: A Scalable Machine Studying Framework for Enhancing Reasoning Capabilities")
Reinforcement studying (RL) for big language fashions (LLMs) has historically relied on outcome-based rewards, which offer suggestions solely on the ultimate output. This sparsity of reward makes it difficult to coach fashions that want multi-step reasoning, like these employed in mathematical problem-solving and programming. Moreover, credit score task turns into ambiguous, because the mannequin doesn’t get fine-grained suggestions for intermediate steps. Course of reward fashions (PRMs) attempt to handle this by providing dense step-wise rewards, however they want expensive human-annotated course of labels, making them infeasible for large-scale RL. As well as, static reward features are affected by overoptimization and reward hacking, the place the mannequin takes benefit of the reward system in unexpected methods, ultimately compromising generalization efficiency. These limitations prohibit RL’s effectivity, scalability, and applicability for LLMs, calling for a brand new resolution that successfully combines dense rewards with out excessive computational expense or human annotations.
Current RL strategies for LLMs largely make use of end result reward fashions (ORMs), which provide scores just for the ultimate output. This leads to low pattern effectivity as fashions should generate and take a look at complete sequences earlier than getting suggestions. Some strategies make use of worth fashions that estimate future rewards from previous actions to counter this. Nonetheless, these fashions have excessive variance and don’t correctly deal with reward sparsity. PRMs supply extra fine-grained suggestions however want expensive guide annotations for intermediate steps and are liable to reward hacking due to static reward features. Moreover, most current strategies want an additional coaching section for the reward mannequin, including to the computational expense and making them infeasible for scalable on-line RL.
A gaggle of researchers from Tsinghua College, Shanghai AI Lab, College of Illinois Urbana-Champaign, Peking College, Shanghai Jiaotong College, and CUHK has proposed a reinforcement studying framework that eliminates the necessity for express step-wise annotations utilizing environment friendly utilization of dense suggestions. The primary contribution proposed is the introduction of an Implicit Course of Reward Mannequin (Implicit PRM), which produces token-level rewards independently of end result labels, thus eliminating the necessity for human-annotated step-level steering. The strategy permits for steady on-line enchancment of the reward mannequin, eliminating the issue of overoptimization with out permitting dynamic coverage rollout changes. The framework can efficiently combine implicit course of rewards with end result rewards throughout benefit estimation, providing computational effectivity and eliminating reward hacking. In contrast to earlier strategies, which require a separate coaching section for course of rewards, the brand new strategy initializes the PRM instantly from the coverage mannequin itself, thus significantly eliminating developmental overhead. It’s also made appropriate with a variety of RL algorithms, together with REINFORCE, PPO, and GRPO, thus making it generalizable and scalable for coaching massive language fashions (LLMs).

This reinforcement studying system supplies token-level implicit course of rewards, calculated by way of a log-ratio formulation between a discovered reward mannequin and a reference mannequin. Somewhat than guide annotation, the reward operate is discovered from uncooked end result labels, that are already obtained for coverage coaching. The system additionally consists of on-line studying of the reward operate to keep away from overoptimization and reward hacking. It makes use of a hybrid benefit estimation strategy that mixes implicit course of and end result rewards by way of a leave-one-out Monte Carlo estimator. Coverage optimization is achieved by way of Proximal Coverage Optimisation (PPO) utilizing a clipped surrogate loss operate for stability. The mannequin was educated utilizing Qwen2.5-Math-7B-Base, an optimized mannequin for mathematical reasoning. The system is predicated on 150K queries with 4 samples per question, in comparison with Qwen2.5-Math-7B-Instruct utilizing 618K in-house annotations, which demonstrates the effectiveness of the coaching course of.
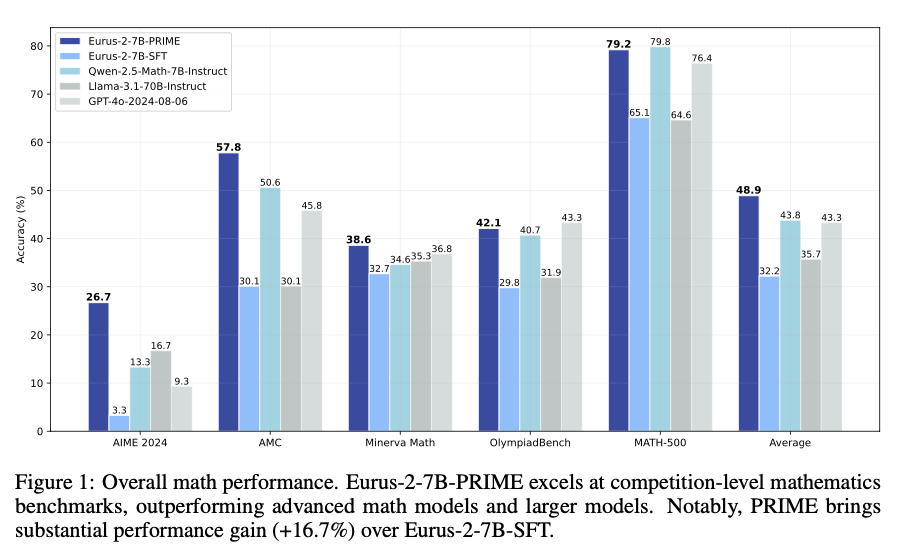
The reinforcement studying system demonstrates vital positive aspects in pattern effectivity and reasoning efficiency throughout a number of benchmarks. It supplies a 2.5× acquire in pattern effectivity and a 6.9% acquire in mathematical problem-solving in comparison with commonplace outcome-based RL. The mannequin outperforms Qwen2.5-Math-7B-Instruct on benchmarking mathematical benchmarks, with higher accuracy on competition-level duties like AIME and AMC. Fashions educated from this course of outperform bigger fashions, together with GPT-4o, by go@1 accuracy for difficult reasoning duties, even when utilizing solely 10% of the coaching knowledge utilized by Qwen2.5-Math-7B-Instruct. The outcomes affirm that on-line updates to the reward mannequin keep away from over-optimization, improve coaching stability, and improve credit score task, making it an especially highly effective technique for reinforcement studying in LLMs.
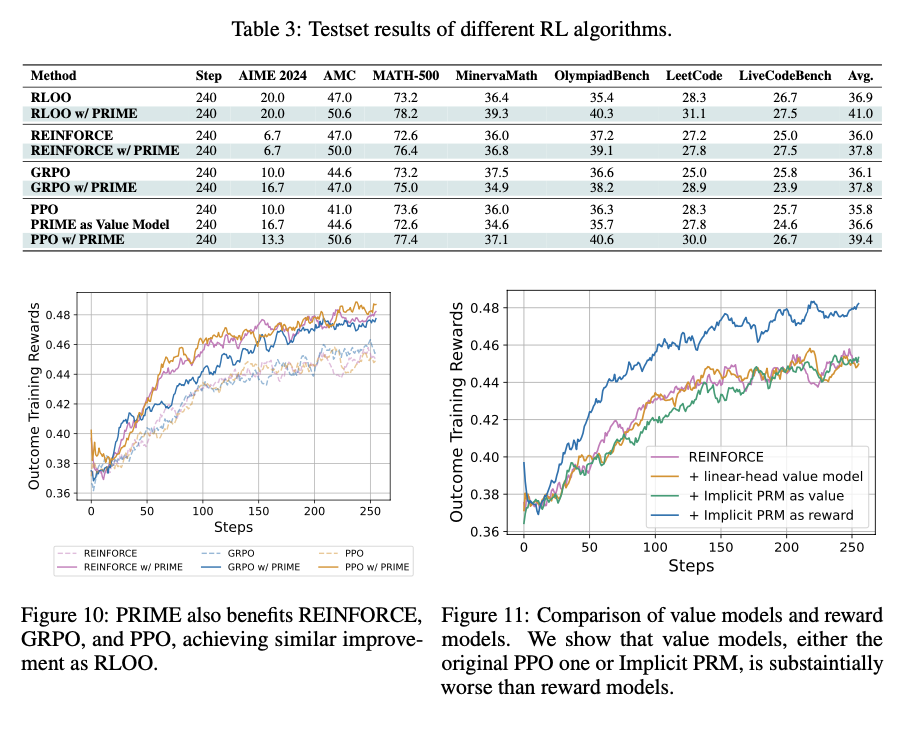
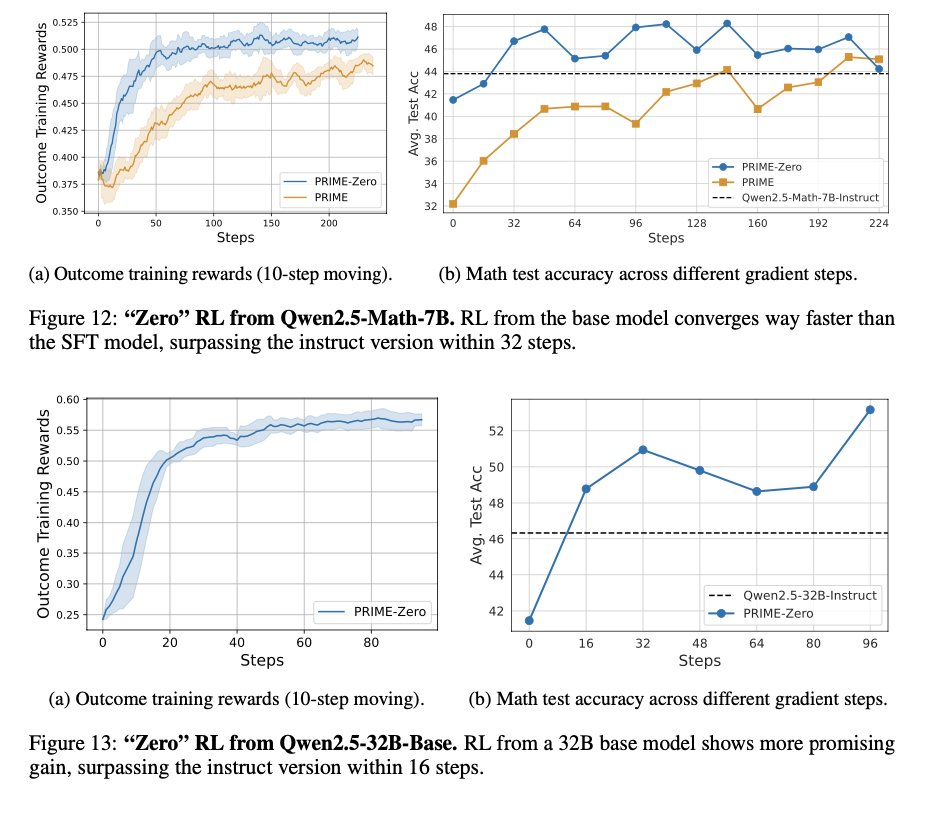
This reinforcement studying strategy supplies an environment friendly and scalable LLM coaching course of with dense implicit course of rewards. This eliminates step-level express annotations and minimizes coaching prices whereas enhancing pattern effectivity, stability, and efficiency. The method combines on-line reward modeling and token-level suggestions harmoniously, fixing long-standing issues of reward sparsity and credit score task in RL for LLMs. These enhancements optimize reasoning functionality in AI fashions and make them appropriate for problem-solving functions in arithmetic and programming. This analysis is a considerable contribution to RL-based LLM coaching, paving the best way for extra environment friendly, scalable, and high-performing AI coaching approaches.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 75k+ ML SubReddit.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.