{kind=link}


Welcome to the primary installment of a collection of posts discussing the just lately introduced Cloudera AI Inference service.
As we speak, Synthetic Intelligence (AI) and Machine Studying (ML) are extra essential than ever for organizations to show information right into a aggressive benefit. To unlock the complete potential of AI, nevertheless, companies must deploy fashions and AI purposes at scale, in real-time, and with low latency and excessive throughput. That is the place the Cloudera AI Inference service is available in. It’s a highly effective deployment atmosphere that allows you to combine and deploy generative AI (GenAI) and predictive fashions into your manufacturing environments, incorporating Cloudera’s enterprise-grade safety, privateness, and information governance.
Over the subsequent a number of weeks, we’ll discover the Cloudera AI Inference service in-depth, offering you with a complete introduction to its capabilities, advantages, and use circumstances.
On this collection, we’ll delve into matters equivalent to:
- A Cloudera AI Inference service structure deep dive
- Key options and advantages of the service, and the way it enhances Cloudera AI Workbench
- Service configuration and sizing of mannequin deployments based mostly on projected workloads
- The way to implement a Retrieval-Augmented Technology (RAG) system utilizing the service
- Exploring completely different use circumstances for which the service is a good alternative
In the event you’re excited about unlocking the complete potential of AI and ML in your group, keep tuned for our subsequent posts, the place we’ll dig deeper into the world of Cloudera AI Inference.
What’s the Cloudera AI Inference service?
The Cloudera AI Inference service is a extremely scalable, safe, and high-performance deployment atmosphere for serving manufacturing AI fashions and associated purposes. The service is focused on the production-serving finish of the MLOPs/LLMOPs pipeline, as proven within the following diagram:
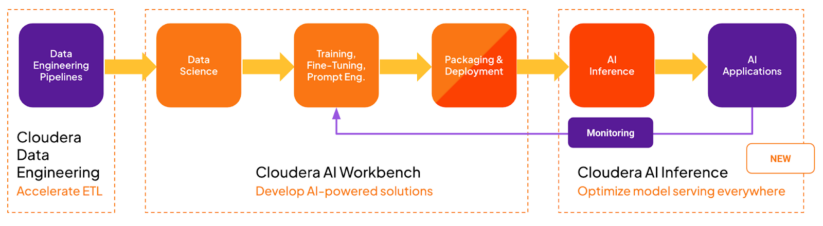
It enhances Cloudera AI Workbench (beforehand referred to as Cloudera Machine Studying Workspace), a deployment atmosphere that’s extra targeted on the exploration, improvement, and testing phases of the MLOPs workflow.
Why did we construct it?
The emergence of GenAI, sparked by the discharge of ChatGPT, has facilitated the broad availability of high-quality, open-source giant language fashions (LLMs). Providers like Hugging Face and the ONNX Mannequin Zoo made it straightforward to entry a variety of pre-trained fashions. This availability highlights the necessity for a sturdy service that allows prospects to seamlessly combine and deploy pre-trained fashions from varied sources into manufacturing environments. To satisfy the wants of our prospects, the service should be extremely:
- Safe – sturdy authentication and authorization, personal, and protected
- Scalable – tons of of fashions and purposes with autoscaling functionality
- Dependable – minimalist, quick restoration from failures
- Manageable – straightforward to function, rolling updates
- Requirements compliant – undertake market-leading API requirements and mannequin frameworks
- Useful resource environment friendly – fine-grained useful resource controls and scale to zero
- Observable – monitor system and mannequin efficiency
- Performant – best-in-class latency, throughput, and concurrency
- Remoted – keep away from noisy neighbors to offer sturdy service SLAs
These and different issues led us to create the Cloudera AI Inference service as a brand new, purpose-built service for internet hosting all manufacturing AI fashions and associated purposes. It’s perfect for deploying always-on AI fashions and purposes that serve business-critical use circumstances.
Excessive-level structure
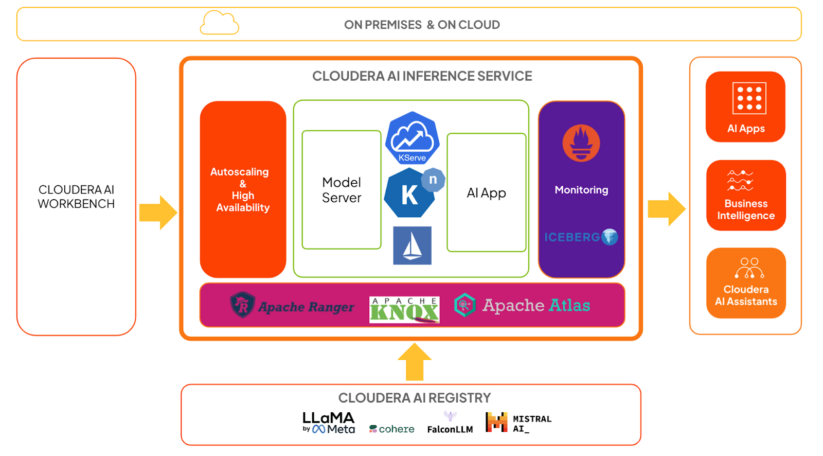
The diagram above exhibits a high-level structure of Cloudera AI Inference service in context:
- KServe and Knative deal with mannequin and software orchestration, respectively. Knative gives the framework for autoscaling, together with scale to zero.
- Mannequin servers are chargeable for operating fashions utilizing extremely optimized frameworks, which we are going to cowl intimately in a later publish.
- Istio gives the service mesh, and we reap the benefits of its extension capabilities so as to add sturdy authentication and authorization with Apache Knox and Apache Ranger.
- Inference request and response payloads ship asynchronously to Apache Iceberg tables. Groups can analyze the information utilizing any BI software for mannequin monitoring and governance functions.
- System metrics, equivalent to inference latency and throughput, can be found as Prometheus metrics. Knowledge groups can use any metrics dashboarding software to watch these.
- Customers can practice and/or fine-tune fashions within the AI Workbench, and deploy them to the Cloudera AI Inference service for manufacturing use circumstances.
- Customers can deploy educated fashions, together with GenAI fashions or predictive deep studying fashions, on to the Cloudera AI Inference service.
- Fashions hosted on the Cloudera AI Inference service can simply combine with AI purposes, equivalent to chatbots, digital assistants, RAG pipelines, real-time and batch predictions, and extra, all with commonplace protocols just like the OpenAI API and the Open Inference Protocol.
- Customers can handle all of their fashions and purposes on the Cloudera AI Inference service with frequent CI/CD programs utilizing Cloudera service accounts, also called machine customers.
- The service can effectively orchestrate tons of of fashions and purposes and scale every deployment to tons of of replicas dynamically, offered compute and networking assets can be found.
Conclusion
On this first publish, we launched the Cloudera AI Inference service, defined why we constructed it, and took a high-level tour of its structure. We additionally outlined a lot of its capabilities. We are going to dive deeper into the structure in our subsequent publish, so please keep tuned.