{kind=link}

Giant language fashions are enhancing quickly; to this point, this enchancment has largely been measured through tutorial benchmarks. These benchmarks, comparable to MMLU and BIG-Bench, have been adopted by researchers in an try to match fashions throughout varied dimensions of functionality associated to common intelligence. Nonetheless enterprises care in regards to the high quality of AI techniques in particular domains, which we name area intelligence. Area intelligence includes information and duties that take care of the inside workings of enterprise processes: particulars, jargon, historical past, inner practices and workflows, and the like.
Due to this fact, enterprise practitioners deploying AI in real-world settings want evaluations that immediately measure area intelligence. With out domain-specific evaluations, organizations might overlook fashions that will excel at their specialised duties in favor of those who rating nicely on presumably misaligned common benchmarks. We developed the Area Intelligence Benchmark Suite (DIBS) to assist Databricks clients construct higher AI techniques for his or her particular use instances, and to advance our analysis on fashions that may leverage area intelligence. DIBS measures efficiency on datasets curated to replicate specialised area information and customary enterprise use instances that conventional tutorial benchmarks usually overlook.
Within the the rest of this weblog publish, we are going to focus on how present fashions carry out on DIBS compared to comparable tutorial benchmarks. Our key takeaways embrace:
- Fashions’ rankings throughout tutorial benchmarks don’t essentially map to their rankings throughout business duties. We discover discrepancies in efficiency between tutorial and enterprise rankings, emphasizing the necessity for domain-specific testing.
- There’s room for enchancment in core capabilities. Some enterprise wants like structured information extraction present clear paths for enchancment, whereas extra advanced domain-specific duties require extra refined reasoning capabilities.
- Builders ought to select fashions based mostly on particular wants. There isn’t any single greatest mannequin or paradigm. From open-source choices to retrieval methods, totally different options excel in several situations.
This underscores the necessity for builders to check fashions on their precise use instances and keep away from limiting themselves to any single mannequin possibility.
Introducing our Area Intelligence Benchmark Suite (DIBS)
DIBS focuses on three of the commonest enterprise use instances surfaced by Databricks clients:
- Knowledge Extraction: Textual content to JSON
- Changing unstructured textual content (like emails, experiences, or contracts) into structured JSON codecs that may be simply processed downstream.
- Instrument Use: Perform Calling
- Enabling LLMs to work together with exterior instruments and APIs by producing correctly formatted operate calls.
- Agent Workflows: Retrieval Augmented Era (RAG)
- Enhancing LLM responses by first retrieving related data from an organization’s information base or paperwork.
We evaluated fourteen widespread fashions throughout DIBS and three tutorial benchmarks, spanning enterprise domains in finance, software program, and manufacturing. We’re increasing our analysis scope to incorporate authorized, information evaluation and different verticals, and welcome collaboration alternatives to evaluate further business domains and duties.
In Desk 1, we briefly present an outline of every process, the benchmark we’ve been utilizing internally, and tutorial counterparts if obtainable. Later, in Benchmark Overviews, we focus on these in additional element.
| Job Class | Dataset Identify | Enterprise or Tutorial | Area | Job Description |
|---|---|---|---|---|
|
Knowledge Extraction: Textual content to JSON |
Text2JSON | Enterprise | Misc. Data | Given a immediate containing a schema and some Wikipedia-style paragraphs, extract related data into the schema. |
| Instrument Use: Perform Calling | BFCL-Full Universe | Enterprise | Perform calling | Modification of BFCL the place, for every question, the mannequin has to pick out the right operate from the complete set of capabilities current within the BFCL universe. |
| Instrument Use: Perform Calling | BFCL–Retrieval | Enterprise | Perform calling | Modification of BFCL the place, for every question, we use text-embedding-3-large to pick out 10 candidate capabilities from the complete set of capabilities current within the BFCL universe. The duty then turns into to decide on the right operate from that set. |
| Instrument Use: Perform Calling | Nexus | Tutorial | APIs | Single flip operate calling analysis throughout 7 APIs of various problem |
| Instrument Use: Perform Calling |
Berkeley Perform Calling Leaderboard (BFCL) |
Tutorial | Perform calling | See authentic BFCL weblog. |
|
Agent Workflows: RAG |
DocsQA | Enterprise | Software program – Databricks Documentation with Code | Reply actual consumer questions based mostly on public Databricks documentation net pages. |
|
Agent Workflows: RAG |
ManufactQA | Enterprise |
Manufacturing – Semiconductors –Buyer FAQs
|
Given a technical buyer question about debugging or product points, retrieve essentially the most related web page from a corpus of a whole bunch of product manuals and datasheets, and assemble a solution like a buyer assist agent. |
|
Agent Workflows: RAG |
FinanceBench | Enterprise | Finance – SEC Filings | Carry out monetary evaluation on SEC filings, from Patronus AI |
|
Agent Workflows: RAG |
Pure Questions | Tutorial | Wikipedia | Extractive QA over Wikipedia articles |
Desk 1. We consider the set of fashions throughout 9 duties spanning 3 enterprise process classes: information extraction, instrument use, and agent workflows. The three classes we focus on have been chosen as a consequence of their relative frequency in enterprise workloads. Past these classes, we’re persevering with to develop to a broader set of analysis duties in collaboration with our clients.
What We Discovered Evaluating LLMs on Enterprise Duties
Tutorial Benchmarks Obscure Enterprise Efficiency Gaps
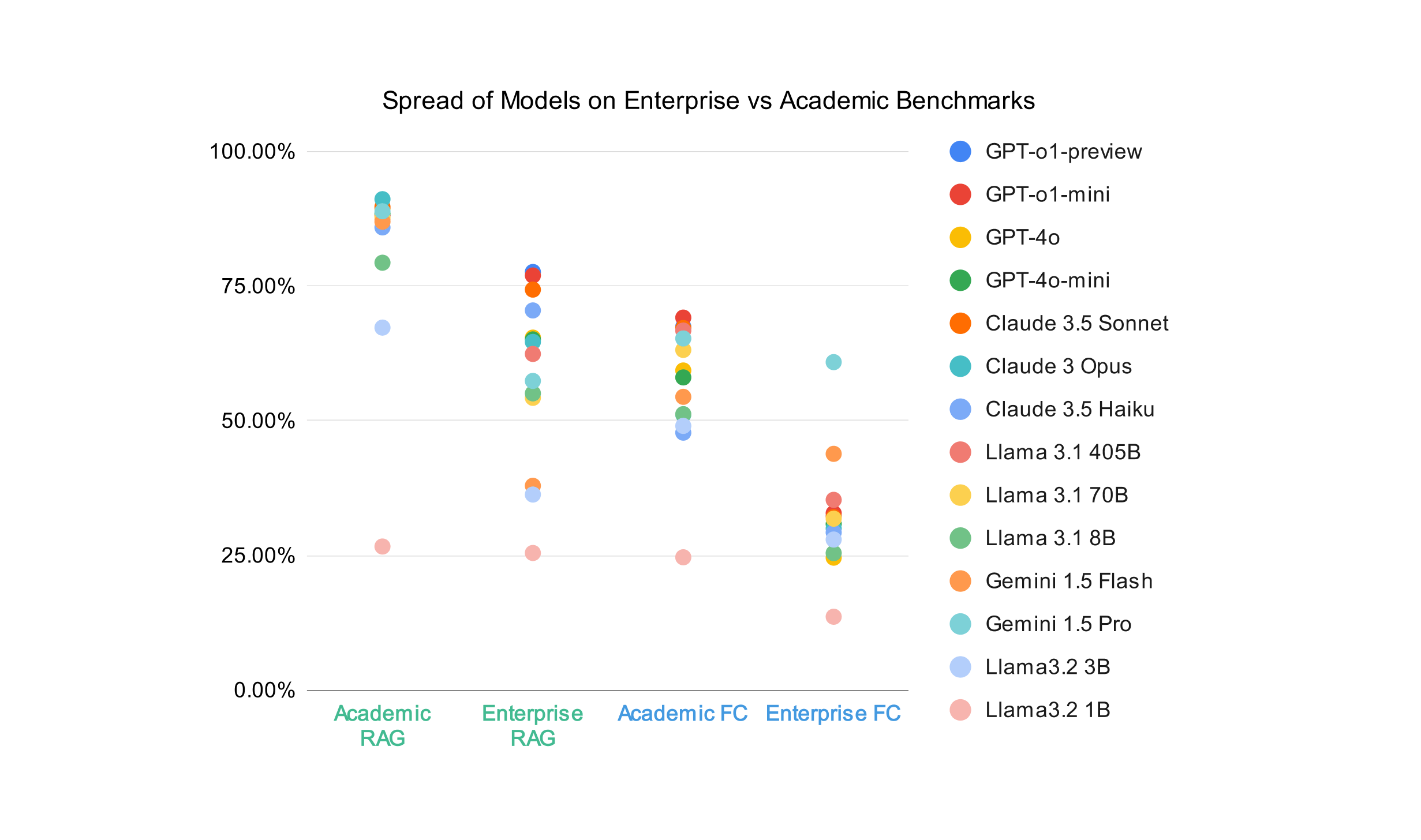
In Determine 1, we present a comparability of RAG and performance calling (FC) capabilities between the enterprise and tutorial benchmarks, with common scores plotted for all fourteen fashions. Whereas the tutorial RAG common has a bigger vary (91.14% on the high, and 26.65% on the backside), we are able to see that the overwhelming majority of fashions rating between 85% and 90%. The enterprise RAG set of scores has a narrower vary, as a result of it has a decrease ceiling – this reveals that there’s extra room to enhance in RAG settings than a benchmark like NQ would possibly counsel.
Determine 1 visually reveals wider efficiency gaps in enterprise RAG scores, proven by the extra dispersed distribution of knowledge factors, in distinction to the tighter clustering seen within the tutorial RAG column. That is most certainly as a result of tutorial benchmarks are based mostly on common domains like Wikipedia, are public, and are a number of years outdated – due to this fact, there’s a excessive likelihood that retrieval fashions and LLM suppliers have already educated on the info. For a buyer with personal, area particular information although, the capabilities of the retrieval and LLM fashions are extra precisely measured with a benchmark tailor-made to their information and use case. An analogous impact will be noticed, although it’s much less pronounced, within the operate calling setting.
Structured Extraction (Text2JSON) presents an achievable goal

At a excessive stage, we see that the majority fashions have vital room for enchancment in prompt-based Text2JSON; we didn’t consider mannequin efficiency when utilizing structured era.
Determine 2 reveals that on this process, there are three distinct tiers of mannequin efficiency:
- Most closed-source fashions in addition to Llama 3.1 405B and 70B rating round simply 60%
- Claude 3.5 Haiku, Llama 3.1 8B and Gemini 1.5 Flash convey up the center of the pack with scores between 50% and 55%.
- The smaller Llama 3.2 fashions are a lot worse performers.
Taken collectively, this means that prompt-based Text2JSON is probably not enough for manufacturing use off-the-shelf even from main mannequin suppliers. Whereas structured era choices can be found, they could impose restrictions on viable JSON schemas and be topic to totally different information utilization stipulations. Thankfully, we’ve had success fine-tuning fashions to enhance at this functionality.
Different duties might require extra refined capabilities
We additionally discovered FinanceBench and Perform Calling with Retrieval to be difficult duties for many fashions. That is seemingly as a result of the previous requires a mannequin to be proficient with numerical complexity, and the latter requires a capability to disregard distractor data.
No Single Mannequin Dominates all Duties
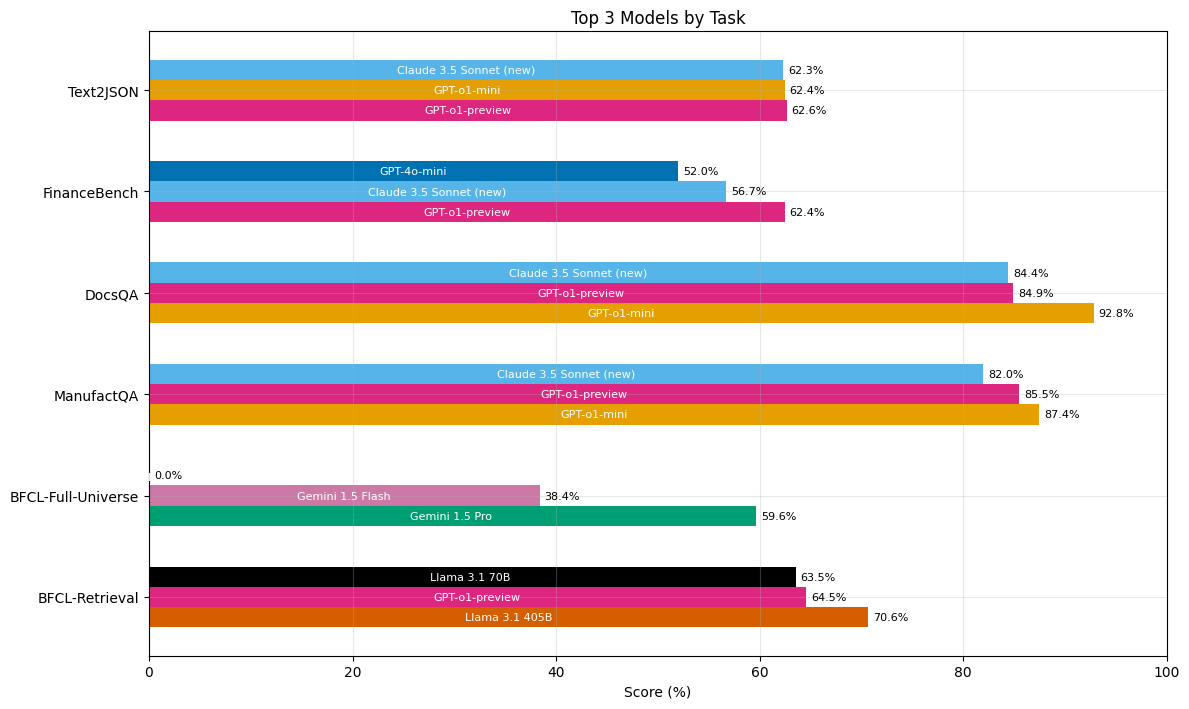
Our analysis outcomes don’t assist the declare that anybody mannequin is strictly superior to the remainder. Determine 3 demonstrates that essentially the most persistently high-performing fashions have been o1-preview, Claude Sonnet 3.5 (New), and o1-mini, reaching high scores in 5, 4, and three out of the 6 enterprise benchmark duties respectively. These identical three fashions have been total one of the best performers for information extraction and RAG duties. Nonetheless, solely Gemini fashions at present have the context size essential to carry out the operate calling process over all attainable capabilities. In the meantime, Llama 3.1 405B outperformed all different fashions on the operate calling as retrieval process.
Small fashions have been surprisingly sturdy performers: they largely carried out equally to their bigger counterparts, and generally considerably outperformed them. The one notable degradation was between o1-preview and o1-mini on the FinanceBench process. That is attention-grabbing provided that, as we are able to see in Determine 3, o1-mini outperforms o1-preview on the opposite two enterprise RAG duties. This underscores the task-dependent nature of mannequin choice.
Open Supply vs. Closed Supply Fashions
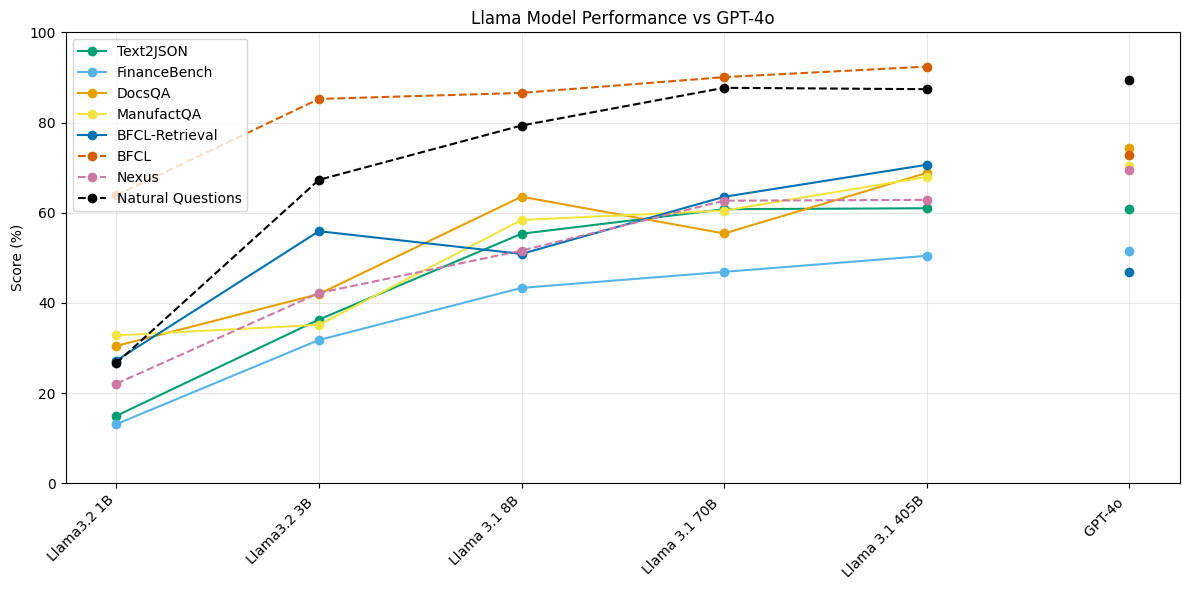
We evaluated 5 totally different Llama fashions, every at a unique measurement. In Determine 4, we plot the scores of every of those fashions on every of our benchmarks in opposition to GPT-4o’s scores for comparability. We discover that Llama 3.1 405B and Llama 3.1 70B carry out extraordinarily competitively on Text2JSON and Perform Calling duties as in comparison with closed-source fashions, surpassing or performing equally to GPT 4o. Nonetheless, the hole between these mannequin lessons is extra pronounced on RAG duties.
Moreover, we word that Llama 3.1 and three.2 collection of fashions present diminishing returns relating to mannequin scale and efficiency. The efficiency hole between Llama 3.1 405B and Llama 3.1 70B is negligible on the Text2JSON process, and considerably smaller on each different process than Llama 3.1 8B. Nonetheless, we observe that Llama 3.2 3B outperforms Llama 3.1 8B on the operate calling with retrieval process (BFCL-Retrieval in Determine 4).
This suggests two issues. First, open-source fashions are off-the-shelf viable for a minimum of two high-frequency enterprise use instances. Second, there’s room to enhance these fashions’ skill to leverage retrieved data.
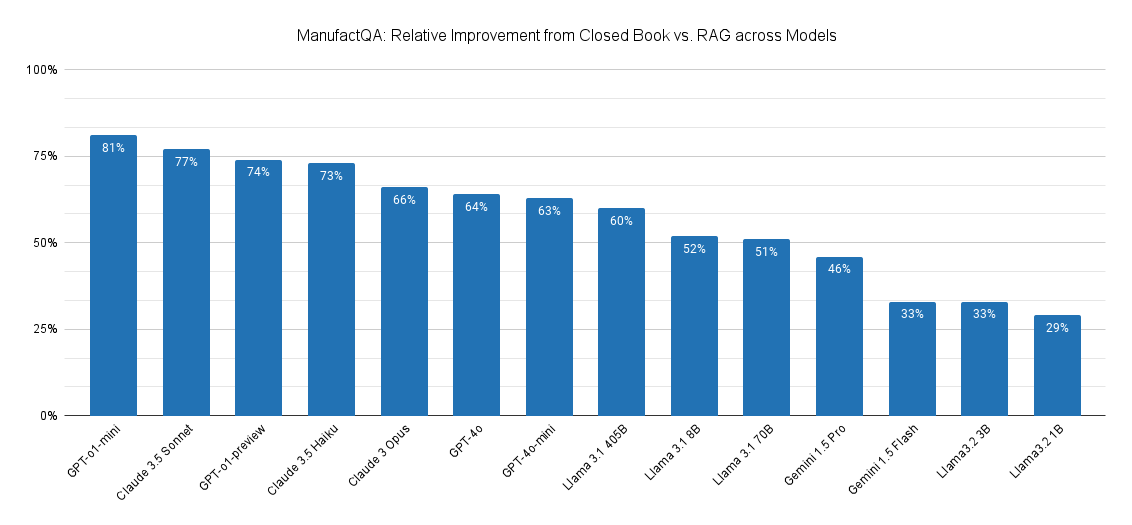
To additional examine this, we in contrast how significantly better every mannequin would carry out on ManufactQA below a closed guide setting vs. a default RAG setting. In a closed guide setting, fashions are requested to reply the queries with none given context – which measures a mannequin’s pretrained information. Within the default RAG setting, the LLM is supplied with the highest 10 paperwork retrieved by OpenAI’s text-embedding-3-large, which had a recall@10 of 81.97%. This represents essentially the most reasonable configuration in a RAG system. We then calculated the relative error discount between the rag and closed guide settings.
Based mostly on Determine 5, we observe that the GPT-o1-mini (surprisingly!) and Claude-3.5 Sonnet are capable of leverage retrieved context essentially the most, adopted by GPT-o1-preview and Claude 3.5 Haiku. The open supply Llama fashions and Gemini fashions all path behind, suggesting that these fashions have extra room to enhance in leveraging area particular context for RAG.
For operate calling at scale, prime quality retrieval could also be extra beneficial than bigger context home windows.
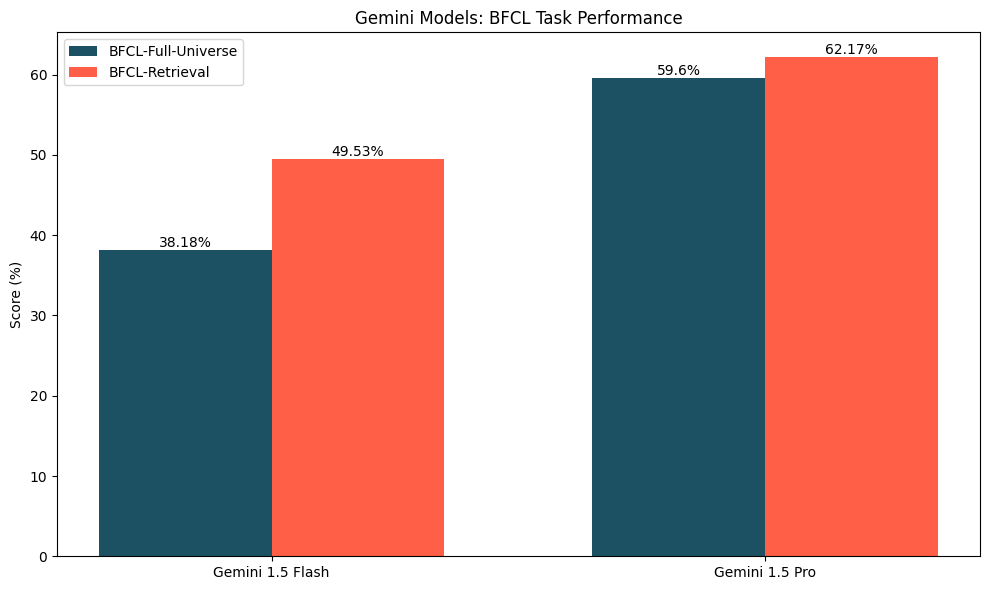
Our operate calling evaluations present one thing attention-grabbing: simply because a mannequin can match a complete set of capabilities into its context window doesn’t imply that it ought to. The one fashions able to doing this presently are Gemini 1.5 Flash and Gemini 1.5 Professional; as Determine 6 shows, these fashions carry out higher on the operate calling with retrieval variant, the place a retriever selects a subset of the complete set of capabilities related to the question. The advance in efficiency was extra exceptional for Gemini 1.5 Flash (~11% enchancment) than for Gemini 1.5 Professional (~2.5%). This enchancment seemingly stems from the fact {that a} well-tuned retriever can improve the probability that the right operate is within the context whereas vastly decreasing the variety of distractor capabilities current. Moreover, we’ve beforehand seen that fashions might battle with long-context duties for a wide range of causes.
Benchmark Overviews
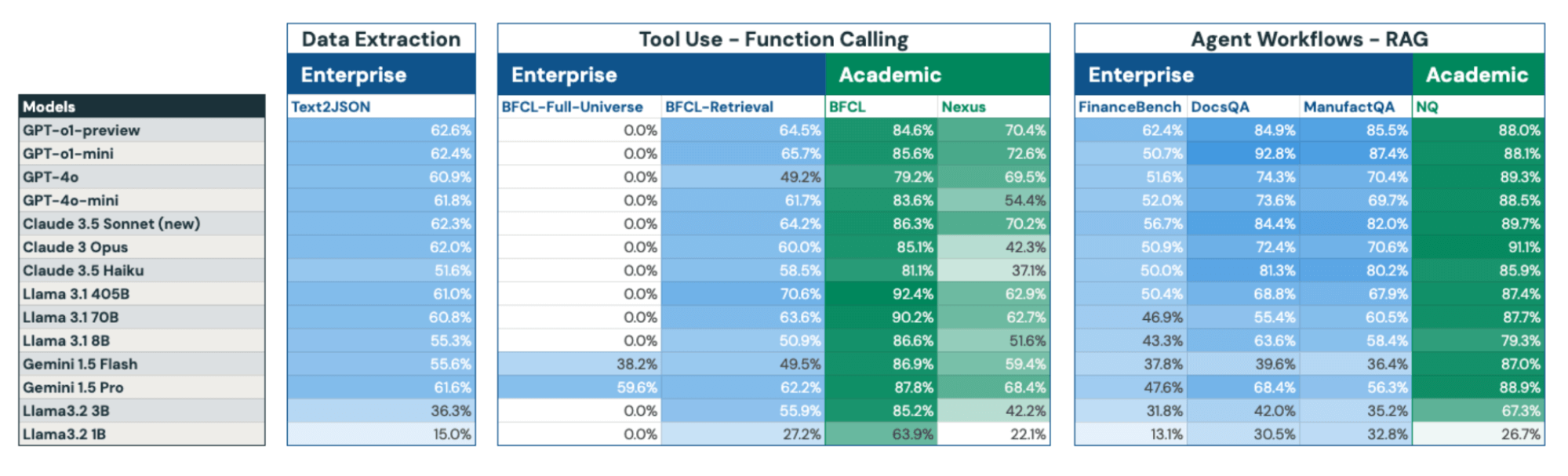
Having outlined DIBS’s construction and key findings, we current a complete abstract of fourteen open and closed-source fashions’ efficiency throughout our enterprise and tutorial benchmarks in Determine 7. Beneath, we offer detailed descriptions of every benchmark within the the rest of this part.
Knowledge Extraction: Textual content to JSON
In as we speak’s data-driven panorama, the power to rework huge quantities of unstructured information into actionable data has turn out to be more and more beneficial. A key problem many enterprises face is constructing unstructured information to structured information pipelines, both as standalone pipelines or as half of a bigger system.
One frequent variant we’ve seen within the area is changing unstructured textual content – usually a big corpus of paperwork – to JSON. Whereas this process shares similarities with conventional entity extraction and named entity recognition, it goes additional – usually requiring a classy mix of open-ended extraction, summarization, and synthesis capabilities.
No open-source tutorial benchmark sufficiently captures this complexity; we due to this fact procured human-written examples and created a customized Text2JSON benchmark. The examples we procured contain extracting and summarizing data from passages right into a specified JSON schema. We additionally consider multi-turn capabilities, e.g. enhancing present JSON outputs to include further fields and knowledge. To make sure our benchmark displays precise enterprise wants and gives a related evaluation of extraction capabilities, we used the identical analysis methods as our clients.
Instrument Use: Perform Calling
Instrument use capabilities allow LLMs to behave as half of a bigger compound AI system. We’ve seen sustained enterprise curiosity in operate calling as a instrument, and we beforehand wrote about the way to successfully consider operate calling capabilities.
Lately, organizations have taken to instrument calling at a a lot bigger scale. Whereas tutorial evaluations sometimes check fashions with small operate units—usually ten or fewer choices—real-world purposes continuously contain a whole bunch or 1000’s of accessible capabilities. In observe, this implies enterprise operate calling is much like needle-in-a-haystack check, with many distractor capabilities current throughout any given question.
To higher replicate these enterprise situations, we have tailored the established BFCL tutorial benchmark to judge each operate calling capabilities and the function of retrieval at scale. In its authentic model, the BFCL benchmark requires a mannequin to decide on one or fewer capabilities from a predefined set of 4 capabilities. We constructed on high of our earlier modification of the benchmark to create two variants: one which requires the mannequin to select from the complete set of capabilities that exist in BFCL for every question, and one which leverages a retriever to establish ten capabilities which might be the most certainly to be related.
Agent Workflows: Retrieval-Augmented Era
RAG makes it attainable for LLMs to work together with proprietary paperwork, augmenting present LLMs with area intelligence. In our expertise, RAG is without doubt one of the hottest methods to customise LLMs in observe. RAG techniques are additionally important for enterprise brokers, as a result of any such agent should be taught to function throughout the context of the actual group during which it’s being deployed.
Whereas the variations between business and tutorial datasets are nuanced, their implications for RAG system design are substantial. Design decisions that seem optimum based mostly on tutorial benchmarks might show suboptimal when utilized to real-world business information. Which means that architects of commercial RAG techniques should fastidiously validate their design selections in opposition to their particular use case, relatively than relying solely on tutorial efficiency metrics.
Pure Questions stays a preferred tutorial benchmark whilst others, comparable to HotpotQA have fallen out of favor. Each of those datasets take care of Wikipedia-based query answering. In observe, LLMs have listed a lot of this data already. For extra reasonable enterprise settings, we use FinanceBench and DocsQA – as mentioned in our earlier explorations on lengthy context RAG – in addition to ManufactQA, an artificial RAG dataset simulating technical buyer assist interactions with product manuals, designed for manufacturing corporations’ use instances.
Conclusion
To find out whether or not tutorial benchmarks may sufficiently inform duties referring to area intelligence, we evaluated a complete of fourteen fashions throughout 9 duties. We developed a area intelligence benchmark suite comprising six enterprise benchmarks that signify: information extraction (textual content to JSON), instrument use (operate calling), and agentic workflows (RAG). We chosen fashions to judge based mostly on buyer curiosity in utilizing them for his or her AI/ML wants; we moreover evaluated the Llama 3.2 fashions for extra datapoints on the consequences of mannequin measurement.
Our findings present that counting on tutorial benchmarks to make selections about enterprise duties could also be inadequate. These benchmarks are overly saturated – hiding true mannequin capabilities – and considerably misaligned with enterprise wants. Moreover, the sphere of fashions is muddied: there are a number of fashions which might be usually sturdy performers, and fashions which might be unexpectedly succesful at particular duties. Lastly, tutorial benchmark efficiency might lead one to imagine that fashions are sufficiently succesful; in actuality, there should still be room for enchancment in the direction of being production-workload prepared.
At Databricks, we’re persevering with to assist our clients by investing assets into extra complete enterprise benchmarking techniques, and in the direction of growing refined approaches to area experience. As a part of this, we’re actively working with corporations to make sure we seize a broad spectrum of enterprise-relevant wants, and welcome collaborations. If you’re an organization seeking to create domain-specific agentic evaluations, please check out our Agent Analysis Framework. If you’re a researcher fascinated about these efforts, think about making use of to work with us.