
| Mannequin | Recall | Precision | F1 Rating |
| Touchdown AI | 77.0% | 82.6% | 79.7% (highest) |
| Microsoft Florence-2 | 43.4% | 36.6% | 39.7% |
| Google OWLv2 | 81.0% | 29.5% | 43.2% |
| Alibaba Qwen2.5-VL-7B-Instruct | 26.0% | 54.0% | 35.1% |
4. Key Takeaways
- Touchdown AI’s Agentic Object Detection achieved the best F1 Rating (79.7%), which means it balances precision and recall higher than the others.
- Google OWLv2 had the best recall (81.0%), which means it detects probably the most objects however has decrease precision.
- Alibaba’s Qwen2.5-VL-7B-Instruct had comparatively low recall however reasonable precision.
- Microsoft Florence-2 confirmed decrease efficiency throughout all metrics in comparison with the opposite fashions.
Touchdown AI’s method appears to offer probably the most balanced and efficient efficiency in object detection duties, as mirrored in its highest F1 rating. The opposite fashions have trade-offs, with some excelling in recall however missing in precision, or vice versa.
Sensible Working of VisionAgent
VisionAgent follows a structured course of to offer outputs successfully:
- Add a picture you wish to analyze
- Write a immediate (e.g., “detect individuals with glasses”)
- Our AI agent analyzes the picture completely
- Obtain detection outcomes in your picture
1. Immediate: “Detect greens in and across the basket”
Step 1: Dialog
A consumer initiates a request, describing the imaginative and prescient activity in pure language. VisionAgent interprets this immediate and confirms the duty.
Enter Picture

Dialog
“I’ll assist you write code to detect greens in and across the basket within the picture. I’ll use object detection to establish varied greens within the scene.”
Step 2: Planner
I must first perceive what’s within the picture and get strategies on the right way to detect greens in and across the basket. I’ll begin by loading the picture and utilizing claude35_vqa and suggestion features.
Planning Steps
- Perceive the picture contents utilizing VQA (Visible Query Answering).
- Generate related strategies for one of the best detection method.
- Choose instruments that swimsuit the duty, comparable to object detection and color-based classification.
Instance Plan
- Determine all objects within the picture.
- Decide which objects are greens.
- Differentiate greens inside and out of doors the basket.
- Use a nested detection construction to research the spatial relationships.
Execution:
picture = load_image('vegetablebasket.jpg')
claude35_vqa('Are you able to describe this picture? What greens do you see in and across the basket?', [image])
suggestion('How can I detect greens in and across the basket on this picture?', [image])Remark
[claude35_vqa output]
This picture reveals a good looking array of recent greens organized round and in a wicker basket. The greens embody:
1. Recent carrots with inexperienced tops
2. Cauliflower
3. Onions
4. Potatoes
5. Broccoli
6. Eggplant
7. Pink tomatoes
8. Yellow squash/zucchini
9. Purple cabbage
10. Inexperienced bell pepper
11. Pink bell pepper
12. Cucumbers
13. Recent garlic
14. Recent herbs (seems to be parsley)
15. Inexperienced banana peppers or chili peppers
The greens look like very recent and vibrant in colour, organized on what seems to be like a picket floor or chopping board. The composition reveals a pleasant number of colours, from deep purples to vivid reds, oranges, and greens, making it visually interesting and suggesting a wholesome, nutritious choice of produce.
[end of claude35_vqa output]
[suggestions]
1. The greens are each in and round a basket, so relative_position would assist in figuring out their areas with respect to the basket as an anchor level.
2. nested_structure applies as a result of some greens are nested/contained throughout the basket whereas others are organized exterior it.
3. colour could be helpful for the reason that greens are distinctly coloured (pink tomatoes, orange carrots, inexperienced broccoli, purple cabbage, and so forth.), making colour a key identifier.
4. The issue doesn't contain small textual content, grid patterns, monitoring in video, evaluating sizes particularly, or coping with extraordinarily small objects in a big picture. The depth place is seen however not essential to the detection activity.
[suggestion 0]
It is advisable to discover the colour of objects within the picture, you need to use the next code to assist with this activity:
import numpy as np
import cv2
color_ranges = {
"red_lower": ((0, 100, 100), (int(179 * 20 / 360), 255, 255)),
"orange": ((int(179 * 21 / 360), 100, 100), (int(179 * 50 / 360), 255, 255)),
"yellow": ((int(179 * 51 / 360), 100, 100), (int(179 * 70 / 360), 255, 255)),
"inexperienced": ((int(179 * 71 / 360), 100, 100), (int(179 * 150 / 360), 255, 255)),
"cyan": ((int(179 * 151 / 360), 100, 100), (int(179 * 180 / 360), 255, 255)),
"blue": ((int(179 * 181 / 360), 100, 100), (int(179 * 265 / 360), 255, 255)),
"purple": ((int(179 * 266 / 360), 100, 100), (int(179 * 290 / 360), 255, 255)),
"pink": ((int(179 * 291 / 360), 100, 100), (int(179 * 330 / 360), 255, 255)),
"red_upper": ((int(179 * 331 / 360), 100, 100), (179, 255, 255)),
"white": ((0, 0, 200), (179, 25, 255)),
"grey": ((0, 0, 50), (179, 50, 200)),
"black": ((0, 0, 0), (179, 255, 30)),
}
def get_color(picture, color_ranges):
hsv_image = cv2.cvtColor(picture, cv2.COLOR_RGB2HSV)
detected_colors = {}
for colour, (decrease, higher) in color_ranges.gadgets():
upper_range = np.array(higher, dtype=np.uint8)
lower_range = np.array(decrease, dtype=np.uint8)
masks = cv2.inRange(hsv_image, lower_range, upper_range)
detected_pixels = cv2.countNonZero(masks)
detected_colors[color] = detected_pixels
if "red_lower" in detected_colors and "red_upper" in detected_colors:
detected_colors["red"] = detected_colors["red_lower"] + detected_colors["red_upper"]
del detected_colors["red_lower"]
del detected_colors["red_upper"]
return sorted(detected_colors, key=detected_colors.get, reverse=True)[0]
[end of suggestion 0]
[suggestion 1]
You are attempting to rely objects inside objects, or a nested construction. You may remedy this by first detecting the outer objects, then cropping the picture to the bounding field of every outer object and detecting the inside objects. You need to use the next code to assist with this activity:
all_dets = ("object", picture)
top, width = picture.form[:2]
def space(field):
return (field[2] - field[0]) * (field[3] - field[1])
# solely examine inside detections on high 25 largest outer detections
largest_dets = sorted(dets, key=lambda x: space(x["bbox"]), reverse=True)[:25]
for det in largest_dets:
x1 = int(det["bbox"][0] * width)
y1 = int(det["bbox"][1] * top)
x2 = int(det["bbox"][2] * width)
y2 = int(det["bbox"][3] * top)
crop = picture[y1:y2, x1:x2]
crop_height, crop_width = crop.form[:2]
inner_dets = ("object", crop)
for inner_det in inner_dets:
x1_inner = int(inner_det["bbox"][0] * crop_width)
y1_inner = int(inner_det["bbox"][1] * crop_height)
x2_inner = int(inner_det["bbox"][2] * crop_width)
y2_inner = int(inner_det["bbox"][3] * crop_height)
bbox = [
x1 + x1_inner,
y1 + y1_inner,
x1 + x2_inner,
y1 + y2_inner,
]
norm_bbox = [
bbox[0] / width,
bbox[1] / top,
bbox[2] / width,
bbox[3] / top,
]
all_dets.append(
{
"label": inner_det["label"],
"rating": inner_det["score"],
"bbox": norm_bbox,
}
)
[end of suggestion 1]
[suggestion 2]
You are attempting to find an objects relative to 'anchor' objects. The 'anchor' objects might be detected wonderful, however there are numerous of the opposite objects and also you solely wish to return those which are positioned relative to the 'anchor' objects as specified by the consumer. You need to use the next code to assist with this activity:
# First discover a mannequin that may detect the placement of the anchor objects
anchor_dets = ("anchor object", picture)
# Then discover a mannequin that may detect the placement of the relative objects
relative_dets = ("relative object", picture)
# This will provide you with relative objects 'above' the anchor objects since it is the
# distance between the decrease left nook of the relative object and the higher left
# nook of the anchor object. The remaining features can be utilized to get the opposite
# relative positions.
def above_distance(box1, box2):
return (box1["bbox"][0] - box2["bbox"][0]) ** 2 + (
box1["bbox"][3] - box2["bbox"][1]
) ** 2
def below_distance(box1, box2):
return (box1["bbox"][0] - box2["bbox"][0]) ** 2 + (
box1["bbox"][1] - box2["bbox"][3]
) ** 2
def right_distance(box1, box2):
return (box1["bbox"][0] - box2["bbox"][2]) ** 2 + (
box1["bbox"][1] - box2["bbox"][1]
) ** 2
def left_distance(box1, box2):
return (box1["bbox"][2] - box2["bbox"][0]) ** 2 + (
box1["bbox"][1] - box2["bbox"][1]
) ** 2
closest_boxes = []
for anchor_det in anchor_dets:
# You need to use any of the above features to get the relative place
distances = [
(relative_det, above_distance(relative_det, anchor_det))
for relative_det in relative_dets
]
# You need to seize the closest object for every of the anchors. This line will give
# you the field immediately above the anchor field (or under, left, proper relying on
# the operate used)
closest_box = min(distances, key=lambda x: x[1])[0]
closest_boxes.append(closest_box)
[end of suggestion 2]
[end of suggestions]
9 Step 3: Execution
The deliberate steps are executed utilizing the VisionAgent Library and Instruments Library. This includes loading the picture, working fashions, and producing detection outputs.
Planner
Based mostly on Claude’s description and the strategies, I must detect greens each in and across the basket. This can be a nested construction drawback the place I first must detect the basket after which detect greens in relation to it. Let me first get a instrument that may detect each the basket and greens.
Instance Execution Code
picture = load_image('vegetablebasket.jpg')
claude35_vqa('Are you able to describe this picture? What greens do you see in and across the basket?', [image])
suggestion('How can I detect greens in and across the basket on this picture?', [image])
get_tool_for_task('Detect basket and greens within the picture', [image])Remark and Closing Output
After execution, VisionAgent produces structured outcomes:
- Detected greens categorized inside and out of doors the basket.
- Bounding field coordinates for every detected vegetable.
- A deployable AI mannequin that can be utilized for real-world functions.
Output
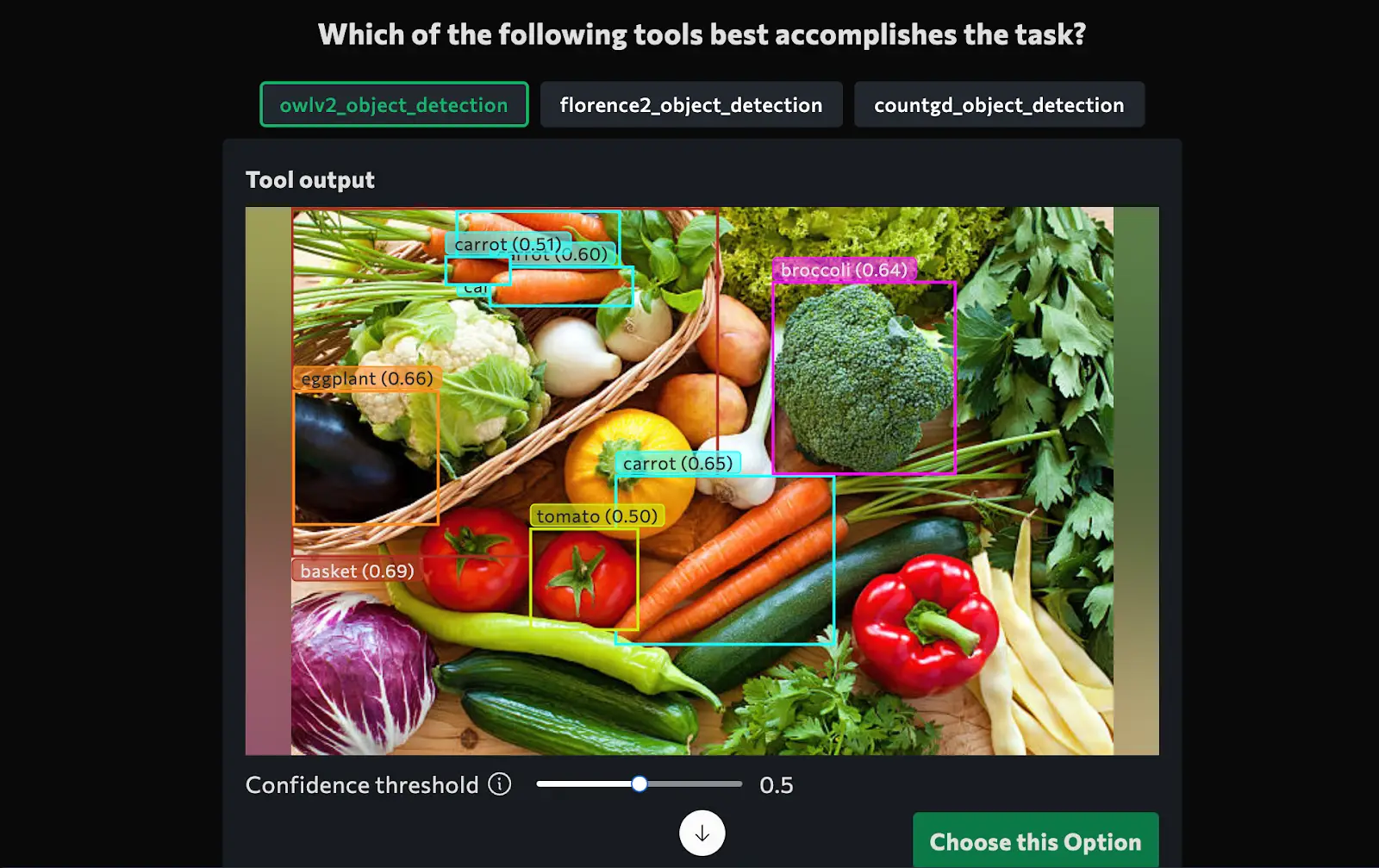
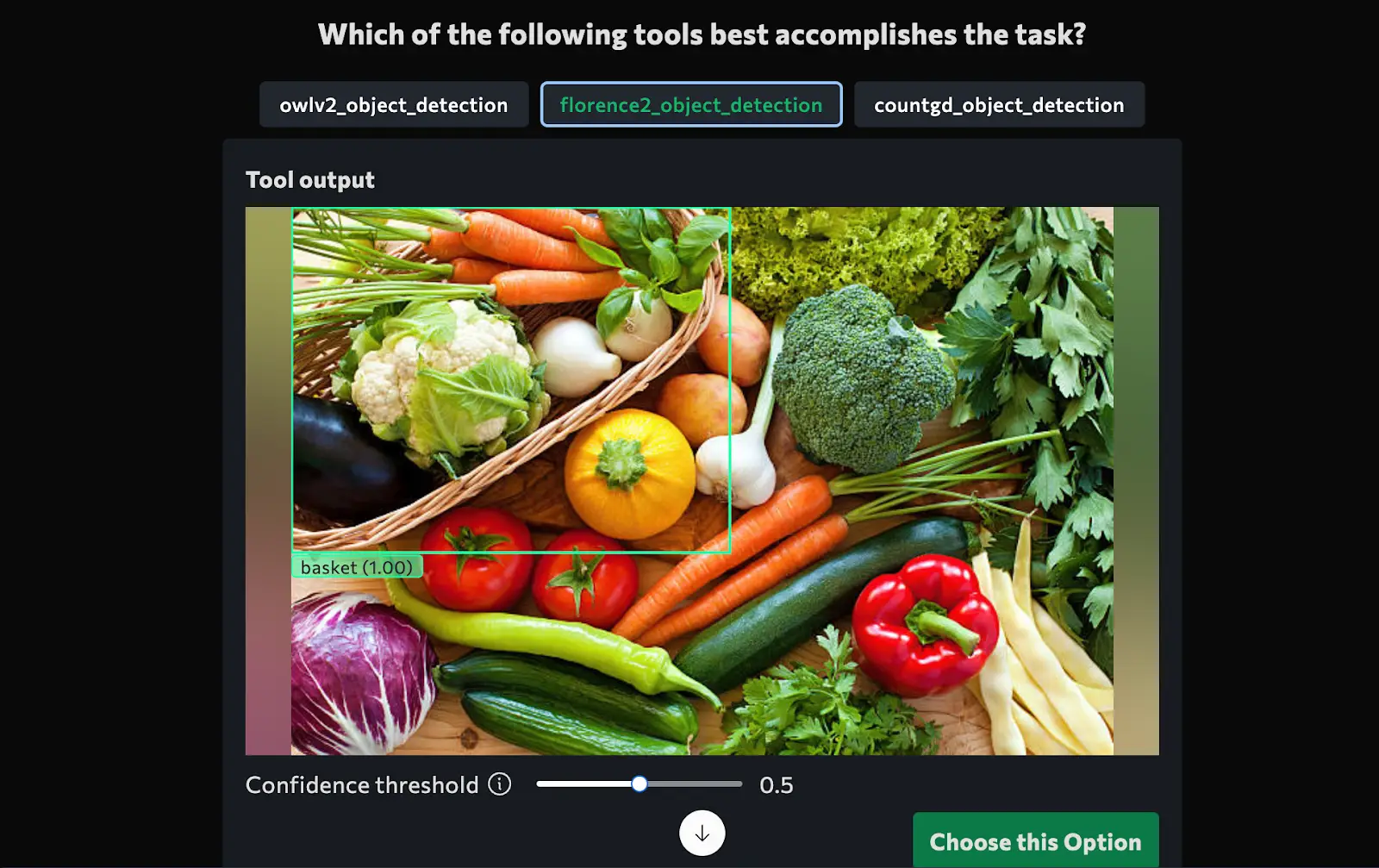
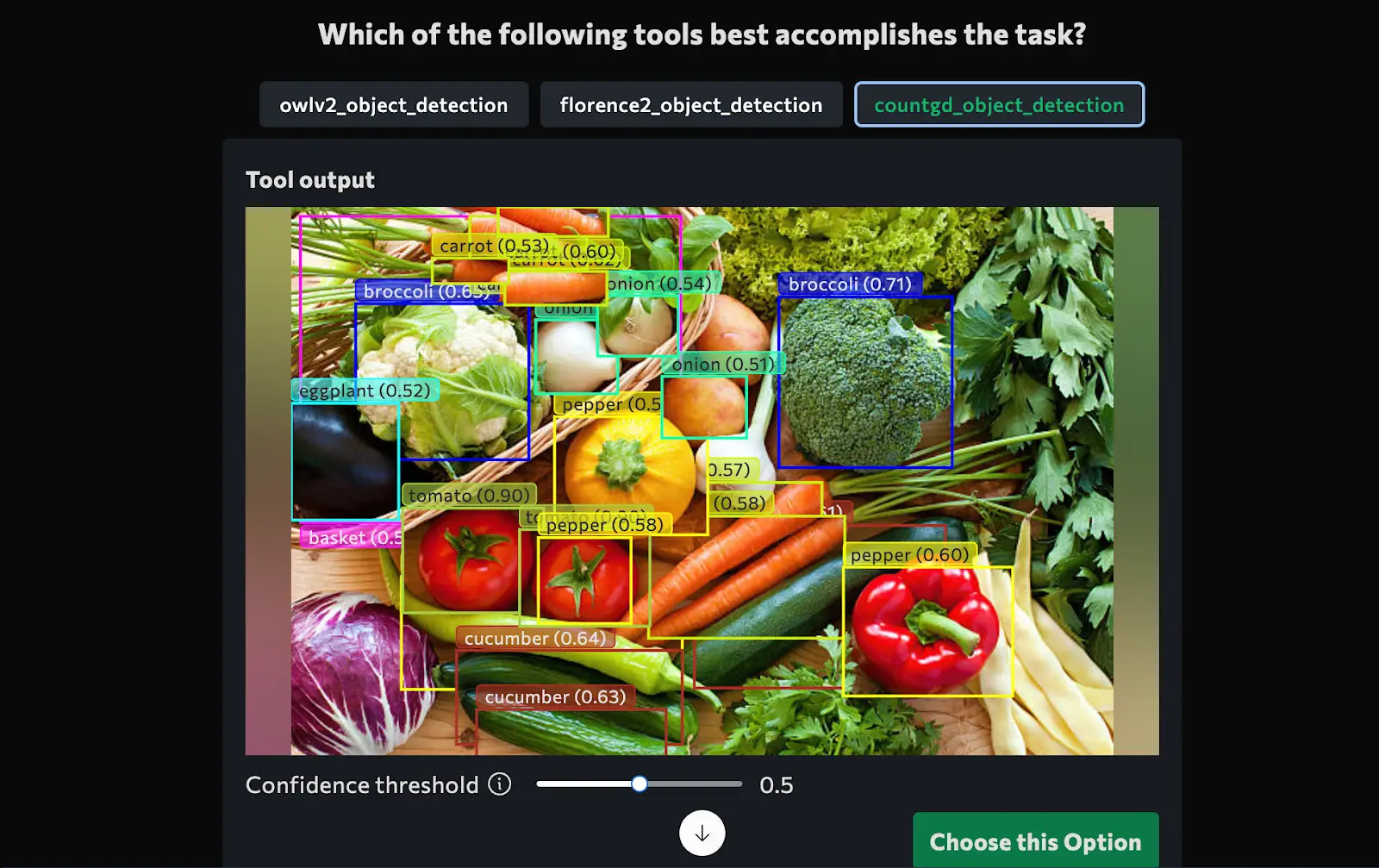
2. Immediate: “Determine pink automobile within the video”
Enter Video: Video Hyperlink
Step 1: Dialog
I’ll assist you write code to establish and observe pink automobiles within the video. I’ll use object detection and color-based filtering to perform this activity.
Step 2: Planner
I must first perceive what’s within the video and get strategies on the right way to establish a pink automobile. I’ll extract some frames and use claude35_vqa to explain the video content material, then get strategies.
Step 3: Execution
frames = extract_frames_and_timestamps('videoplayback(4).mp4', 1)
frames = [f["frame"] for f in frames]
claude35_vqa('Are you able to describe this video? Is there a pink automobile in it?', frames[:5])
suggestion('How can I establish the pink automobile within the video?', frames[:5])Remark
[claude35_vqa output]
Sure, there's a pink automobile (#21) on this video sequence, which seems to be a NASCAR race clip exhibiting an incident between two automobiles - a pink #21 automobile and a black/gold #3 automobile with Winchester branding. The video reveals them making contact round flip 4 of the observe, with the automobiles getting shut to one another and probably buying and selling paint. The sequence is labeled as "Josh Berry vs Austin Dillon" and reveals what seems to be a tense racing second between the 2 drivers. The textual content overlays point out "WOAH TURN 4", "CONTACT", "BERRY", "A LOT", and "THERE" because the sequence progresses.
[end of claude35_vqa output]
[suggestions]
Based mostly on the consumer's request to establish the pink automobile within the video and the offered video frames, that is primarily a case of:
1. finding_features_with_video_tracking - The sequence reveals a NASCAR race interplay between two automobiles (Josh Berry and Austin Dillon) the place monitoring the pink #21 automobile by the flip and speak to is vital
2. colour - The precise request mentions figuring out the "pink automobile", making colour identification related
3. relative_position - The interplay between the 2 automobiles requires understanding their positions relative to one another by the flip and speak to
The opposite classes do not apply as a result of:
- This is not about small textual content or giant photographs
- There aren't any grid patterns or lacking components
- This is not about evaluating sizes or nested buildings
- Whereas there may be some depth notion in racing, the request is not particularly about figuring out depth place
[suggestion 0]
It is advisable to discover the colour of objects within the picture, you need to use the next code to assist with this activity:
import numpy as np
import cv2
color_ranges = {
"red_lower": ((0, 100, 100), (int(179 * 20 / 360), 255, 255)),
"orange": ((int(179 * 21 / 360), 100, 100), (int(179 * 50 / 360), 255, 255)),
"yellow": ((int(179 * 51 / 360), 100, 100), (int(179 * 70 / 360), 255, 255)),
"inexperienced": ((int(179 * 71 / 360), 100, 100), (int(179 * 150 / 360), 255, 255)),
"cyan": ((int(179 * 151 / 360), 100, 100), (int(179 * 180 / 360), 255, 255)),
"blue": ((int(179 * 181 / 360), 100, 100), (int(179 * 265 / 360), 255, 255)),
"purple": ((int(179 * 266 / 360), 100, 100), (int(179 * 290 / 360), 255, 255)),
"pink": ((int(179 * 291 / 360), 100, 100), (int(179 * 330 / 360), 255, 255)),
"red_upper": ((int(179 * 331 / 360), 100, 100), (179, 255, 255)),
"white": ((0, 0, 200), (179, 25, 255)),
"grey": ((0, 0, 50), (179, 50, 200)),
"black": ((0, 0, 0), (179, 255, 30)),
}
def get_color(picture, color_ranges):
hsv_image = cv2.cvtColor(picture, cv2.COLOR_RGB2HSV)
detected_colors = {}
for colour, (decrease, higher) in color_ranges.gadgets():
upper_range = np.array(higher, dtype=np.uint8)
lower_range = np.array(decrease, dtype=np.uint8)
masks = cv2.inRange(hsv_image, lower_range, upper_range)
detected_pixels = cv2.countNonZero(masks)
detected_colors[color] = detected_pixels
if "red_lower" in detected_colors and "red_upper" in detected_colors:
detected_colors["red"] = detected_colors["red_lower"] + detected_colors["red_upper"]
del detected_colors["red_lower"]
del detected_colors["red_upper"]
return sorted(detected_colors, key=detected_colors.get, reverse=True)[0]
[end of suggestion 0]
[suggestion 1]
First attempt to remedy the issue utilizing a VQA instrument earlier than utilizing the monitoring method for a quicker and simpler resolution:
reply = ("", picture)
If that doesn't work, you may observe the objects within the video after which establish options on these objects. It is advisable to first get a instrument that may observe objects in a video, after which for every object discover one other instrument to establish the options on the article. You need to use the next code to assist with this activity:
track_predictions = Planner
Based mostly on Claude’s description and the strategies, I would like to trace automobiles within the video and establish the pink one. Let me first get a instrument for monitoring automobiles within the video.
Execution
get_tool_for_task('Observe automobiles in a NASCAR race video', frames[:5])Output
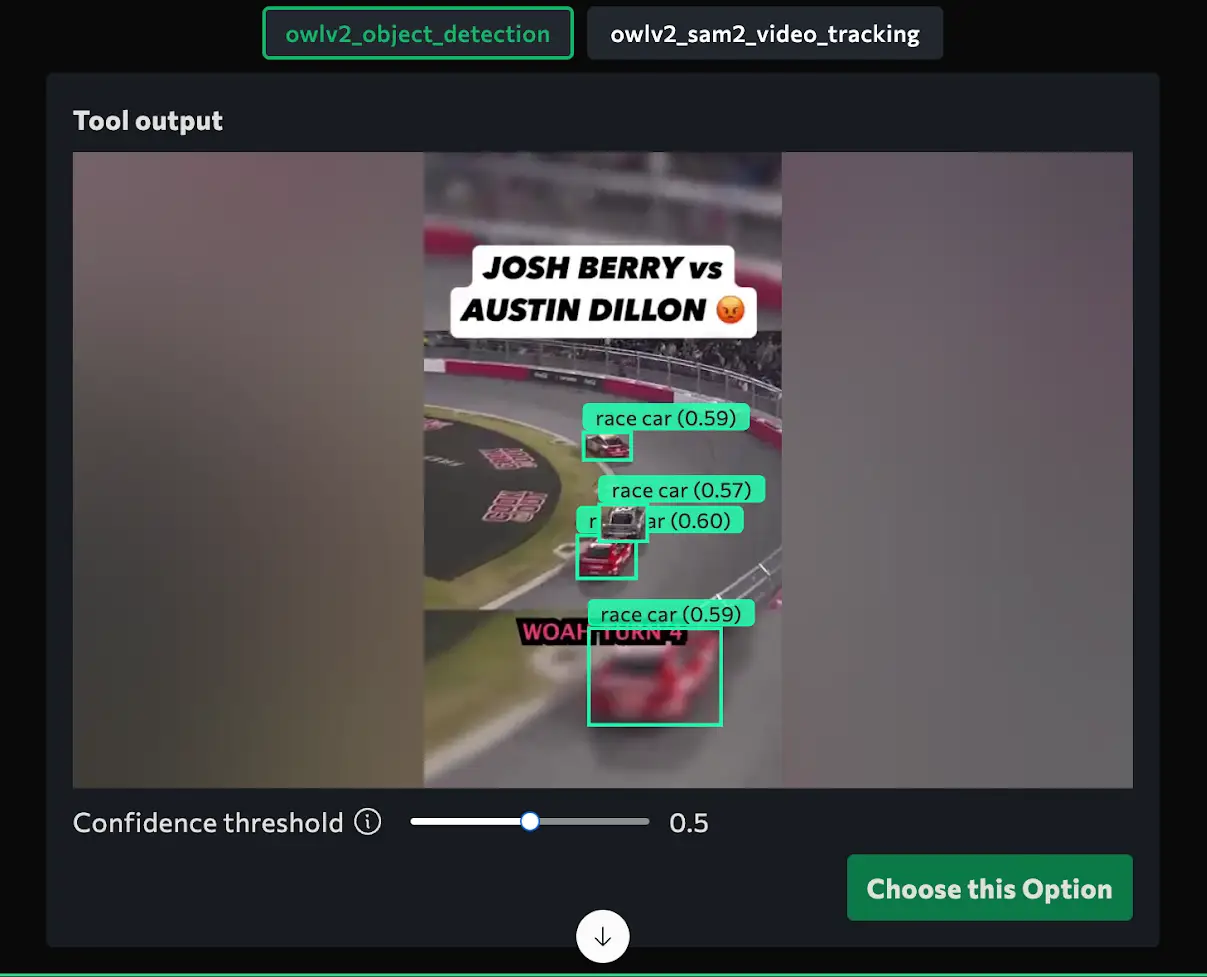
Conclusion
VisionAgent is remodeling the way in which builders construct, take a look at, and deploy AI-driven imaginative and prescient functions. By automating tedious processes and offering ready-to-use instruments, it considerably reduces improvement time whereas guaranteeing high-quality outcomes. Whether or not you might be an AI researcher, a developer, or a enterprise trying to implement pc imaginative and prescient options, VisionAgent supplies a quick, versatile, and scalable method to obtain your objectives.
With ongoing developments in AI, VisionAgent is predicted to evolve additional, incorporating even extra highly effective fashions and increasing its ecosystem to assist a wider vary of functions. Now could be the proper time to discover how VisionAgent can improve your AI-driven imaginative and prescient tasks.
Hello, I’m Pankaj Singh Negi – Senior Content material Editor | Keen about storytelling and crafting compelling narratives that remodel concepts into impactful content material. I really like studying about expertise revolutionizing our life-style.

