{kind=link}

Breaking down movies into smaller, significant components for imaginative and prescient fashions stays difficult, notably for lengthy movies. Imaginative and prescient fashions depend on these smaller components, known as tokens, to course of and perceive video information, however creating these tokens effectively is tough. Whereas current instruments obtain higher video compression than older strategies, they battle to deal with giant video datasets successfully. A key problem is their incapability to totally make the most of temporal coherence, the pure sample the place video frames are sometimes comparable over brief durations, which video codecs use for environment friendly compression. These instruments are additionally computationally costly to coach and are restricted to brief clips, making them not very efficient in capturing patterns and processing longer movies.

Present video tokenization strategies have excessive computational prices and battle to deal with lengthy video sequences effectively. Early approaches used picture tokenizers to compress movies body by body however ignored the pure continuity between frames, decreasing their effectiveness. Later strategies launched spatiotemporal layers, decreased redundancy, and used adaptive encoding, however they nonetheless required rebuilding complete video frames throughout coaching, which restricted them to brief clips. Video era fashions like autoregressive strategies, masked generative transformers, and diffusion fashions are additionally restricted to brief sequences.
To unravel this, researchers from KAIST and UC Berkeley proposed CoordTok, which learns a mapping from coordinate-based representations to the corresponding patches of enter movies. Motivated by current advances in 3D generative fashions, CoordTok encodes a video into factorized triplane representations and reconstructs patches equivalent to randomly sampled (x, y, t) coordinates. This strategy permits giant tokenizer fashions to be educated instantly on lengthy movies with out requiring extreme assets. The video is split into space-time patches and processed utilizing transformer layers, with the decoder mapping sampled (x, y, t) coordinates to corresponding pixels. This reduces each reminiscence and computational prices whereas preserving video high quality.
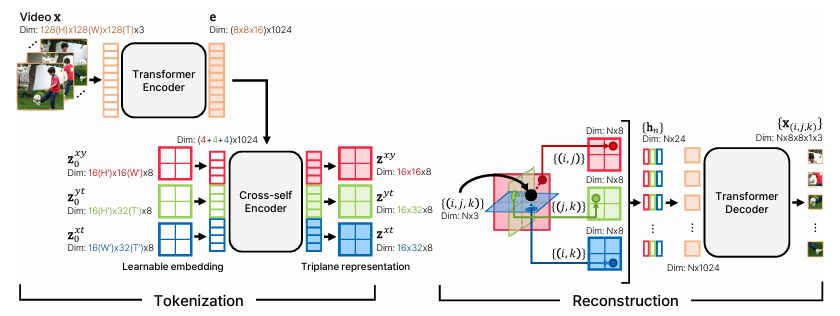
Based mostly on this, researchers up to date CoordTok to effectively course of a video by introducing a hierarchical structure that grasped native and world options from the video. This structure represented a factorized triplane to course of patches of area and time, making long-duration video processing simpler with out excessively utilizing computational assets. This strategy vastly decreased the reminiscence and computation necessities and maintained excessive video high quality.

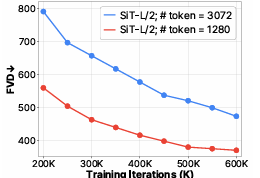

Researchers improved the efficiency by including a hierarchical construction that captured the native and world options of movies. This construction allowed the mannequin to course of space-time patches extra effectively utilizing transformer layers, which helped generate factorized triplane representations. Consequently, CoordTok dealt with longer movies with out demanding extreme computational assets. For instance, CoordTok encoded a 128-frame video with 128×128 decision into 1280 tokens, whereas baselines required 6144 or 8192 tokens to realize comparable reconstruction high quality. The mannequin’s reconstruction high quality was additional improved by fine-tuning with each ℓ2 loss and LPIPS loss, enhancing the accuracy of the reconstructed frames. This mixture of methods decreased reminiscence utilization by as much as 50% and computational prices whereas sustaining high-quality video reconstruction, with fashions like CoordTok-L reaching a PSNR of 26.9.
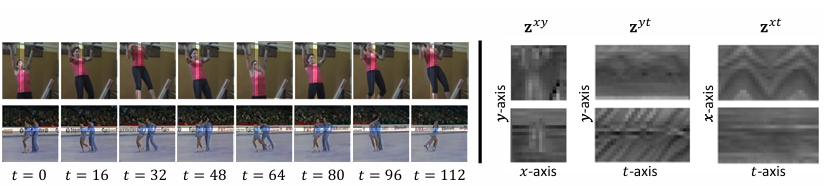
In conclusion, the proposed framework by researchers, CoordTok, proves to be an environment friendly video tokenizer that makes use of coordinate-based representations to scale back computational prices and reminiscence necessities whereas encoding lengthy movies.
It permits memory-efficient coaching for video era fashions, making dealing with lengthy movies with fewer tokens potential. Nevertheless, it isn’t sturdy sufficient for dynamic movies and suggests additional potential enhancements, similar to utilizing a number of content material planes or adaptive strategies. This work can function a place to begin for future analysis on scalable video tokenizers and era, which could be useful for comprehending and producing lengthy movies.
Try the Paper and Venture. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and clear up challenges.