{kind=link}

Medprompt, a run-time steering technique, demonstrates the potential of guiding general-purpose LLMs to realize state-of-the-art efficiency in specialised domains like drugs. By using structured, multi-step prompting methods reminiscent of chain-of-thought (CoT) reasoning, curated few-shot examples, and choice-shuffle ensembling, Medprompt bridges the hole between generalist and domain-specific fashions. This strategy considerably enhances efficiency on medical benchmarks like MedQA, attaining almost a 50% discount in error charges with out mannequin fine-tuning. OpenAI’s o1-preview mannequin additional exemplifies developments in LLM design by incorporating run-time reasoning to refine outputs dynamically, shifting past conventional CoT methods for tackling complicated duties.
Traditionally, domain-specific pretraining was important for top efficiency in specialist areas, as seen in fashions like PubMedBERT and BioGPT. Nonetheless, the rise of enormous generalist fashions like GPT-4 has shifted this paradigm, with such fashions surpassing domain-specific counterparts on duties just like the USMLE. Methods like Medprompt improve generalist mannequin efficiency by integrating dynamic prompting strategies, enabling fashions like GPT-4 to realize superior outcomes on medical benchmarks. Regardless of developments in fine-tuned medical fashions like Med-PaLM and Med-Gemini, generalist approaches with refined inference-time methods, exemplified by Medprompt and o1-preview, supply scalable and efficient options for high-stakes domains.
Microsoft and OpenAI researchers evaluated the o1-preview mannequin, representing a shift in AI design by incorporating CoT reasoning throughout coaching. This “reasoning-native” strategy permits step-by-step problem-solving at inference, lowering reliance on immediate engineering methods like Medprompt. Their research discovered that o1-preview outperformed GPT-4, even with Medprompt, throughout medical benchmarks, and few-shot prompting hindered its efficiency, suggesting in-context studying is much less efficient for such fashions. Though resource-intensive methods like ensembling stay viable, o1-preview achieves state-of-the-art outcomes at a better value. These findings spotlight a necessity for brand new benchmarks to problem reasoning-native fashions and refine inference-time optimization.
Medprompt is a framework designed to optimize general-purpose fashions like GPT-4 for specialised domains reminiscent of drugs by combining dynamic few-shot prompting, CoT reasoning, and ensembling. It dynamically selects related examples, employs CoT for step-by-step reasoning, and enhances accuracy by majority-vote ensembling of a number of mannequin runs. Metareasoning methods information computational useful resource allocation throughout inference, whereas exterior useful resource integration, like Retrieval-Augmented Era (RAG), ensures real-time entry to related data. Superior prompting methods and iterative reasoning frameworks, reminiscent of Self-Taught Reasoner (STaR), additional refine mannequin outputs, emphasizing inference-time scaling over pre-training. Multi-agent orchestration provides collaborative options for complicated duties.
The research evaluates the o1-preview mannequin on medical benchmarks, evaluating its efficiency with GPT-4 fashions, together with Medprompt-enhanced methods. Accuracy, the first metric, is assessed on datasets like MedQA, MedMCQA, MMLU, NCLEX, and JMLE-2024, in addition to USMLE preparatory supplies. Outcomes present that o1-preview usually surpasses GPT-4, excelling in reasoning-intensive duties and multilingual instances like JMLE-2024. Prompting methods, notably ensembling, improve efficiency, although few-shot prompting can hinder it. o1-preview achieves excessive accuracy however incurs larger prices in comparison with GPT-4o, which provides a greater cost-performance stability. The research highlights tradeoffs between accuracy, worth, and prompting approaches in optimizing giant medical language fashions.
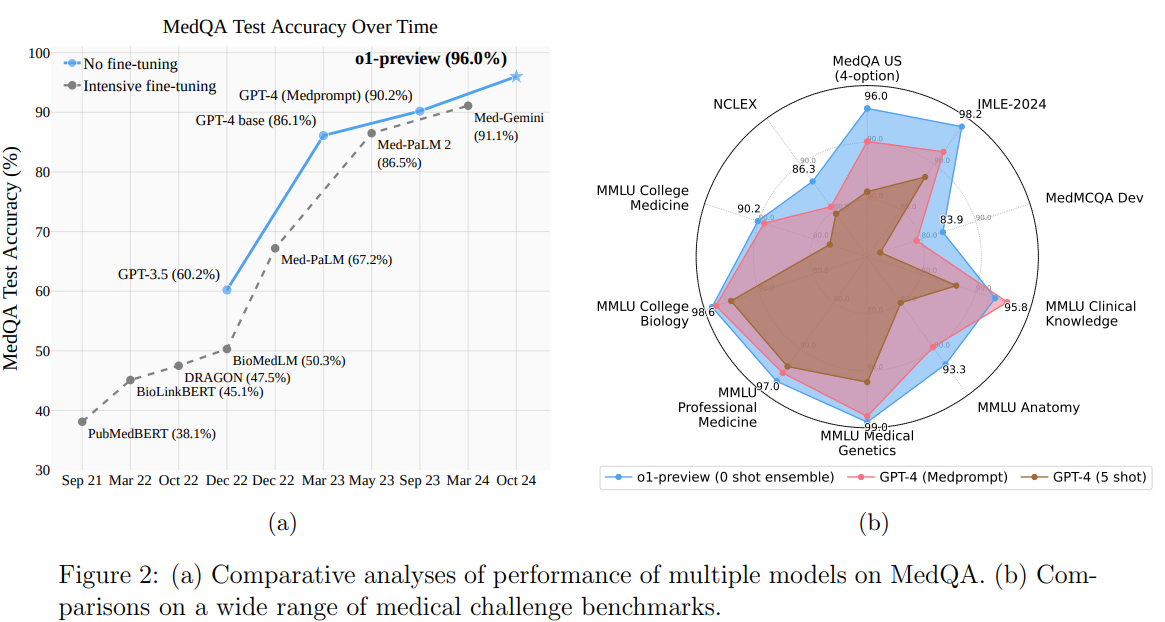
In conclusion, OpenAI’s o1-preview mannequin considerably advances LLM efficiency, attaining superior accuracy on medical benchmarks with out requiring complicated prompting methods. In contrast to GPT-4 with Medprompt, o1-preview minimizes reliance on methods like few-shot prompting, which generally negatively impacts efficiency. Though ensembling stays efficient, it calls for cautious cost-performance trade-offs. The mannequin establishes a brand new Pareto frontier, providing higher-quality outcomes, whereas GPT-4o supplies a extra cost-efficient various for sure duties. With o1-preview nearing saturation on current benchmarks, there’s a urgent want for tougher evaluations to additional discover its capabilities, particularly in real-world functions.
Take a look at the Particulars and Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Remodel proofs-of-concept into production-ready AI functions and brokers’ (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.