{kind=link}

Current developments in Giant Language Fashions (LLMs) have demonstrated distinctive pure language understanding and era capabilities. Analysis has explored the sudden talents of LLMs past their main coaching activity of textual content prediction. These fashions have proven promise in operate calling for software program APIs, supported by the launch of GPT-4 plugin options. Built-in instruments embody internet browsers, translation methods, Dialogue State Monitoring (DST), and robotics. Whereas LLMs present promising outcomes on the whole advanced reasoning, they nonetheless face challenges in mathematical problem-solving and logical capacities. To handle this, researchers have proposed strategies like operate calls, which permit LLMs to execute offered features and make the most of their outputs to help in varied activity completion. These features differ from fundamental instruments like calculators that carry out arithmetic operations to extra superior strategies. Nevertheless, concentrating on particular duties utilizing solely a small portion of obtainable APIs highlights the inefficiency of relying solely on massive fashions, which require main computational energy for each coaching and inference and due to the costly value of coaching. This case requires creating smaller, task-specific LLMs that preserve core performance whereas decreasing operational prices. Whereas promising, the pattern towards smaller fashions introduces new challenges.
Present strategies contain utilizing large-scale LLMs for reasoning duties, that are resource-intensive and dear. As a result of their generalized nature, these fashions usually wrestle with particular logical and mathematical problem-solving.
The proposed analysis technique introduces a novel framework for coaching smaller LLMs in operate calling, specializing in particular reasoning duties. This strategy employs an agent that queries the LLM by injecting descriptions and examples of usable features into the immediate, making a dataset of right and incorrect reasoning chain completions.
To handle the drawbacks of outsized LLMs, which incur extreme coaching and inference prices, a gaggle of researchers launched a novel framework to coach smaller language fashions ranging from the function-calling talents of huge fashions for particular logical and mathematical reasoning duties. Given an issue and a set of helpful features for its resolution, this framework includes an agent that queries a large-scale LLM by injecting operate descriptions and examples into the immediate and managing the right operate calls wanted to seek out the answer, all in a step-by-step reasoning chain. This process is used to create a dataset with right and incorrect completions. The generated dataset then trains a smaller mannequin utilizing a Reinforcement Studying from Human Suggestions (RLHF) strategy, generally known as Direct Choice Optimization (DPO). We current this technique examined on two reasoning duties, First-Order Logic (FOL) and math, utilizing a custom-built set of FOL issues impressed by the HuggingFace dataset.

The proposed framework’s pipeline contains 4 levels: first, defining duties and issues to evaluate the talents of huge language fashions (LLMs) in varied reasoning domains. Subsequent, features particular to every activity are arrange, permitting the LLM to resolve reasoning steps, handle the chain stream, and confirm outcomes. A pre-trained, large-scale LLM is then chosen to generate a dataset of right and incorrect completions utilizing a chain-of-thought prompting strategy. Lastly, a smaller LLM mannequin is fine-tuned utilizing the Direct Coverage Optimization (DPO) algorithm on the created dataset. Experimentation concerned testing the mannequin on first-order logic (FOL) and mathematical issues, with outcomes generated utilizing an agent-based library, Microchain, which facilitates LLM querying with predefined features to create a chain-of-thought dataset.
Information augmentation was carried out to increase the dataset, and fine-tuning was carried out on Mistral-7B utilizing a single GPU. Efficiency metrics demonstrated the mannequin’s accuracy enchancment in FOL duties and reasonable beneficial properties in mathematical duties, with statistical significance confirmed by means of a Wilcoxon check.
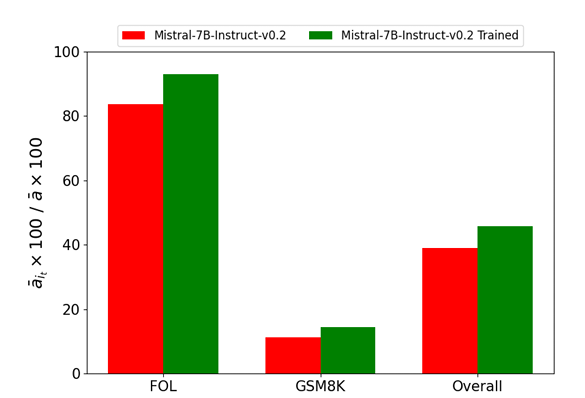
In conclusion, the researchers proposed a brand new framework for bettering the function-calling talents of small-scale LLMs, specializing in particular logical and mathematical reasoning duties. This technique reduces the necessity for big fashions and boosts the efficiency on logical and math-related duties. The experimental outcomes show vital enhancements within the efficiency of the small-scale mannequin on FOL duties, reaching near-perfect accuracy generally. In future work, there’s nice scope to discover the appliance of the launched framework to a broader vary of reasoning duties and performance sorts.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication.. Don’t Neglect to affix our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An Intensive Assortment of Small Language Fashions (SLMs) for Intel PCs
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Information Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and clear up challenges.