{kind=link}

We’re excited to announce that materialized views (MVs) and streaming tables (STs) are actually Usually Accessible in Databricks SQL on AWS and Azure. Streaming tables supply easy, incremental ingestion from sources like cloud storage and message buses with only a few traces of SQL. Materialized views precompute and incrementally replace the outcomes of queries so your dashboards and queries can run considerably sooner than earlier than. Collectively, they can help you create environment friendly and scalable knowledge pipelines from ingestion to transformation utilizing simply SQL.
On this weblog, we’ll dive into how these instruments empower analysts and analytics engineers to ship knowledge and analytics functions extra successfully throughout the DBSQL warehouse. Plus, we’ll cowl new capabilities of MVs and STs that improve monitoring, error troubleshooting, and price monitoring.
Challenges confronted by knowledge warehouse customers
Knowledge warehouses are the first location for analytics and inner reporting by means of enterprise intelligence (BI) functions. SQL analysts should effectively ingest and rework massive knowledge units, guarantee quick question efficiency for real-time analytics, and handle the steadiness between fast knowledge entry and price controls. They face a number of challenges in reaching these targets:
- Sluggish end-user queries and dashboards: Massive BI dashboards course of advanced views of massive datasets, resulting in sluggish queries that hinder interactivity and improve prices attributable to repeated knowledge reprocessing.
- Bettering knowledge freshness whereas holding prices down: Precomputing outcomes can scale back question latency however usually results in stale knowledge and excessive prices, requiring advanced incremental processing to take care of contemporary knowledge at an affordable price.
- Self-service: Conventional SQL pipelines depend on advanced guide coding, slowing down responses to enterprise wants.
Materialized views and streaming tables offer you quick, contemporary knowledge
MVs and STs clear up these challenges by combining the convenience of views with the velocity of precomputed knowledge, because of the ability of computerized end-to-end incremental processing. This lets engineers ship quick queries with no need to put in writing advanced code, whereas making certain the information is as up-to-date because the enterprise requires.
Quick queries and dashboards with MVs
Materialized Views (MVs) improve the efficiency of SQL analytics and BI dashboards by pre-computing and storing question outcomes prematurely, considerably decreasing question latency. As an alternative of repeatedly querying the bottom tables, MVs enable dashboards and end-user queries to retrieve pre-aggregated or pre-joined knowledge, making them a lot sooner. Moreover, querying MVs is less expensive in comparison with views, as solely the information saved within the MV is accessed, avoiding the overhead of reprocessing the underlying base tables for each question.
Transfer to real-time use instances whereas holding prices low
STs and MVs work collectively to create absolutely incremental knowledge pipelines, excellent for real-time use instances. STs repeatedly ingest and course of streaming knowledge, making certain BI dashboards, machine studying fashions, and operational methods all the time have probably the most up-to-date data. MVs, alternatively, routinely refresh incrementally as new knowledge arrives, holding knowledge contemporary for customers with out guide enter, whereas additionally decreasing processing prices by avoiding full view rebuilds. Combining STs and MVs gives one of the best cost-performance steadiness for real-time analytics and reporting.
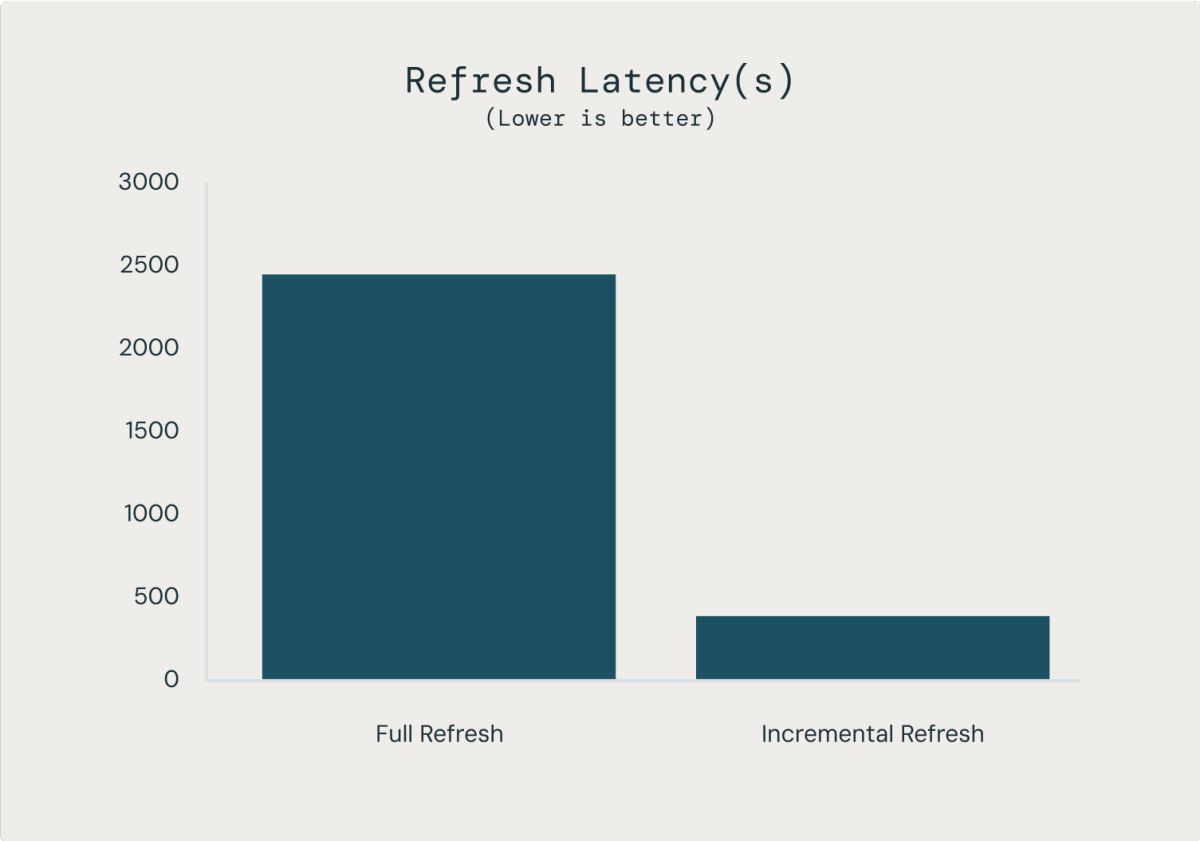
MVs with incremental refresh may save important money and time. In our inner benchmarks on a 200 billion-row desk, MV refreshes had been 98% cheaper and 85% sooner than refreshing the entire desk, leading to ~7x higher knowledge freshness at 1/fiftieth of the price of an identical CREATE TABLE AS assertion.
Empower your analysts to construct knowledge pipelines in DBSQL
Utilizing MVs and STs to develop knowledge pipelines automates a lot of the guide work concerned in managing tables and DML code, releasing analytics engineers to concentrate on enterprise logic and delivering better worth to the group with a easy SQL syntax. STs additional simplify knowledge ingestion from varied sources, like cloud storage and message buses, by eliminating the necessity for advanced configurations.
Using Materialized Views successfully on prime of transaction tables has resulted in a drastic enchancment in question efficiency on analytical layer, with the question time lowering as much as 85% on a 500 million truth desk. This allows our Enterprise group to eat analytical dashboards extra effectively and make faster choices primarily based on the insights gained from the information.
— Shiv Nayak / Head of Knowledge and AI Structure, EasyJet
We have considerably diminished the time wanted to deal with massive volumes utilizing Databricks materialized views. This enhancement has reduce our runtime by 85%, enabling our group to work extra effectively and concentrate on machine studying and enterprise intelligence insights. The simplified course of helps extra important knowledge volumes and contributes to general price financial savings and elevated mission agility.
— Sam Adams, Senior Machine Studying Engineer, Paylocity
“The conversion to Materialized Views has resulted in a drastic enchancment in question efficiency… Plus, the added price financial savings have actually helped.”
— Karthik Venkatesan, Safety Software program Engineering Sr. Supervisor, Adobe
“We’ve seen question performances enhance by 98% with a few of our tables which have a number of terabytes of knowledge.”
— Gal Doron, Head of Knowledge, AnyClip
“Using Materialized Views on prime of Transaction tables has drastically improved question efficiency on our analytical layer, with the execution time lowering as much as 85% on a 500 million truth desk.”
— Nikita Raje, Director Knowledge Engineering, DigiCert
Instance: Ingest and rework knowledge from a quantity in Databricks
A standard use case for STs and MVs is ingesting and reworking knowledge repeatedly because it arrives in a cloud storage bucket. The next instance reveals how you are able to do this completely in SQL with out the necessity for any exterior configuration or orchestration. We’ll create one streaming desk to land knowledge into the lakehouse, after which create a materialized view to rely the variety of rows ingested.
- Create ST to ingest knowledge from a quantity each 5 minutes. The streaming desk ensures exactly-once supply of latest knowledge. And since STs use serverless background compute for knowledge processing, they may routinely scale to deal with spikes in knowledge quantity.
CREATE OR REFRESH STREAMING TABLE my_bronze
REFRESH EVERY 5 minutes
AS
SELECT rely(distinct event_id)
FROM event_count from '/Volumes/bucket_name'- Create MV to rework knowledge each hour. The MV will all the time replicate the outcomes of the question it’s outlined with, and might be incrementally refreshed when attainable.
CREATE OR REPLACE MATERIALIZED VIEW my_silver
REFRESH EVERY 1 hour
AS
SELECT rely(distinct event_id) as event_count from my_bronzeNew capabilities
Because the preview launch, we’ve enhanced the Catalog Explorer for MVs and STs, enabling you to entry real-time standing and refresh schedules. Moreover, MVs now help the CREATE OR REPLACE performance, permitting in-place updates. MVs additionally supply expanded incremental refresh capabilities throughout a broader vary of queries, together with new help for internal joins, left joins, UNION ALL, and window features. Let’s dive deeper into these new options:
Observability
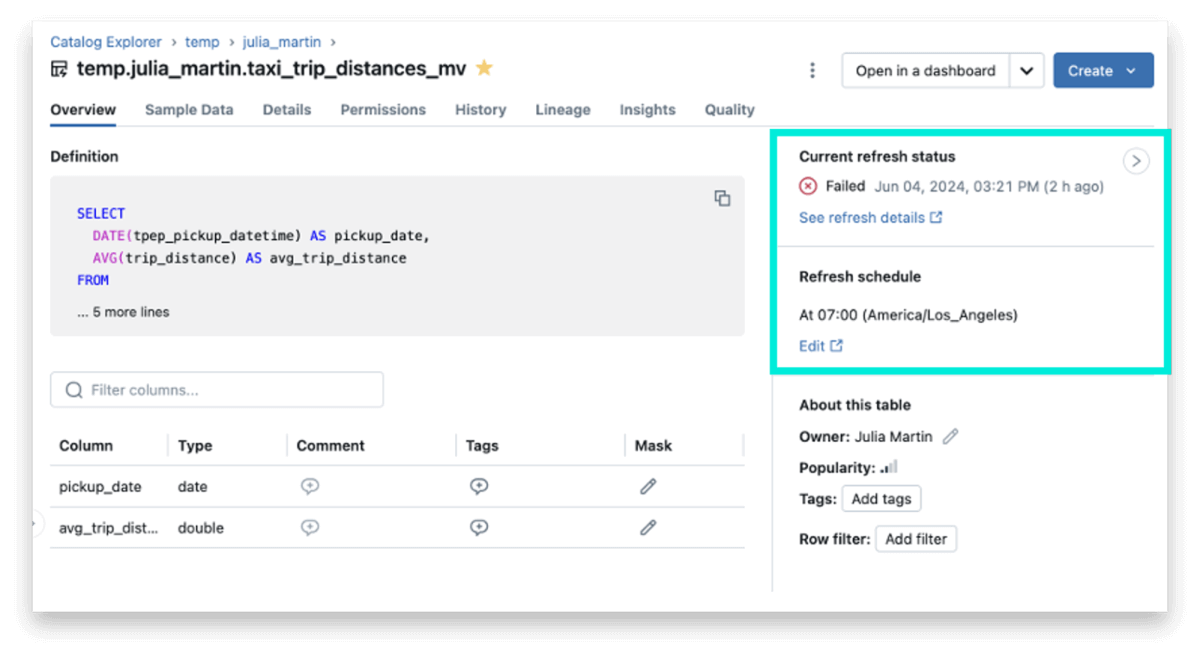
We’ve got enhanced the catalog explorer with contextual, real-time details about the standing and schedule of MVs and STs.
- Present refresh standing: Exhibits the precise time that the MV or ST was final refreshed. This can be a good sign for the way contemporary the information is.
- Refresh schedule: In case your materialized view is configured to refresh routinely on a time-based schedule, the catalog explorer now reveals the schedule in an easy-to-read format. This lets your finish customers simply see the freshness of the MV.
Simpler scheduling and administration
We’ve launched EVERY syntax for scheduling MV and ST refreshes utilizing DDL,. EVERY simplifies the configuration of time-based schedules with no need to put in writing CRON syntax. We’ll proceed to help CRON scheduling for customers that require the expressiveness of that syntax.
Instance:
CREATE OR REPLACE MATERIALIZED VIEW | STREAMING TABLE <identify>
SCHEDULE EVERY 1 HOUR|DAY|WEEK
AS... Moreover, we have added help for CREATE OR REPLACE for materialized views, enabling simpler updates to their definitions in-place with out the necessity to drop and recreate whereas preserving current permissions and ACLs.
Incrementally refresh left joins, internal joins, and window features
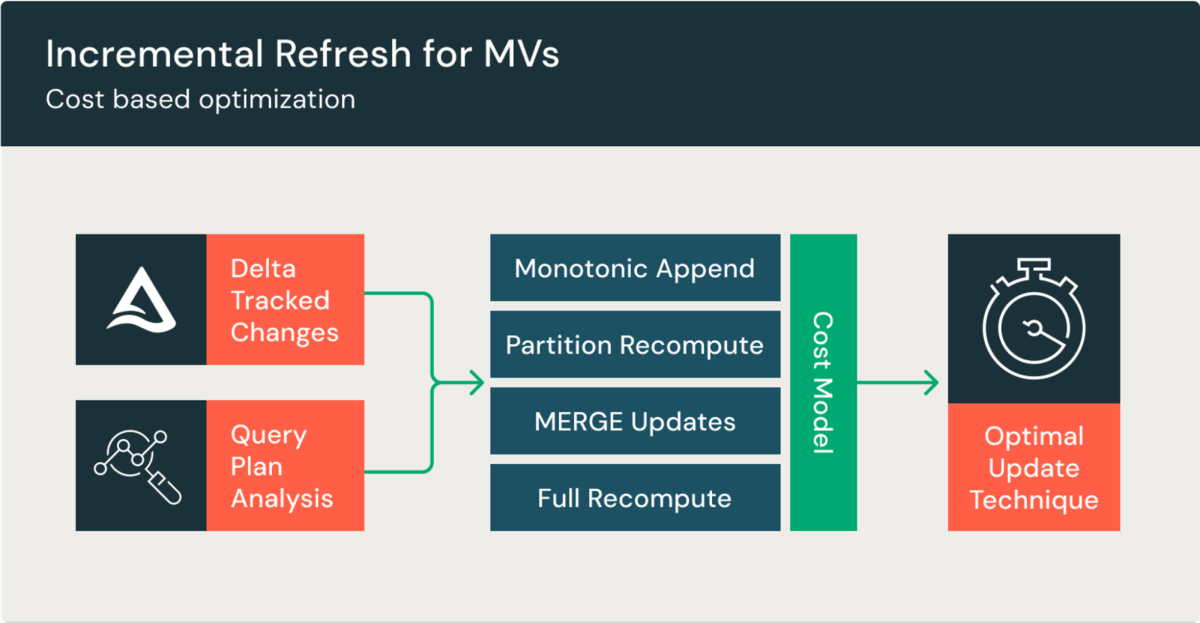
Recomputing massive MVs will be expensive and sluggish. MVs clear up this by incrementally computing updates, resulting in decrease prices and faster refreshes. This offers you improved knowledge freshness at a fraction of the price, whereas permitting your finish customers to question pre-computed knowledge. MVs are incrementally refreshed in DBSQL Professional and serverless warehouses, or Delta Stay Tables (DLT) pipelines.
MVs are routinely incrementally refreshed if their queries help it. If a question contains unsupported expressions, a full refresh might be performed as a substitute. An incremental refresh processes solely the modifications because the final replace, then provides or updates the information within the desk.
MVs help incremental refresh for internal joins, left joins, UNION ALL and window features (OVER). You may specify any variety of tables within the be part of, and updates to all tables within the be part of are mirrored within the outcomes of the question. We’re repeatedly including help for extra question sorts; please see the documentation for the newest capabilities.
Value attribution
You are actually capable of see id data for refreshes within the billable utilization system desk. To get this data, merely submit a question to the billable utilization system desk for data the place usage_metadata.dlt_pipeline_id is ready to the ID of the pipeline related to the materialized view or streaming desk. You’ll find the pipeline ID within the Particulars tab in Catalog Explorer when viewing the materialized view or streaming desk. For extra data, see our documentation.
The next question gives an instance:
SELECT sku_name, usage_date, identity_metadata, SUM(usage_quantity) AS `DBUs`
FROM
system.billing.utilization
WHERE
usage_metadata.dlt_pipeline_id = <pipeline_id>
GROUP BY ALL What’s coming for MVs and STs
MVs and STs are highly effective knowledge warehousing capabilities that construct on one of the best of knowledge warehousing in DBSQL. Over 1,400 clients are already utilizing them to energy incremental ingestion and refresh. We’re additionally very enthusiastic about how we’ll be making MVs and STs even higher within the close to future. Right here’s a preview of a few of these upcoming options:
- Refresh primarily based on upstream knowledge modifications. It is possible for you to to configure computerized refreshes primarily based on upstream knowledge modifications, whereas with the ability to handle prices by controlling how rapidly a refresh occurs after an replace.
- Modify proprietor and run as a service principal
- Capability to change MV and ST feedback straight within the Catalog Explorer.
- MV/ST consolidated monitoring within the UI. See your entire MVs and STs within the Databricks UI, so you may simply monitor well being and operational data for the whole workspace.
- Value monitoring. The MV and ST identify might be included within the billing methods desk so you may extra simply monitor DBU utilization, determine knowledge, and refresh historical past with no need to lookup the pipeline ID.
- Delta Sharing: Accessible now in non-public preview
- Google Cloud help: Coming quickly!
Get began with MVs and STs at the moment
To get began at the moment: