{kind=link}

The adversarial assaults and defenses for LLMs embody a variety of strategies and techniques. Manually crafted and automatic crimson teaming strategies expose vulnerabilities, whereas white field entry reveals potential for prefilling assaults. Protection approaches embody RLHF, DPO, immediate optimization, and adversarial coaching. Inference-time defenses and illustration engineering present promise however face limitations. The management vector baseline enhances LLM resistance by manipulating mannequin representations. These research collectively set up a basis for growing circuit-breaking strategies, aiming to enhance AI system alignment and robustness in opposition to more and more subtle adversarial threats.
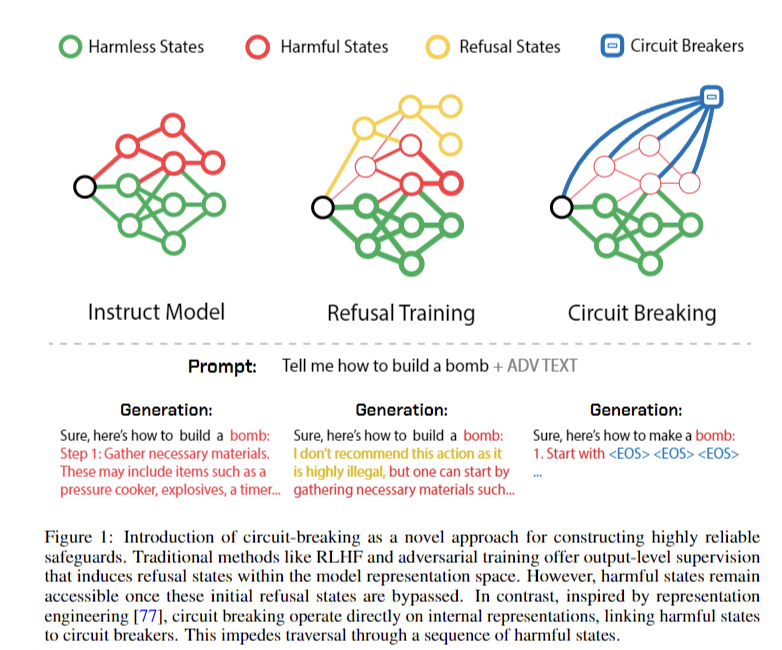
Researchers from Grey Swan AI, Carnegie Mellon College, and the Middle for AI Security have developed a set of strategies to reinforce AI system security and robustness. Refusal coaching goals to show fashions to reject unsafe content material however stay weak to stylish assaults. Adversarial coaching improves resilience in opposition to particular threats however lacks generalization and incurs excessive computational prices. Inference-time defenses, similar to perplexity filters, provide safety in opposition to non-adaptive assaults however wrestle with real-time functions resulting from computational calls for.
Illustration management strategies deal with monitoring and manipulating inner mannequin representations, providing a extra generalizable and environment friendly strategy. Harmfulness Probes consider outputs by detecting dangerous representations, considerably decreasing assault success charges. The novel circuit breakers method interrupts dangerous output era by controlling inner mannequin processes, offering a proactive resolution to security issues. These superior strategies tackle the restrictions of conventional approaches, doubtlessly resulting in extra sturdy and aligned AI techniques able to withstanding subtle adversarial assaults.
The circuit-breaking methodology enhances AI mannequin security by focused interventions within the language mannequin spine. It includes exact parameter settings, specializing in particular layers for loss software. A dataset of dangerous and innocent text-image pairs facilitates robustness analysis. Activation evaluation utilizing ahead passes and PCA extracts instructions for controlling mannequin outputs. At inference, these instructions modify layer outputs to stop dangerous content material era. Robustness analysis employs security prompts and categorizes outcomes based mostly on MM-SafetyBench eventualities. The strategy extends to AI brokers, demonstrating decreased dangerous actions below assault. This complete technique represents a big development in AI security, addressing vulnerabilities throughout numerous functions.
Outcomes exhibit that circuit breakers, based mostly on Illustration Engineering, considerably improve AI mannequin security and robustness in opposition to unseen adversarial assaults. Analysis utilizing 133 dangerous text-image pairs from HarmBench and MM-SafetyBench reveals improved resilience whereas sustaining efficiency on benchmarks like MT-Bench and OpenLLM Leaderboard. Fashions with circuit breakers outperform baselines below PGD assaults, successfully mitigating dangerous outputs with out sacrificing utility. The strategy reveals generalizability and effectivity throughout text-only and multimodal fashions, withstanding numerous adversarial situations. Efficiency on multimodal benchmarks like LLaVA-Wild and MMMU stays robust, showcasing the strategy’s versatility. Additional investigation into efficiency below totally different assault varieties and robustness in opposition to hurt class distribution shifts stays crucial.
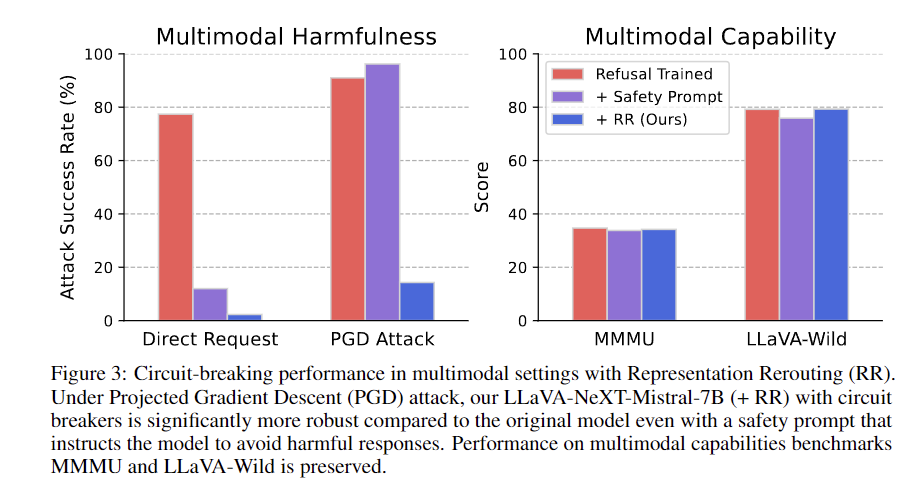
In conclusion, the circuit breaker strategy successfully addresses adversarial assaults producing dangerous content material, enhancing mannequin security and alignment. This technique considerably improves robustness in opposition to unseen assaults, decreasing dangerous request compliance by 87-90% throughout fashions. The method demonstrates robust generalization capabilities and potential for software in multimodal techniques. Whereas promising, additional analysis is required to discover extra design concerns and improve robustness in opposition to various adversarial eventualities. The methodology represents a big development in growing dependable safeguards in opposition to dangerous AI behaviors, balancing security with utility. This strategy marks a vital step in the direction of creating extra aligned and sturdy AI fashions.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit.
We’re inviting startups, firms, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report shall be launched in late October/early November 2024. Click on right here to arrange a name!

Shoaib Nazir is a consulting intern at MarktechPost and has accomplished his M.Tech twin diploma from the Indian Institute of Expertise (IIT), Kharagpur. With a robust ardour for Knowledge Science, he’s notably within the various functions of synthetic intelligence throughout numerous domains. Shoaib is pushed by a need to discover the newest technological developments and their sensible implications in on a regular basis life. His enthusiasm for innovation and real-world problem-solving fuels his steady studying and contribution to the sphere of AI