{kind=link}

Retrieval-augmented technology (RAG) represents an amazing development within the functionality of huge language fashions (LLMs) to carry out duties precisely by incorporating related exterior data into their processing workflows. This strategy, mixing data retrieval strategies with generative modeling, has seen rising utility in complicated functions similar to machine translation, query answering, and complete content material technology. By embedding paperwork into LLMs’ contexts, RAG permits fashions to entry and make the most of extra intensive and nuanced knowledge sources, successfully increasing the mannequin’s capability to deal with specialised queries. This system has confirmed particularly priceless in industries that require exact and knowledgeable responses, providing a transformative potential for fields the place accuracy and specificity are paramount.
A serious problem dealing with the event of huge language fashions is the efficient administration of huge contextual data. As LLMs develop extra highly effective, so does the demand for his or her potential to synthesize giant volumes of knowledge with out shedding the standard of their responses. Nonetheless, incorporating intensive exterior data typically leads to efficiency degradation, because the mannequin might need assistance to retain essential data throughout lengthy contexts. This difficulty is compounded in retrieval situations, the place fashions should pull from expansive data databases and combine them cohesively to generate significant output. Consequently, optimizing LLMs for longer context lengths is an important analysis purpose, significantly as functions more and more depend on high-volume, data-rich interactions.
Most standard RAG approaches use embedding paperwork in vector databases to facilitate environment friendly, similarity-based retrieval. This course of usually entails breaking down paperwork into retrievable chunks that may be matched to a consumer’s question based mostly on relevance. Whereas this technique has confirmed helpful for short-to-moderate context lengths, many open-source fashions expertise a decline in accuracy as context measurement will increase. Whereas some extra superior fashions exhibit promising accuracy with as much as 32,000 tokens, limitations stay in harnessing even larger context lengths to persistently improve efficiency, suggesting a necessity for extra refined approaches.
The analysis staff from Databricks Mosaic Analysis undertook a complete analysis of RAG efficiency throughout an array of each open-source and industrial LLMs, together with well-regarded fashions similar to OpenAI’s GPT-4, Anthropic’s Claude 3.5, and Google’s Gemini 1.5. This analysis examined the affect of accelerating context lengths, starting from 2,000 tokens as much as an unprecedented 2 million tokens, to evaluate how effectively numerous fashions may preserve accuracy when dealing with intensive contextual data. By various context lengths throughout 20 distinguished LLMs, the researchers aimed to determine which fashions show superior efficiency in long-context situations, making them higher fitted to functions requiring large-scale knowledge synthesis.
The analysis employed a constant methodology throughout all fashions, embedding doc chunks utilizing OpenAI’s text-embedding-3-large mannequin after which storing these chunks in a vector retailer. The research’s checks had been carried out on three specialised datasets: Databricks DocsQA, FinanceBench, and Pure Questions, every chosen for its relevance to real-world RAG functions. Within the technology stage, these embedded chunks had been then offered to a spread of generative fashions, the place efficiency was gauged based mostly on the mannequin’s potential to supply correct responses to consumer queries by integrating retrieved data from the context. This strategy in contrast every mannequin’s capability to deal with information-rich situations successfully.
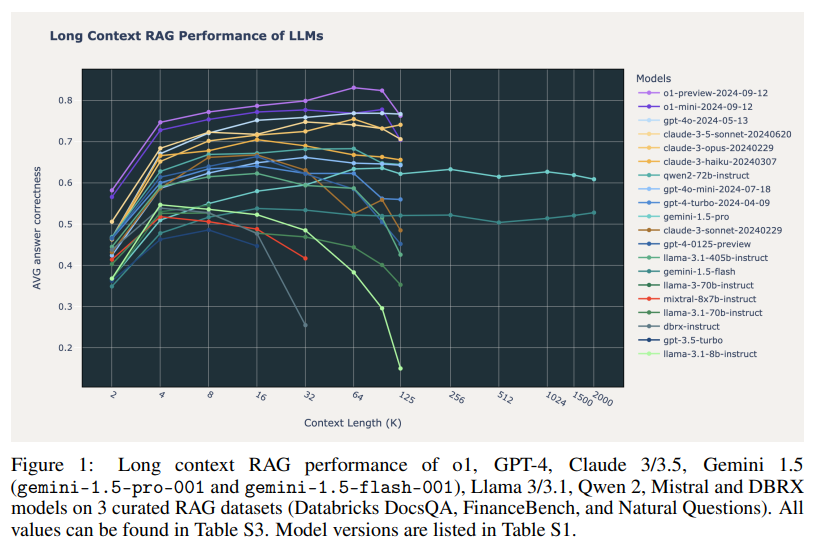
The outcomes confirmed notable variance in efficiency throughout the fashions. Not all benefited equally from expanded context lengths, as extending context didn’t persistently enhance RAG accuracy. The analysis discovered that fashions similar to OpenAI’s o1-mini and o1-preview, GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Professional confirmed regular enhancements, sustaining excessive accuracy ranges even as much as 100,000 tokens. Nonetheless, different fashions, significantly open-source choices like Qwen 2 (70B) and Llama 3.1 (405B), displayed efficiency degradation past the 32,000-token mark. Just a few of the most recent industrial fashions demonstrated constant long-context capabilities, revealing that whereas extending context can improve RAG efficiency, many fashions nonetheless face substantial limitations past sure token thresholds. Of specific curiosity, Google’s Gemini 1.5 Professional mannequin maintained accuracy at extraordinarily lengthy contexts, dealing with as much as 2 million tokens successfully, a exceptional feat not broadly noticed amongst different examined fashions.
Analyzing the failure patterns of fashions in long-context situations offered extra insights. Some fashions, similar to Claude 3 Sonnet, regularly refused to reply on account of issues round copyright compliance, particularly as context lengths elevated. Different fashions, together with Gemini 1.5 Professional, encountered difficulties on account of overly delicate security filters, leading to repeated refusals to finish sure duties. Open-source fashions additionally exhibited distinctive failure patterns; Llama 3.1, for instance, demonstrated constant failures in contexts above 64k tokens, typically by offering irrelevant or random content material. These outcomes underscore that long-context fashions fail in numerous methods, largely depending on context size and process calls for, and recommend particular areas for future enchancment.
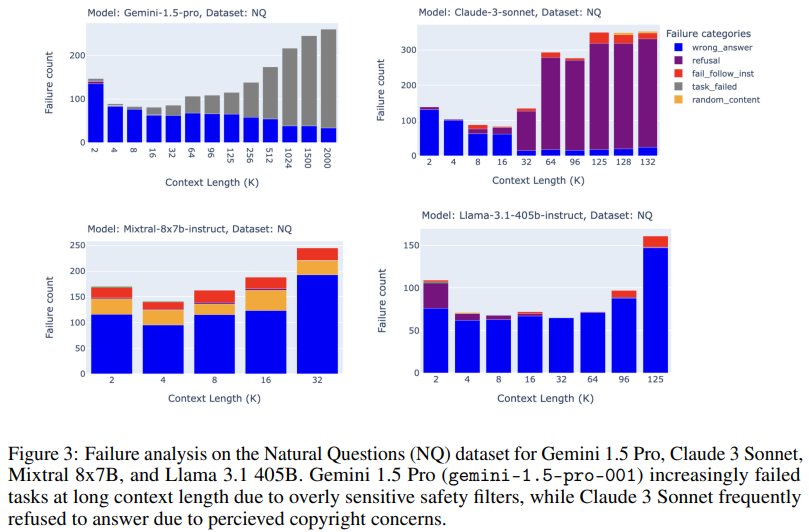
The research’s key findings reveal the potential and limitations of utilizing long-context LLMs for RAG functions. Whereas sure state-of-the-art fashions, similar to OpenAI’s o1 and Google’s Gemini 1.5 Professional, displayed constant enchancment in accuracy throughout lengthy contexts, most fashions solely demonstrated optimum efficiency inside shorter ranges, round 16,000 to 32,000 tokens. The analysis staff hypothesizes that superior fashions like o1 profit from elevated test-time computation, permitting them to deal with complicated questions and keep away from confusion from much less related retrieved paperwork. The staff’s findings spotlight the complexities of long-context RAG functions and supply priceless insights for researchers in search of to refine these strategies.
Key takeaways from the analysis embrace:
- Efficiency Stability: Solely a choose group of economic fashions, similar to OpenAI’s o1 and Google’s Gemini 1.5 Professional, maintained constant efficiency as much as 100,000 tokens and past.
- Efficiency Decline in Open-Supply Fashions: Most open-source fashions, together with Qwen 2 and Llama 3.1, skilled vital efficiency drops past 32,000 tokens.
- Failure Patterns: Fashions like Claude 3 Sonnet and Gemini 1.5 Professional failed otherwise, with points like process refusals on account of security filters or copyright issues.
- Excessive-Value Challenges: Lengthy-context RAG is cost-intensive, with processing prices starting from $0.16 to $5 per question, relying on the mannequin and context size.
- Future Analysis Wants: The research suggests additional analysis on context administration, error dealing with, and price mitigation in sensible RAG functions.

In conclusion, whereas prolonged context lengths current thrilling prospects for LLM-based retrieval, sensible limitations persist. Superior fashions like OpenAI’s o1 and Google’s Gemini 1.5 present promise, however broader applicability throughout numerous fashions and use circumstances requires continued refinement and focused enhancements. This analysis marks a necessary step towards understanding the trade-offs and challenges inherent in scaling RAG techniques for real-world functions.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Group Members
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.