{kind=link}
")
Recommender techniques (RecSys) have develop into an integral a part of fashionable digital experiences, powering personalised content material options throughout numerous platforms. These subtle techniques and algorithms analyze person conduct, preferences, and merchandise traits to foretell and advocate objects of curiosity. Within the period of massive knowledge and machine studying, recommender techniques have developed from easy collaborative filtering approaches to advanced fashions that leverage deep studying methods.
It may be difficult to scale these recommender techniques, particularly when coping with tens of millions of customers or 1000’s of merchandise. To take action requires discovering a stability between value, effectivity, and accuracy. A standard strategy to handle this scalability situation includes a two-stage course of: an preliminary, environment friendly “broad search” adopted by a extra computationally intensive “slender search” on probably the most related objects. For instance, in film suggestions, an efficient mannequin may first slender the search area from 1000’s to about 100 objects per person, after which apply a extra advanced mannequin for exact ordering of the highest 10 suggestions. This technique optimizes useful resource utilization whereas sustaining suggestion high quality, addressing scalability challenges in large-scale suggestion techniques.
Many corporations don’t have the assets to construct and scale recommender techniques of this dimension, however Databricks presents all of the important elements — together with knowledge processing, function engineering, mannequin coaching, monitoring, governance and serving — that may be mixed to create a state-of-the-art recommender system, in addition to the technical assist assets to assist implement them. This text is the primary in a collection designed to display efficient methods for coaching and deploying suggestion fashions at scale on Databricks. On this installment, we give attention to distributed knowledge loading and coaching. Subsequent articles will discover distributed checkpointing, inference, and the mixing of complementary elements, resembling vector shops, to create a strong, end-to-end recommender system pipeline.

This text presents a collection of reference options that function a strong basis for coaching enterprise-scale recommender techniques on the Databricks Knowledge Intelligence Platform. These options use Mosaic Streaming because the dataloader and TorchDistributor because the orchestrator for distributed coaching, each of which have been developed in-house at Databricks. By utilizing TorchRec, a extremely scalable recommender system package deal leveraging PyTorch, we showcase implementations of two superior deep studying fashions that align with the two-stage strategy talked about earlier: the Two Tower mannequin, superb for the environment friendly “broad search” part, and Meta’s DLRM (Deep Studying Suggestion Mannequin), suited to the extra intensive “slender search” part. Each fashions are able to dealing with tens of millions of customers and objects effectively, with the Two Tower mannequin rapidly narrowing down the candidate set from probably tens of millions to 1000’s, and DLRM offering exact ordering of probably the most related objects. To facilitate seamless integration into your workspaces and tasks, we have made these fashions obtainable by the Databricks market.
Two Tower
The Two Tower mannequin is an environment friendly structure for large-scale recommender techniques. As illustrated within the diagram, it contains two parallel neural networks: the “question tower” for customers and the “candidate tower” for merchandise. Every tower processes its enter (Consumer ID or Product ID) to generate dense embeddings, representing customers and merchandise in a shared area. The mannequin predicts user-item interactions by computing the similarity between these embeddings utilizing a dot product, enabling fast identification of doubtless related objects from an unlimited catalog. This makes it superb for the preliminary “broad search” part in suggestion techniques.
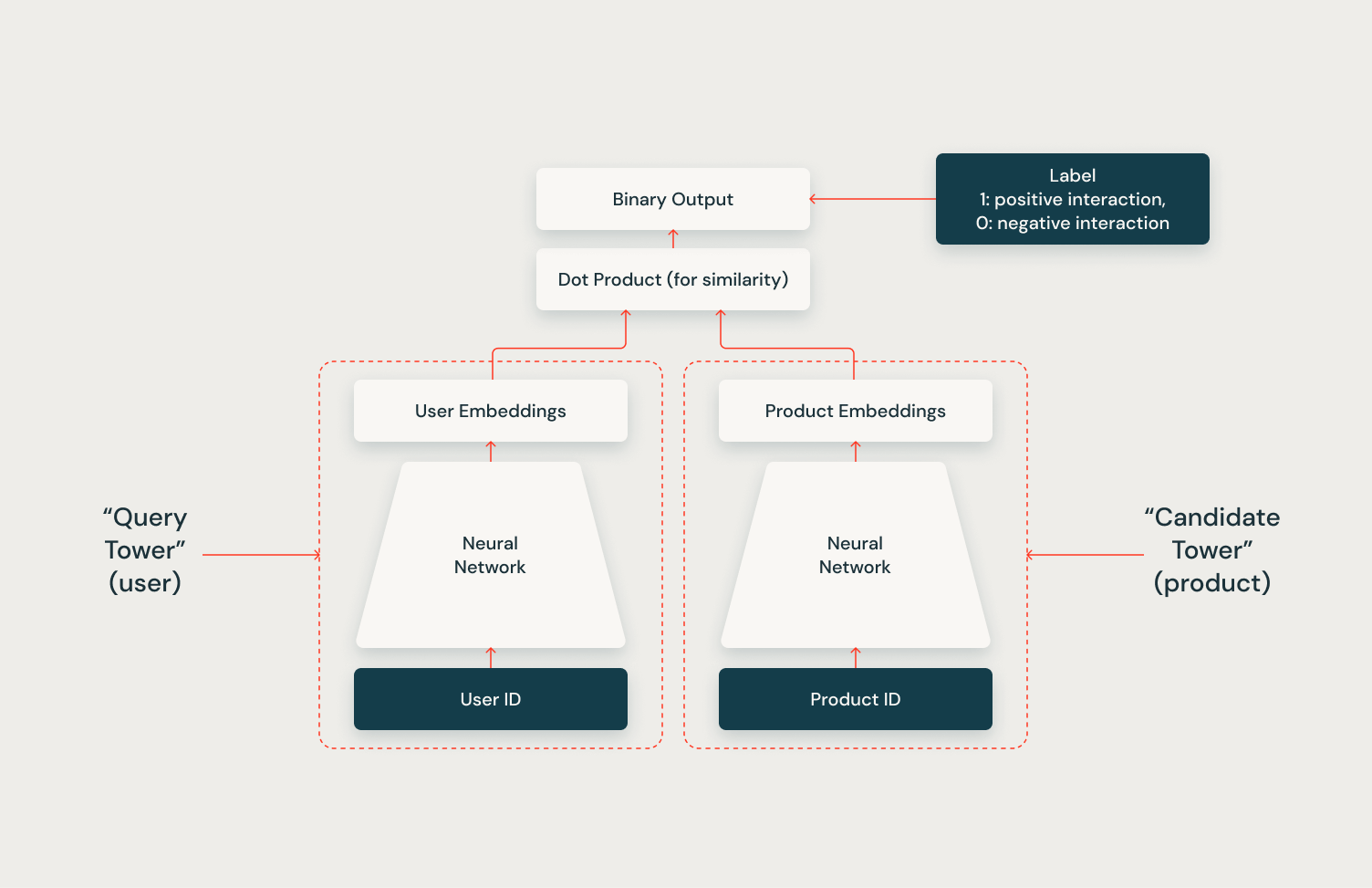
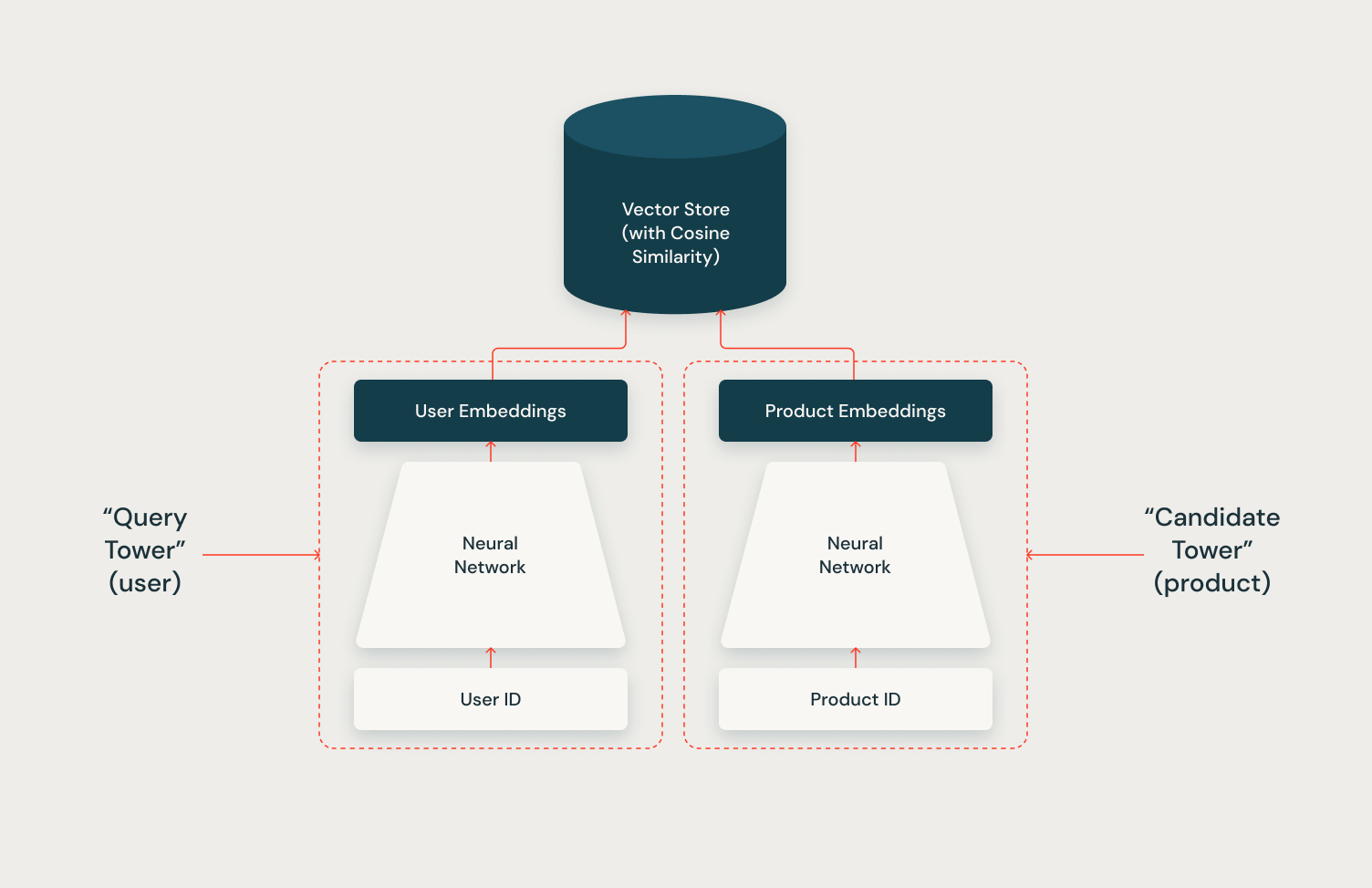
The Two Tower structure’s full potential is realized by its integration with a vector retailer. By leveraging a vector retailer to index candidate vectors, the system can effectively and scalably retrieve lots of of related candidates for every person throughout inference. In a future article on this collection, we’ll display tips on how to implement this integration utilizing the Mosaic AI Vector Retailer and the Two Tower mannequin, showcasing the facility of this mixed strategy.
DLRM
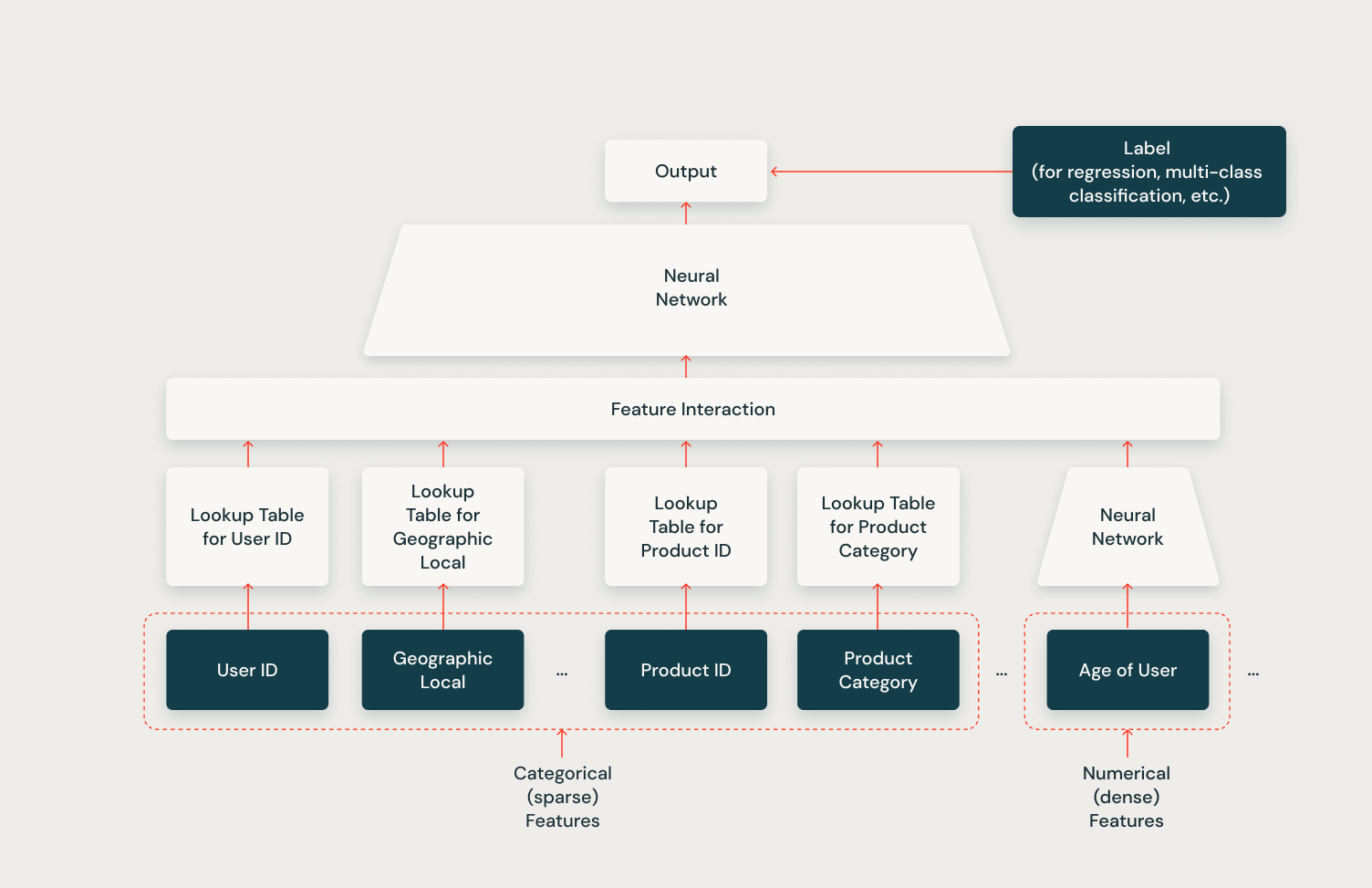
The Deep Studying Suggestion Mannequin (DLRM) by Meta, as illustrated within the following diagram, is a classy structure designed for large-scale suggestion techniques. It effectively handles each categorical (sparse) and numerical (dense) options, making it extremely versatile for numerous suggestion duties. The mannequin makes use of lookup tables to embed categorical options, and these embeddings, together with numerical options are then processed by a function interplay layer. This layer captures advanced relationships between completely different function sorts. The mixed options are then fed right into a neural community, which additional processes the knowledge to generate the ultimate output. This output can be utilized for numerous duties resembling regression or multi-class classification, relying on the particular suggestion drawback, however is most frequently used for predicting click-through charges. The DLRM’s capacity to deal with various function sorts and seize intricate function interactions makes it significantly efficient within the “slender search” part for exact merchandise rating in suggestion techniques.
For production-level DLRM mannequin coaching, we advocate leveraging the Databricks Characteristic Retailer. This highly effective instrument allows the seamless creation of coaching datasets with various function preparations for each customers and objects. Whereas the present Databricks documentation offers examples for less complicated recommender techniques, a future article on this collection will display tips on how to combine the Databricks Characteristic Retailer with the fashions mentioned right here.
How you can Prepare a Suggestion Mannequin
Each examples of coaching suggestion fashions share an analogous total construction, using state-of-the-art methods for large-scale distributed coaching.
Knowledge Preprocessing and Knowledge Loading with Mosaic Streaming
The examples in these phases leverage Mosaic Streaming, a vital instrument for optimizing the coaching course of on giant datasets saved in cloud environments. This strategy maximizes effectivity, cost-effectiveness, and scalability. When coaching giant recommender techniques, significantly people who must accommodate tens of millions of customers and/or objects, multi-node coaching is commonly obligatory. Nonetheless, distributed knowledge loading introduces a spread of challenges, together with synchronization points, reminiscence administration, and reproducibility throughout runs.
Mosaic Streaming is purpose-built to handle these challenges. It is particularly designed to assist multi-node, distributed coaching of huge fashions, with a give attention to guaranteeing correctness ensures, optimizing efficiency, offering flexibility, and enhancing ease-of-use. By tackling these crucial features, Mosaic Streaming allows seamless scaling of recommender techniques whereas mitigating the widespread pitfalls related to distributed coaching environments.
The preprocessing stage includes a number of steps:
- Amassing coaching knowledge from a desk in Unity Catalog
- Performing obligatory knowledge transformations
- Using Mosaic Streaming’s dataframe_to_mds API to materialize the processed knowledge right into a Unity Catalog Quantity
def save_data(df, output_path, label, num_workers=40):
print(f"Saving {label} knowledge to: {output_path}")
mds_kwargs = {'out': output_path, 'columns': columns, 'compression': compression}
dataframe_to_mds(df.repartition(num_workers), merge_index=True, mds_kwargs=mds_kwargs)
save_data(train_df, output_dir_train, 'prepare')
save_data(validation_df, output_dir_validation, 'validation')
save_data(test_df, output_dir_test, 'check')We then use Mosaic AI StreamingDataset and StreamingDataLoader APIs in our coaching operate to simply load the related knowledge for every node in a distributed atmosphere. Word that StreamingDataLoader is required in the event you want mid-epoch resumption. If that’s not wanted, utilizing the native Torch DataLoader is okay as nicely!
def get_dataloader_with_mosaic(path, batch_size, label):
print(f"Getting {label} knowledge from UC Volumes")
dataset = StreamingDataset(native=path, shuffle=True, batch_size=batch_size)
return StreamingDataLoader(dataset, batch_size=batch_size)
train_dataloader = get_dataloader_with_mosaic(input_dir_train, args.batch_size, "prepare")
val_dataloader = get_dataloader_with_mosaic(input_dir_validation, args.batch_size, "val")
test_dataloader = get_dataloader_with_mosaic(input_dir_test, args.batch_size, "check")Parallelizing Mannequin Coaching with TorchRec and the TorchDistributor
Recommender techniques that must scale to tens of millions of customers or objects can develop into overwhelming for a single node to deal with. In consequence, scaling to a number of nodes usually turns into obligatory for coaching these giant deep suggestion fashions. To handle this problem, options leverage a mixture of PyTorch’s TorchRec library and PySpark’s TorchDistributor to effectively scale suggestion mannequin coaching on Databricks.
TorchRec is a domain-specific library constructed on PyTorch, geared toward offering the required sparsity and parallelism primitives for large-scale recommender techniques. A key function of TorchRec is its capacity to effectively shard giant embedding tables throughout a number of GPUs or nodes utilizing the DistributedModelParallel and EmbeddingShardingPlanner APIs. Notably, TorchRec has been instrumental in powering among the largest fashions at Meta, together with a 1.25 trillion parameter mannequin and a 3 trillion parameter mannequin.
Complementing TorchRec, TorchDistributor is an open supply module built-in into PySpark that facilitates distributed coaching with PyTorch on Databricks. It’s designed to assist all distributed coaching paradigms provided by PyTorch, resembling Distributed Knowledge Parallel and Tensor Parallel, in numerous configurations, together with single-node multi-GPU and multi-node multi-GPU setups. Moreover, it offers a minimal API that enables customers to execute coaching on capabilities outlined throughout the present pocket book or utilizing exterior coaching information. An instance utilization of the TorchDistributor is as follows:
from pyspark.ml.torch.distributor import TorchDistributor
import torch.distributed as dist
import os
def principal():
# fundamental setup of related variables
local_rank = int(os.environ["LOCAL_RANK"])
global_rank = int(os.environ["RANK"])
machine = torch.machine(f"cuda:{local_rank}")
torch.cuda.set_device(machine)
# initializing course of group
dist.init_process_group(backend="nccl")
# TRAINING LOOP USING `machine` because the GPU to attribute to
# cleansing up course of group
dist.destroy_process_group()
# optionally available output to return
return output
# this association makes use of 8 GPUs in your databricks cluster for distributed coaching
output = TorchDistributor(num_processes=8, use_gpu=True, local_mode=False)The mix of TorchRec and the TorchDistributor allows the environment friendly dealing with of huge datasets and complicated fashions typical in enterprise-grade suggestion techniques.
Logging with MLflow
Within the reference options supplied, we use MLflow to log key objects, like mannequin hyperparameters, metrics, and the mannequin’s state_dict. Word that whereas the strategy taken within the instance notebooks collects the distributed mannequin onto one node earlier than saving to MLflow, this wouldn’t work for fashions which might be too massive to suit on one node. To handle this situation, the subsequent article on this collection will go into element on tips on how to do distributed mannequin checkpointing and large-scale mannequin inference on Databricks.
Subsequent Steps
On this article, we launched reference options for tips on how to implement and prepare extremely scalable deep suggestion fashions on Databricks. We briefly mentioned the Two Tower structure, the DLRM structure and the place they match contained in the prolonged recommender system pipeline. Lastly, we delved into the specifics of distributed knowledge loading and distributed mannequin coaching of those suggestion fashions on Databricks. That is simply the beginning: in future articles on this collection, we’ll talk about extra features of productionizing recommender techniques, together with distributed mannequin saving, inference, and integration with different instruments on Databricks.