{kind=link}

Creating AI brokers that may work together with the actual world is a superb space of analysis and growth. One helpful software is constructing brokers able to looking out the net to collect data and full duties. This weblog put up will information you thru the method of making such an agent utilizing LangChain, a framework for growing LLM-powered functions, and Llama 3.3, a state-of-the-art giant language mannequin.
Studying Targets
- Perceive the right way to construct an AI agent utilizing LangChain and Llama 3.3 for net looking out duties.
- Discover ways to combine exterior information sources like ArXiv and Wikipedia right into a web-searching agent.
- Achieve hands-on expertise establishing the setting and vital instruments to develop an AI-powered net app.
- Discover the function of modularity and error dealing with in creating dependable AI-driven functions.
- Perceive the right way to use Streamlit for constructing consumer interfaces that work together seamlessly with AI brokers.
This text was revealed as part of the Knowledge Science Blogathon.
What’s Llama 3.3?
Llama 3.3 is a 70-billion parameter, instruction-tuned giant language mannequin developed by Meta. It’s optimized to carry out higher on text-based duties, together with following directions, coding, and multilingual processing. As compared, it outperforms its forerunners, together with Llama 3.1 70B and Llama 3.2 90B. It may possibly even compete with bigger fashions, reminiscent of Llama 3.1 405B in some areas, whereas saving prices.
Options of Llama 3.3
- Instruction Tuning: Llama 3.3 is fine-tuned to observe directions precisely, making it extremely efficient for duties that require precision.
- Multilingual Assist: The mannequin helps a number of languages, together with English, Spanish, French, German, Hindi, Portuguese, Italian, and Thai, enhancing its versatility in numerous linguistic contexts.
- Price Effectivity: With aggressive pricing, Llama 3.3 may be an reasonably priced resolution for builders who need high-performance language fashions with out prohibitive prices.
- Accessibility: Its optimized structure permits it to be deployed on a wide range of {hardware} configurations, together with CPUs, making it accessible for a variety of functions.
What’s LangChain?
LangChain is an open-source framework, helpful for constructing functions powered by giant language fashions (LLMs). The suite of instruments and abstractions simplifies the combination of LLMs in numerous functions, enabling builders to create refined AI-driven options with ease.
Key Options of LangChain
- Chainable Parts: LangChain allows builders to create advanced workflows by chaining collectively totally different elements or instruments, facilitating the event of intricate functions.
- Device Integration: It helps the incorporation of varied instruments and APIs, enabling the event of brokers able to interacting with exterior programs simply.
- Reminiscence Administration: LangChain offers mechanisms for managing conversational context, permitting brokers to take care of state throughout interactions.
- Extensibility: The framework accommodates customized elements and integrations as wanted, making it simply extendable.
Core Parts of a Internet-Looking out Agent
Our web-searching agent will include the next key elements:
- LLM (Llama 3.3): The mind of the agent, liable for understanding consumer queries, producing search queries, and processing the outcomes.
- Search Device: A device that enables the agent to carry out net searches. We’ll use a search engine API for this goal.
- Immediate Template: A template that constructions the enter supplied to the LLM, guaranteeing it receives the required data within the appropriate format.
- Agent Executor: The part that orchestrates the interplay between the LLM and the instruments, executing the agent’s actions.
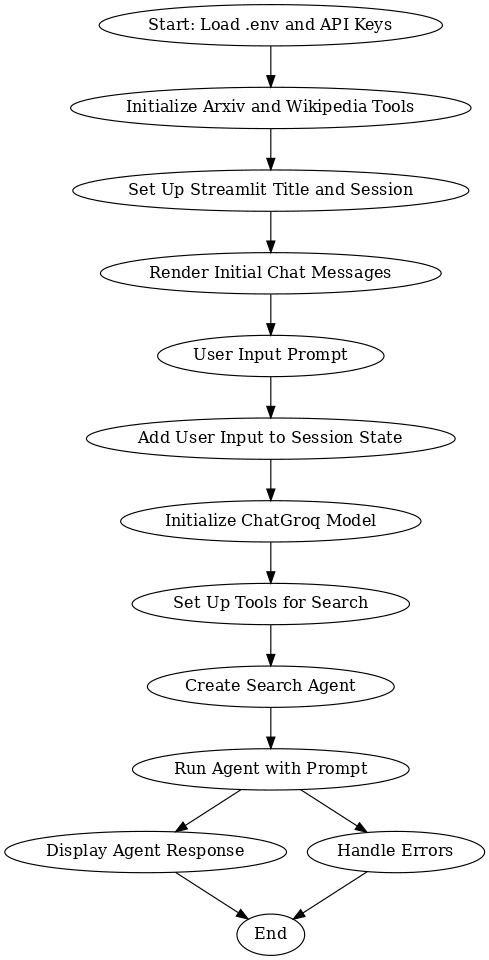
Movement Diagram
This workflow outlines the method of integrating a number of instruments and fashions to create an interactive system utilizing Arxiv, Wikipedia, and ChatGroq, powered by Streamlit. It begins by loading vital API keys and establishing the required instruments. The consumer is then prompted to enter their question, which is saved within the session state. The ChatGroq mannequin processes this enter whereas search instruments collect related data from Arxiv and Wikipedia. The search agent combines the responses and shows a related reply to the consumer.
The method ensures seamless consumer interplay by initializing the instruments, managing consumer enter, and offering correct responses. In case of errors, the system handles them gracefully, guaranteeing a easy expertise. General, this workflow permits the consumer to effectively obtain responses based mostly on real-time information, leveraging highly effective search and AI fashions for a wealthy and informative dialog.
Setting Up the Base
Establishing the bottom is the primary essential step in getting ready your setting for environment friendly processing and interplay with the instruments and fashions required for the duty.
Surroundings Setup
Surroundings setup includes configuring the required instruments, API keys, and settings to make sure a easy workflow for the challenge.
# Create a Surroundings
python -m venv env
# Activate it on Home windows
.envScriptsactivate
# Activate in MacOS/Linux
supply env/bin/activateSet up the Necessities.txt
pip set up -r https://uncooked.githubusercontent.com/Gouravlohar/Search-Agent/refs/heads/grasp/necessities.txtAPI Key Setup
Make a .env file in your challenge and go to Groq for API Key.
After getting your API Key paste it in your .env file
GROQ_API_KEY="Your API KEY PASTE HERE"Step1: Importing Mandatory Libraries
import streamlit as st
from langchain_groq import ChatGroq
from langchain_community.utilities import ArxivAPIWrapper, WikipediaAPIWrapper
from langchain_community.instruments import ArxivQueryRun, WikipediaQueryRun
from langchain.brokers import initialize_agent, AgentType
from langchain_community.callbacks.streamlit import StreamlitCallbackHandler # Up to date import
import os
from dotenv import load_dotenvImport libraries to construct the Webapp, work together with Llama 3.3, question ArXiv and Wikipedia instruments, initialize brokers, deal with callbacks, and handle setting variables.
Step2: Loading Surroundings Variables
load_dotenv()
api_key = os.getenv("GROQ_API_KEY") - load_dotenv(): Fetch setting variables from .env file within the challenge listing. This can be a safe option to handle delicate information.
- os.getenv(“GROQ_API_KEY”): Retrieves the GROQ_API_KEY from the setting(.env File), which is critical to authenticate requests to Groq APIs.
Step3: Setting Up ArXiv and Wikipedia Instruments
arxiv_wrapper = ArxivAPIWrapper(top_k_results=1, doc_content_chars_max=200)
arxiv = ArxivQueryRun(api_wrapper=arxiv_wrapper)
api_wrapper = WikipediaAPIWrapper(top_k_results=1, doc_content_chars_max=200)
wiki = WikipediaQueryRun(api_wrapper=api_wrapper)- top_k_results=1: Specifies that solely the highest end result needs to be retrieved.
- doc_content_chars_max=200: It is going to limits the size of the retrieved doc content material to 200 characters for summaries.
- ArxivQueryRun and WikipediaQueryRun: Join the wrappers to their respective querying mechanisms, enabling the agent to execute searches and retrieve outcomes effectively.
Step4: Setting the App Title
st.title("🔎Search Internet with Llama 3.3")Set a user-friendly title for the net app to point its goal.
Step5: Initializing Session State
if "messages" not in st.session_state:
st.session_state["messages"] = [
{"role": "assistant", "content": "Hi, I can search the web. How can I help you?"}
]Arrange a session state to retailer messages and make sure the chat historical past persists all through the consumer session.
Step6: Displaying Chat Messages
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg['content'])- st.chat_message(): It shows messages within the chat interface. The msg[“role”] determines whether or not the message is from the “consumer” or the “assistant.”
Step7: Dealing with Consumer Enter
if immediate := st.chat_input(placeholder="Enter Your Query Right here"):
st.session_state.messages.append({"function": "consumer", "content material": immediate})
st.chat_message("consumer").write(immediate)- st.chat_input(): Creates an enter discipline for the consumer to enter their query.
- Including Consumer Messages: Appends the consumer’s inquiries to the session state and shows it within the chat interface.
Step8: Initializing the Language Mannequin
llm = ChatGroq(groq_api_key=api_key, model_name="llama-3.3-70b-versatile", streaming=True)
instruments = [arxiv, wiki]- groq_api_key: Makes use of the API key to authenticate.
- model_name: Specifies the Llama 3.3 mannequin variant to make use of.
- streaming=True: Permits real-time response era within the chat window.
- Instruments: Contains the ArXiv and Wikipedia querying instruments, making them obtainable for the agent to make use of.
Step9: Initializing the Search Agent
search_agent = initialize_agent(instruments, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, handle_parsing_errors=True)Mix each the instruments and the language mannequin to create a zero-shot agent able to performing net searches and offering solutions.
Step10: Producing the Assistant’s Response
with st.chat_message("assistant"):
st_cb = StreamlitCallbackHandler(st.container(), expand_new_thoughts=False)
strive:
response = search_agent.run([{"role": "user", "content": prompt}], callbacks=[st_cb])
st.session_state.messages.append({'function': 'assistant', "content material": response})
st.write(response)
besides ValueError as e:
st.error(f"An error occurred: {e}")- st.chat_message(“assistant”): Shows the assistant’s response within the chat interface.
- StreamlitCallbackHandler: Manages how intermediate steps or ideas are displayed in Streamlit.
- search_agent.run(): Executes the agent’s reasoning and instruments to generate a response.
- Enter: A formatted checklist containing the consumer’s immediate.
Ensures the app handles points (e.g., invalid responses) gracefully, displaying an error message whennecessary.
Output
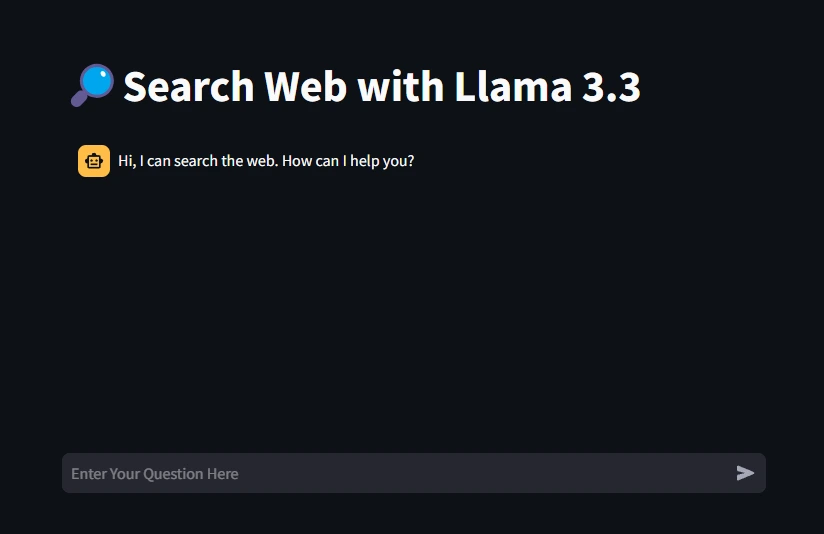
Testing the Webapp
- Enter: What’s Gradient Descent Algorithm
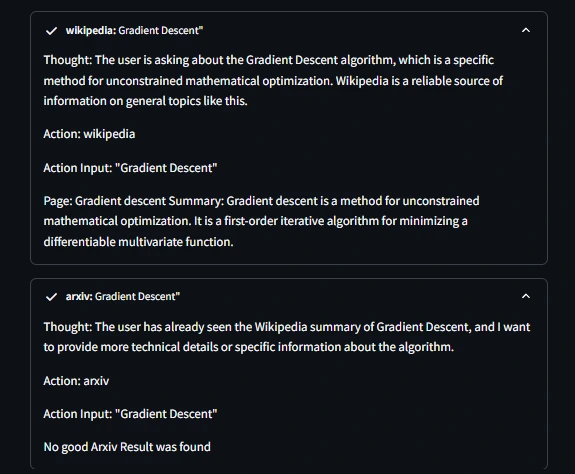

The Agent is offering thought output between each the instruments
Get the Full Code in GitHub Repo Right here
Conclusion
Constructing a web-searching agent with LangChain and Llama 3.3 demonstrates how the mixture of cutting-edge AI with exterior information sources reminiscent of ArXiv and Wikipedia can energy real-world functions that bridge the hole between conversational AI and real-world functions. Customers can effortlessly retrieve correct, context-aware data with this strategy. The challenge makes use of instruments like Streamlit for consumer interplay and setting variables for safety to supply a seamless and safe expertise for customers.
The modular design permits simple scoping, adapting all the system to domains and even use instances. This modularity, particularly in our AI-driven brokers like this instance, is how we create great steps towards extra clever programs that increase human capacities for capabilities in analysis and schooling; in actual fact, means additional than that. This analysis serves as the bottom platform for constructing even smarter interactive instruments that seize the excessive potential of AI in looking for information.
Key Takeaways
- This challenge demonstrates the right way to mix a language mannequin like Llama 3.3 with instruments like ArXiv and Wikipedia to create a sturdy web-searching agent.
- Streamlit offers a easy option to construct and deploy interactive net apps, making it splendid for chat-based instruments.
- Surroundings variables preserve delicate credentials, like API keys, safe by stopping publicity within the codebase.
- It is going to deal with parsing errors in the AI brokers, guaranteeing a greater reliability and consumer expertise within the software.
- This strategy ensures modularity via wrappers, question instruments, and LangChain brokers, permitting simple extension with further instruments or APIs.
Often Requested Questions
A. Llama 3.3 is a flexible language mannequin able to processing and understanding advanced queries. It’s used for its superior reasoning talents and pure language era.
A. These platforms present entry to analysis papers and Knowledge, making them splendid for a knowledge-enhanced web-searching agent.
A. Streamlit gives an intuitive framework to create a chat interface, enabling seamless interplay between the consumer and the AI agent.
A. Due to the modular nature of LangChain, we are able to combine different instruments to develop the agent’s capabilities.
A. We handle errors utilizing a try-except block, guaranteeing the app offers significant suggestions as an alternative of crashing.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Writer’s discretion.