{kind=link}

Whereas giant language fashions (LLMs) are more and more adept at fixing normal duties, they’ll typically fall brief on particular domains which might be dissimilar to the info they had been educated on. In such instances, how do you successfully and effectively adapt an open-source LLM to your wants? This may be difficult as a result of many selections concerned, akin to coaching strategies and information choice. This weblog put up will discover one technique for customizing LLMs — Continued Pre-Coaching (CPT) — and supply steering on executing this course of successfully. Moreover, we think about how CPT can be utilized as a software to effectively characterize datasets, i.e. higher perceive which analysis metrics are helped, damage, or unaffected by the info.
Efficient CPT requires consideration to a few key hyperparameters: (1) studying price, (2) coaching length, and (3) information combination. As well as, easy weight averaging is a simple option to mitigate forgetting brought on by CPT. This weblog outlines these processes from begin to end that will help you unlock probably the most worth out of your CPT runs.
Continued Pre-Coaching vs. Advantageous-Tuning
What’s Continued Pre-Coaching (CPT), and the way does it differ from fine-tuning?
When working with a brand new, particular area (eg. a medical area) that was not properly represented in a mannequin’s pre-training corpus, the mannequin may lack factual information vital to performing properly on that area. Whereas one may pre-train a brand new mannequin from scratch, this isn’t an economical technique as pre-trained fashions already possess many core language and reasoning capabilities that we need to leverage on the brand new area. Continued Pre-Coaching refers back to the value efficient various to pre-training. On this course of, we additional practice a base pre-trained LLM on a big corpus of domain-specific textual content paperwork. This augments the mannequin’s normal information with particular data from the actual area. The info sometimes consists of enormous quantities of uncooked textual content, akin to medical journals or mathematical texts.
Advantageous-Tuning, however, entails coaching a language mannequin on a a lot smaller, task-specific dataset. This dataset typically comprises labeled input-output pairs, akin to questions and solutions, to align the mannequin’s habits to carry out a particular, well-defined process. Whereas a CPT dataset may comprise billions of tokens of uncooked, unstructured textual content, a fine-tuning dataset will comprise thousands and thousands of tokens of structured input-output pairs. That is typically not a enough quantity of knowledge to show a mannequin factual data from a very new area. On this case, it will be more practical to fine-tune for model and alignment after CPT.
On this put up, we concentrate on the case of continued pre-training. We reveal how CPT can improve a small LLM’s factual information efficiency to match that of a a lot bigger LLM. We’ll define the whole course of for:
- Displaying the right way to optimize hyperparameters.
- Measuring the impact of various datasets.
- Growing heuristics for mixing datasets.
- Mitigating forgetting.
Lastly we think about how the efficiency positive factors from continued pre-training scale with coaching FLOPS, a measure of the quantity of compute used to coach the mannequin.
Find out how to do Continued Pre-training
Process and Analysis
For our experiments, we’ll consider our mannequin on the MMLU benchmark, which assessments the mannequin’s capacity to recall a variety of information. This benchmark supplies a stand in for the overall strategy of factual information acquisition in LLMs.
Along with the MMLU benchmark, we’ll monitor the Gauntlet Core Common[1], which averages a big set of language modeling benchmarks. This enables us to trace the core language and reasoning capabilities of the mannequin, making certain it doesn’t lose expertise in studying comprehension and language understanding, that are important for different downstream duties. Monitoring Core Common is a good way to maintain observe of forgetting in LLMs.
Fashions
We purpose to see if we are able to begin with a Llama-2-7B base mannequin and elevate its efficiency to match that of a Llama-2-13B base mannequin utilizing CPT. To review CPT throughout mannequin scales, we additionally reveal its efficacy at enhancing Llama-2-13B and Llama-2-70B.
Instance Datasets
For this experiment, we thought-about 5 datasets that we intuited may doubtlessly assist MMLU: OpenWebMath, FLAN, Wikipedia, Stack Change, and arXiv . These datasets, starting from 8B to 60B tokens, had been chosen for his or her high-quality sources and dense data to maximise normal information publicity.
Hyperparameters: The Key to Efficiency
When additional coaching open-source base fashions, two vital hyperparameters are the training price (LR) and the coaching length. The optimum values for these hyperparameters can differ based mostly on the mannequin, dataset measurement, dataset composition, and benchmark. Due to this fact, it’s important to brush each hyperparameters whereas iterating.
We use the next process to set these hyperparameters for OpenWebMath. We swept the LR for 15B tokens with values of 10e-6, 3e-6, 10e-5, and 3e-5. In Determine 1a, we are able to see that the accuracy on MMLU can differ by as a lot as 5 share factors based mostly on the LR, indicating the significance of this hyperparameter. Usually, 1B to 10B tokens are enough for figuring out the optimum LR.
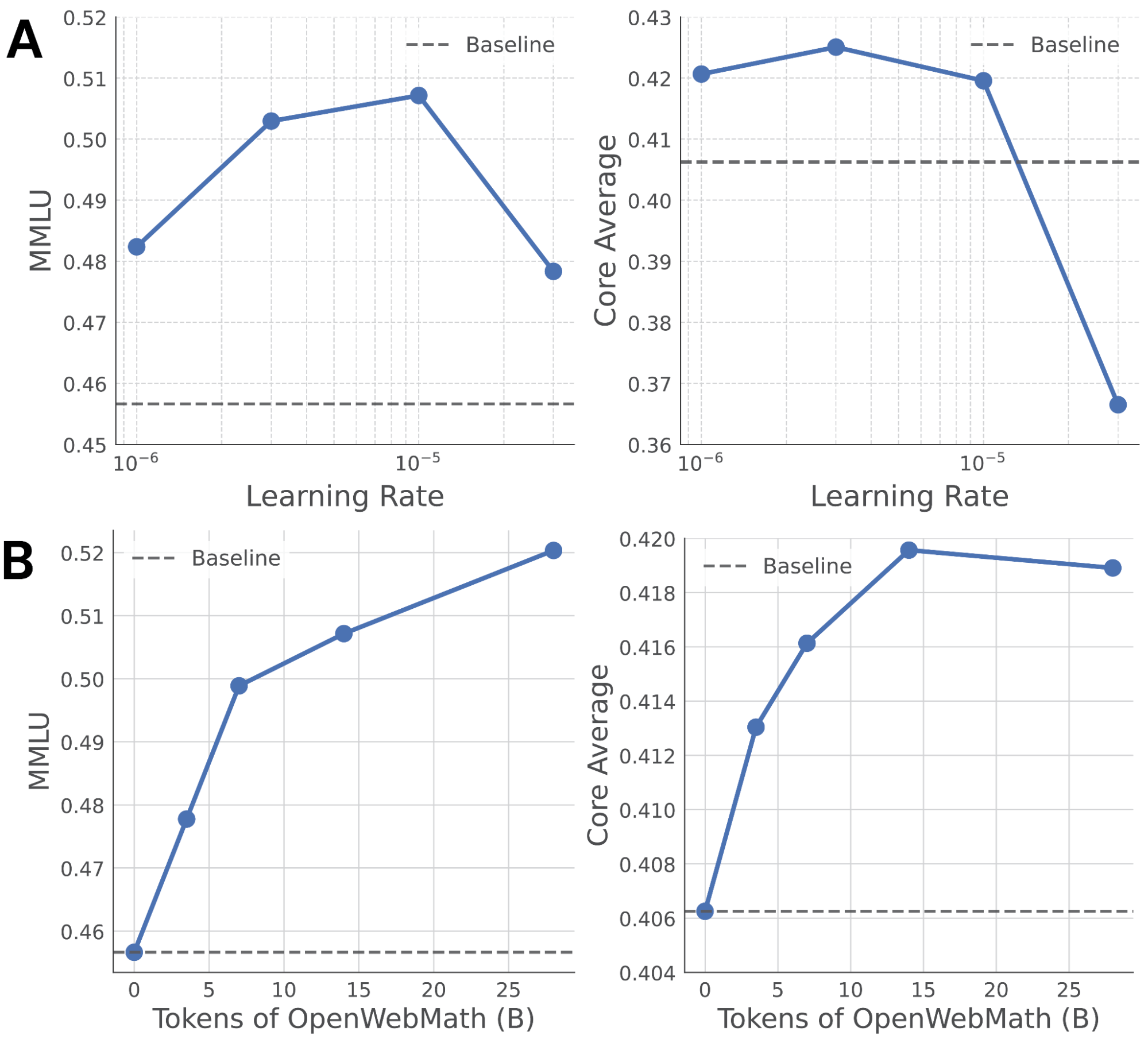
After figuring out the optimum LR, we educated on OpenWebMath for longer durations to find out the optimum coaching interval (Determine 1B). Along with measuring the efficiency on our goal MMLU metric, we additionally measure the Core Common to observe forgetting.
Capturing the affect of the dataset
We repeated the LR sweep (just like the one proven in Determine 1A for OpenWebMath) for every of our 5 datasets, coaching for between 1B and 10B tokens every time. Surprisingly, solely two of those high-quality datasets improved our mannequin’s efficiency: OpenWebMath and FLAN. The opposite datasets diminished accuracy throughout all LRs. Notably, the optimum studying charges for the completely different datasets weren’t the identical.
Determine 3 exhibits the length sweep of the optimum studying price for OpenWebMath and FLAN, the 2 datasets that resulted in MMLU enchancment. The crimson horizontal dashed line is the efficiency of Llama-2-7B base, the mannequin earlier than coaching. The black horizontal dashed line is the efficiency of Llama-2-13B base, a mannequin that’s twice as large. Each datasets led to substantial enhancements over Llama-2-7B base however had very completely different optimum durations. Whereas certainly one of our datasets led to improved efficiency at 8B tokens however worse efficiency with extra coaching (pink line in Determine 2), the opposite dataset confirmed constant efficiency enhancements as much as 40B tokens (blue line Determine 2). Moreover, monitoring our Core Common metric revealed that over-training on sure datasets may result in forgetting.
Thus, we see working LR sweeps on the 1B to 10B token regime is a quick and efficient option to determine which datasets improve mannequin efficiency. This enables us to take away ineffectual datasets and finally combine the useful datasets and practice them for longer durations, making CPT an environment friendly software for figuring out helpful datasets.
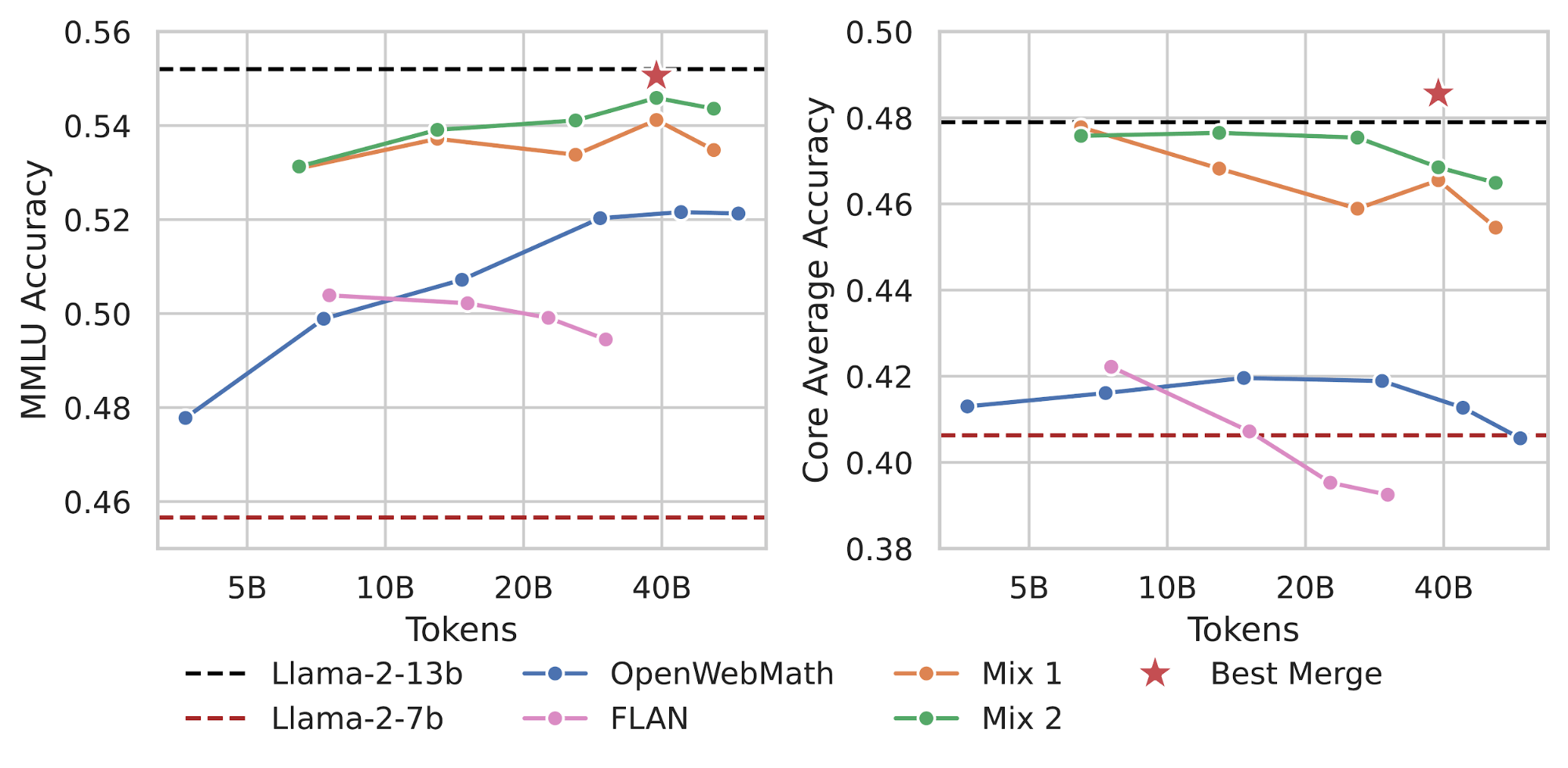
Mixing Datasets for Higher Efficiency
After figuring out particular person datasets that enhance efficiency and their optimum coaching durations, we blended them to attain additional enhancements. We advocate a easy heuristic: combine them within the ratio of the variety of tokens required for optimum efficiency for every dataset. For instance, we discovered success mixing them within the ratio of 8:40, or 16% of the info comes from FLAN (pink) and 84% comes from OpenWebMath (blue).
This straightforward heuristic outperforms mixing datasets in a 1:1 ratio or merely concatenating them. With the brand new blended dataset, we once more swept the LR at 1B tokens. We then swept the coaching length on the optimum studying price. This resulted in our CPT mannequin (orange line) at 40B tokens outperforming the Llama-2-7B base on each MMLU and Gauntlet Core Common, practically matching the efficiency of the Llama-2-13B base.
Mitigating Forgetting with Mannequin Soups
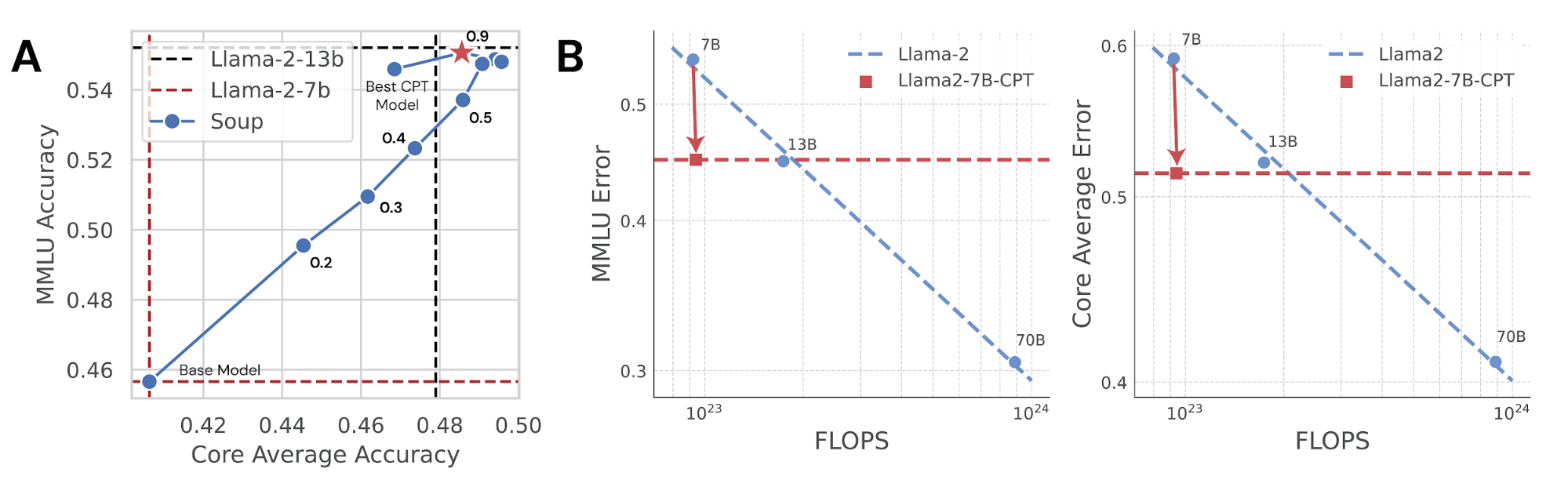
Whereas the mannequin educated for 40B tokens on our combine had the perfect efficiency on MMLU, it carried out barely worse on Core Common than fashions educated for a shorter length. To mitigate forgetting, we used mannequin souping: merely averaging the weights of two fashions which have the identical structure however are educated otherwise. We averaged the mannequin educated for 40B tokens on the blended dataset with Llama-2-7B base earlier than CPT. This not solely improved Core Common, decreasing forgetting, but additionally enhanced efficiency on MMLU, leading to our greatest mannequin but (crimson star in determine). The truth is, this mannequin matches or exceeds the efficiency of the Llama-2-13B base on each metrics.
Does Continued Pre-training Scale Effectively?
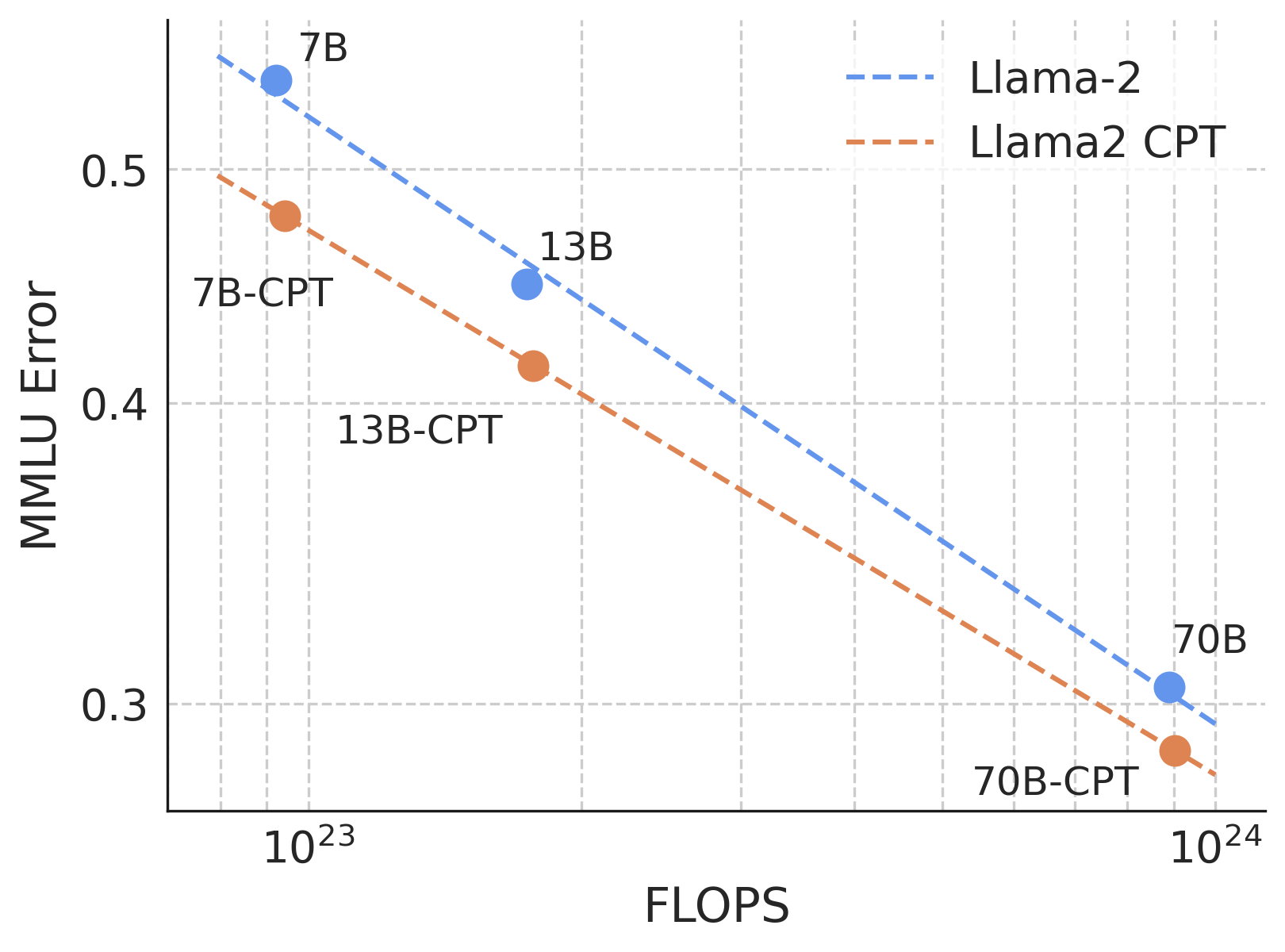
Lastly, we think about how properly CPT with OpenWebMath scales to fashions at bigger FLOP scales. We repeat the training price and length sweep with OpenWebMath carried out for Llama-2-7B above, however now with Llama-2-13B and Llama-2-70B. As proven in Determine 4, we proceed to see enhancements on the 10^24 FLOP scale, and the scaling curve signifies that we may doubtlessly see positive factors at even larger FLOPS. Every marker for the CPT runs represents the perfect MMLU efficiency following the training price and length sweep.
Conclusion
On this weblog put up, we explored the method of Continued Pre-Coaching (CPT) to reinforce a small LLM’s normal information efficiency to that of a bigger mannequin. We demonstrated the right way to successfully sweep hyperparameters, determine useful datasets, and blend datasets for improved efficiency. Moreover, we mentioned methods to mitigate forgetting via mannequin souping. By following these pointers, you possibly can leverage CPT to rapidly measure if completely different datasets are efficient at instructing fashions new data in addition to customise and improve your LLMs effectively, reaching outstanding efficiency enhancements.
An vital consideration is the success of CPT is prone to be depending on the unique pre-training information combine. For instance, as a result of OpenWebMath was launched after the Llama-2 household, our continued pre-training launched the mannequin to a novel mixture of high-quality mathematical information, and the outcomes may doubtlessly be altered if OpenWebMath was included within the pre-training corpus. Regardless, the outcomes reveal the power of CPT to adapt a mannequin to novel information in a FLOP environment friendly method.
[1] On this weblog, reported scores are Gauntlet v0.2 core common. In a current weblog put up Calibrating the Mosaic Analysis Gauntlet, we mentioned our strategy of constructing the Gauntlet v0.3 core common during which we eliminated a number of evals based mostly on poor scaling with coaching FLOPS. The v0.2 and v0.3 scores will probably be related however shouldn’t be immediately in contrast.