPT-4 to examine its work with this immediate:
OK, now please double-check that the hint is appropriate, stepping through the code intimately.
The LLM responded with a walkthrough of the code after which appropriately concluded that there was no vulnerability current:
Upon an in depth step-by-step walkthrough, the hint supplied beforehand seems to be incorrect. The use-after-free state of affairs would not happen as a result of when an merchandise from full_list is copied to sub_list utilizing the ‘C’ command, a replica of the string is created with strdup(), guaranteeing that sub_list entries are unbiased of any reallocations or frees that may happen with full_list entries.
Subsequently, there is no such thing as a use-after-free vulnerability with the described hint within the supplied code.
Deleting the strdup name within the above instance introduces an actual use-after-free bug. We eliminated this name to strdup and individually (i.e., in a brand new dialog) requested GPT-4 to research this model of the code. GPT-4 appropriately recognized the use-after-free bug and appropriately reported that it’s a actual bug when requested to double-check the hint intimately.
Utilizing an LLM to Write Proof Annotations
We additionally used an identical approach when asking the LLM to confirm a proof. Some instruments reminiscent of Frama-C can confirm hand-written proofs of sure properties of packages. Since writing these proofs will be time-consuming and sometimes requires particular experience, we needed to check the accuracy of GPT-4 performing this perform and probably dashing up the verification course of.
We requested GPT-4 to write down a precondition and confirm that no buffer overflow is current within the following perform when the precondition is happy:
int rand_val_of_array(int* arr, int n) {
int i = random() % n;
return arr[i];
}Initially, the LLM produced an invalid precondition. Nonetheless, once we prompted GPT-4 with the error message from Frama-C, we acquired an accurate precondition together with an in depth clarification of the error. Whereas GPT-4 doesn’t but have the capabilities to write down program annotations constantly, fine-tuning the LLM and offering it with error messages to assist it to appropriate its work could enhance efficiency sooner or later.
Work with Us
Over the subsequent two years, we plan to construct on these preliminary experiments via collaborator testing and suggestions. We need to associate with organizations and check our fashions of their environments with enter on which code weaknesses to prioritize. We’re additionally fascinated with collaborating to enhance the power of LLMs to write down and proper proofs, in addition to enhancing LLM prompts. We are able to additionally assist advise on the usage of on-premise LLMs, which some organizations could require because of the sensitivity of their knowledge.
Attain out to us to debate potential collaboration alternatives. You possibly can associate with the SEI to enhance the safety of your code and contribute to development of the sphere.