{kind=link}

Developments in multimodal intelligence rely upon processing and understanding photographs and movies. Photographs can reveal static scenes by offering info relating to particulars similar to objects, textual content, and spatial relationships. Nevertheless, this comes at the price of being extraordinarily difficult. Video comprehension includes monitoring adjustments over time, amongst different operations, whereas making certain consistency throughout frames, requiring dynamic content material administration and temporal relationships. These duties grow to be more durable as a result of the gathering and annotation of video-text datasets are comparatively tough in comparison with the image-text dataset.
Conventional strategies for multimodal massive language fashions (MLLMs) face challenges in video understanding. Approaches like sparsely sampled frames, primary connectors, and image-based encoders fail to successfully seize temporal dependencies and dynamic content material. Methods similar to token compression and prolonged context home windows battle with long-form video complexity, whereas integrating audio and visible inputs typically lacks seamless interplay. Efforts in real-time processing and scaling mannequin sizes stay inefficient, and present architectures should not optimized for dealing with lengthy video duties.
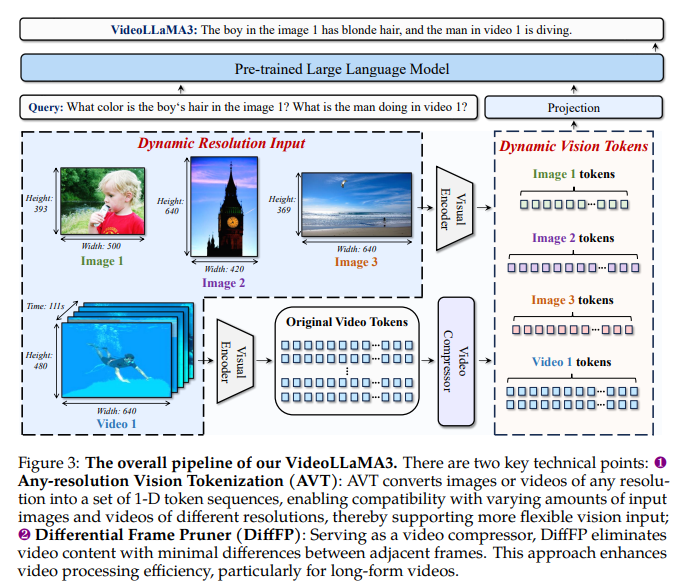
To deal with video understanding challenges, researchers from Alibaba Group proposed the VideoLLaMA3 framework. This framework incorporates Any-resolution Imaginative and prescient Tokenization (AVT) and Differential Body Pruner (DiffFP). AVT improves upon conventional fixed-resolution tokenization by enabling imaginative and prescient encoders to course of variable resolutions dynamically, decreasing info loss. That is achieved by adapting ViT-based encoders with 2D-RoPE for versatile place embedding. To protect important info, DiffFP offers with redundant and lengthy video tokens by pruning frames with minimal variations as taken by way of a 1-norm distance between the patches. Dynamic decision dealing with, together with environment friendly token discount, improves the illustration whereas decreasing the prices.
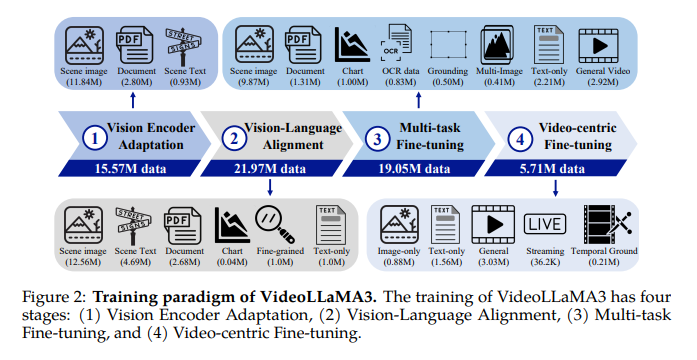
The mannequin consists of a imaginative and prescient encoder, video compressor, projector, and massive language mannequin (LLM), initializing the imaginative and prescient encoder utilizing a pre-trained SigLIP mannequin. It extracts visible tokens, whereas the video compressor reduces video token illustration. The projector connects the imaginative and prescient encoder to the LLM, and Qwen2.5 fashions are used for the LLM. Coaching happens in 4 phases: Imaginative and prescient Encoder Adaptation, Imaginative and prescient-Language Alignment, Multi-task Tremendous-tuning, and Video-centric Tremendous-tuning. The primary three phases concentrate on picture understanding, and the ultimate stage enhances video understanding by incorporating temporal info. The Imaginative and prescient Encoder Adaptation Stage focuses on fine-tuning the imaginative and prescient encoder, initialized with SigLIP, on a large-scale picture dataset, permitting it to course of photographs at various resolutions. The Imaginative and prescient-Language Alignment Stage introduces multimodal data, making the LLM and the imaginative and prescient encoder trainable to combine imaginative and prescient and language understanding. Within the Multi-task Tremendous-tuning Stage, instruction fine-tuning is carried out utilizing multimodal question-answering knowledge, together with picture and video questions, bettering the mannequin’s potential to comply with pure language directions and course of temporal info. The Video-centric Tremendous-tuning Stage unfreezes all parameters to boost the mannequin’s video understanding capabilities. The coaching knowledge comes from numerous sources like scene photographs, paperwork, charts, fine-grained photographs, and video knowledge, making certain complete multimodal understanding.
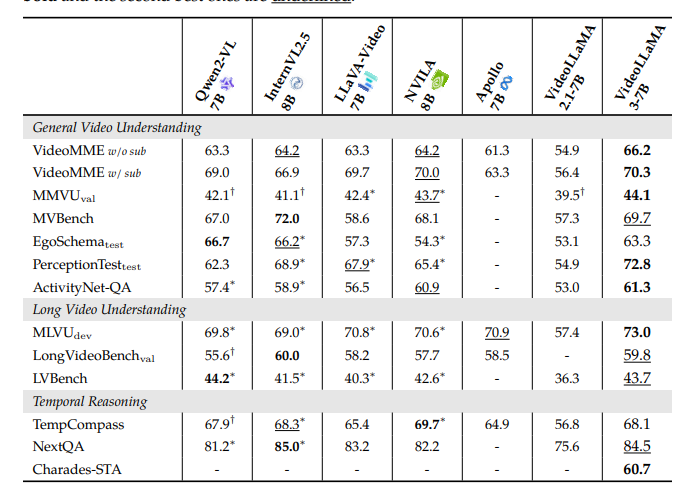
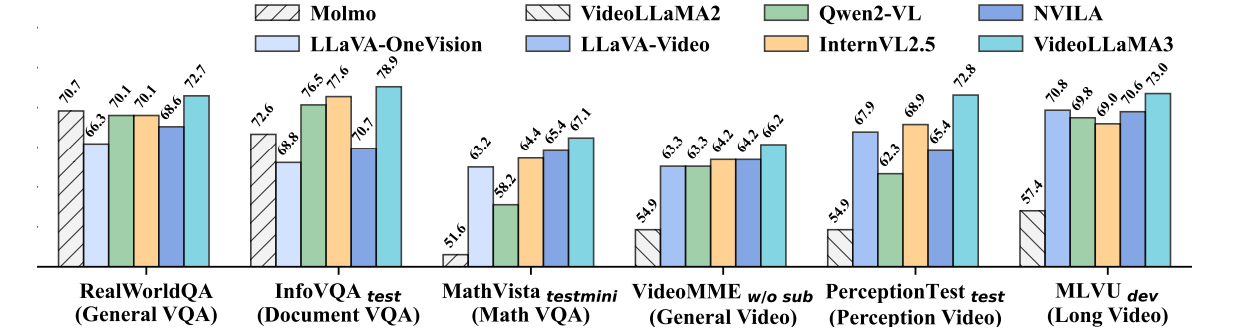
Researchers performed experiments to judge the efficiency of VideoLLaMA3 throughout picture and video duties. For image-based duties, the mannequin was examined on doc understanding, mathematical reasoning, and multi-image understanding, the place it outperformed earlier fashions, displaying enhancements in chart understanding and real-world data query answering (QA). In video-based duties, VideoLLaMA3 carried out strongly in benchmarks like VideoMME and MVBench, proving proficient typically video understanding, long-form video comprehension, and temporal reasoning. The 2B and 7B fashions carried out very competitively, with the 7B mannequin main in most video duties, which underlines the mannequin’s effectiveness in multimodal duties. Different areas the place essential enhancements had been reported had been OCR, mathematical reasoning, multi-image understanding, and long-term video comprehension.
Eventually, the proposed framework advances vision-centric multimodal fashions, providing a powerful framework for understanding photographs and movies. By using high-quality image-text datasets it addresses video comprehension challenges and temporal dynamics, reaching sturdy outcomes throughout benchmarks. Nevertheless, challenges like video-text dataset high quality and real-time processing stay. Future analysis can improve video-text datasets, optimize for real-time efficiency, and combine extra modalities like audio and speech. This work can function a baseline for future developments in multimodal understanding, bettering effectivity, generalization, and integration.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 70k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and remedy challenges.