When individuals ask about the way forward for Generative AI in coding, what they
typically need to know is: Will there be a degree the place Massive Language Fashions can
autonomously generate and keep a working software program software? Will we
have the ability to simply writer a pure language specification, hit “generate” and
stroll away, and AI will have the ability to do all of the coding, testing and deployment
for us?
The principle purpose was to study AI’s capabilities. A Spring Boot
software just like the one in our setup can in all probability be written in 1-2 hours
by an skilled developer with a robust IDE, and we do not even bootstrap
issues that a lot in actual life. Nevertheless, it was an fascinating check case to
discover our important query: How may we push autonomy and repeatability of
AI code era?
The methods
We employed a set of “methods” one after the other to see if and the way they’ll
enhance the reliability of the era and high quality of the generated
code. All the methods had been used to enhance the likelihood that the
setup generates a working, examined and prime quality codebase with out human
intervention. They had been all makes an attempt to introduce extra management into the
era course of.
Selection of the tech stack
We selected a easy “CRUD” API backend (Create, Learn, Replace, Delete)
applied in Spring Boot because the purpose of the era.
As talked about earlier than, constructing an software like this can be a fairly
easy use case. The thought was to start out quite simple, after which if that
works, crank up the complexity or number of necessities.
How can this enhance the success charge?
The selection of Spring Boot because the goal stack was in itself our first
technique of accelerating the probabilities of success.
- A widespread tech stack that needs to be fairly prevalent within the coaching
information
- A runtime framework that may do loads of the heavy lifting, which suggests
much less code to generate for AI
- An software topology that has very clearly established patterns:
Controller -> Service -> Repository -> Entity, which signifies that it’s
comparatively simple to offer AI a set of patterns to observe
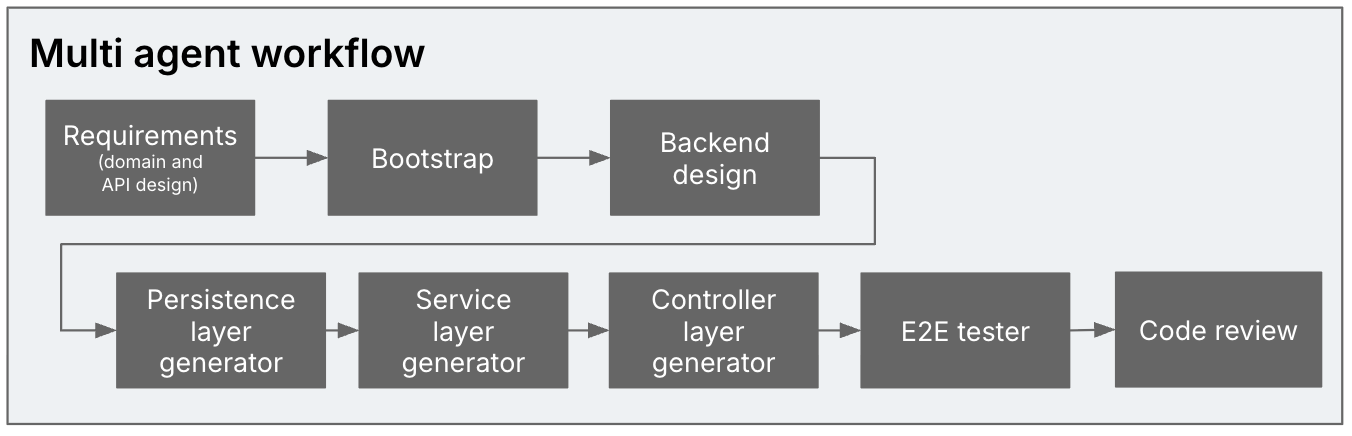
A number of brokers
We break up the era course of into a number of brokers. “Agent” right here
signifies that every of those steps is dealt with by a separate LLM session, with
a particular position and instruction set. We didn’t make another
configurations per step for now, e.g. we didn’t use completely different fashions for
completely different steps.
To not taint the outcomes with subpar coding skills, we used a setup
on prime of an current coding assistant that has a bunch of coding-specific
skills already: It could possibly learn and search a codebase, react to linting
errors, retry when it fails, and so forth. We would have liked one that may orchestrate
subtasks with their very own context window. The one one we had been conscious of on the time
that may do that’s Roo Code, and
its fork Kilo Code. We used the latter. This gave
us a facsimile of a multi-agent coding setup with out having to construct
one thing from scratch.
With a rigorously curated allow-list of terminal instructions, a human solely
must hit “approve” right here and there. We let it run within the background and
checked on it from time to time, and Kilo gave us a sound notification
at any time when it wanted enter or an approval.
How can this enhance the success charge?
Despite the fact that technically the context window sizes of LLMs are
rising, LLM era outcomes nonetheless develop into extra hit or miss the
longer a session turns into. Many coding assistants now provide the power to
compress the context intermittently, however a standard recommendation to coders utilizing
brokers remains to be that they need to restart coding classes as ceaselessly as
attainable.
Secondly, it’s a very established prompting observe is to assign
roles and views to LLMs to extend the standard of their outcomes.
We might reap the benefits of that as effectively with this separation into a number of
agentic steps.
Stack-specific over basic goal
As you possibly can perhaps already inform from the workflow and its separation
into the standard controller, service and persistence layers, we did not
draw back from utilizing methods and prompts particular to the Spring goal
stack.
How can this enhance the success charge?
One of many key issues individuals are enthusiastic about with Generative AI is
that it may be a basic goal code generator that may flip pure
language specs into code in any stack. Nevertheless, simply telling
an LLM to “write a Spring Boot software” shouldn’t be going to yield the
prime quality and contextual code you want in a real-world digital
product state of affairs with out additional directions (extra on that within the
outcomes part). So we wished to see how stack-specific our setup would
must develop into to make the outcomes prime quality and repeatable.
Use of deterministic scripts
For bootstrapping the appliance, we used a shell script moderately than
having the LLM do that. In any case, there’s a CLI to create an as much as
date, idiomatically structured Spring Boot software, so why would we
need AI to do that?
The bootstrapping step was the one one the place we used this system,
but it surely’s price remembering that an agentic workflow like this by no
means must be completely as much as AI, we will combine and match with “correct
software program” wherever acceptable.
Code examples in prompts
Utilizing instance code snippets for the varied patterns (Entity,
Repository, …) turned out to be the simplest technique to get AI
to generate the kind of code we wished.
How can this enhance the success charge?
Why do we’d like these code samples, why does it matter for our digital
merchandise and enterprise software software program lens?
The best instance from our experiment is the usage of libraries. For
instance, if not particularly prompted, we discovered that the LLM ceaselessly
makes use of javax.persistence, which has been outmoded by
jakarta.persistence. Extrapolate that instance to a big engineering
group that has a particular set of coding patterns, libraries, and
idioms that they need to use constantly throughout all their codebases.
Pattern code snippets are a really efficient approach to talk these
patterns to the LLM, and make sure that it makes use of them within the generated
code.
Additionally think about the use case of AI sustaining this software over time,
and never simply creating its first model. We might need it to be prepared to make use of
a brand new framework or new framework model as and when it turns into related, with out
having to attend for it to be dominant within the mannequin’s coaching information. We might
want a manner for the AI tooling to reliably decide up on these library nuances.
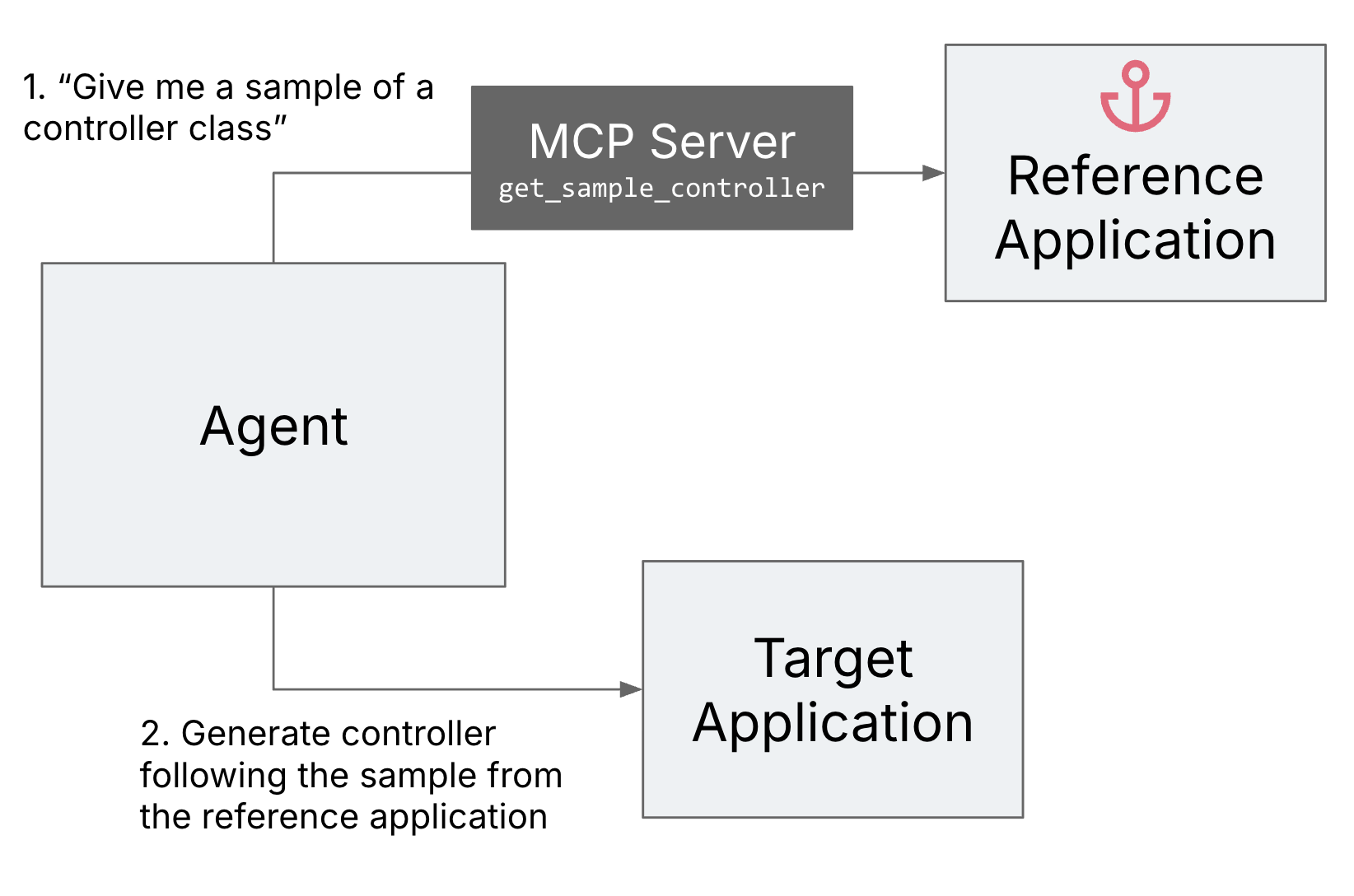
Reference software as an anchor
It turned out that sustaining the code examples within the pure
language prompts is sort of tedious. If you iterate on them, you do not
get rapid suggestions to see in case your pattern would truly compile, and
you additionally must be sure that all of the separate samples you present are
according to one another.
To enhance the developer expertise of the developer implementing the
agentic workflow, we arrange a reference software and an MCP (Mannequin
Context Protocol) server that may present the pattern code to the agent
from this reference software. This fashion we might simply be sure that
the samples compile and are according to one another.
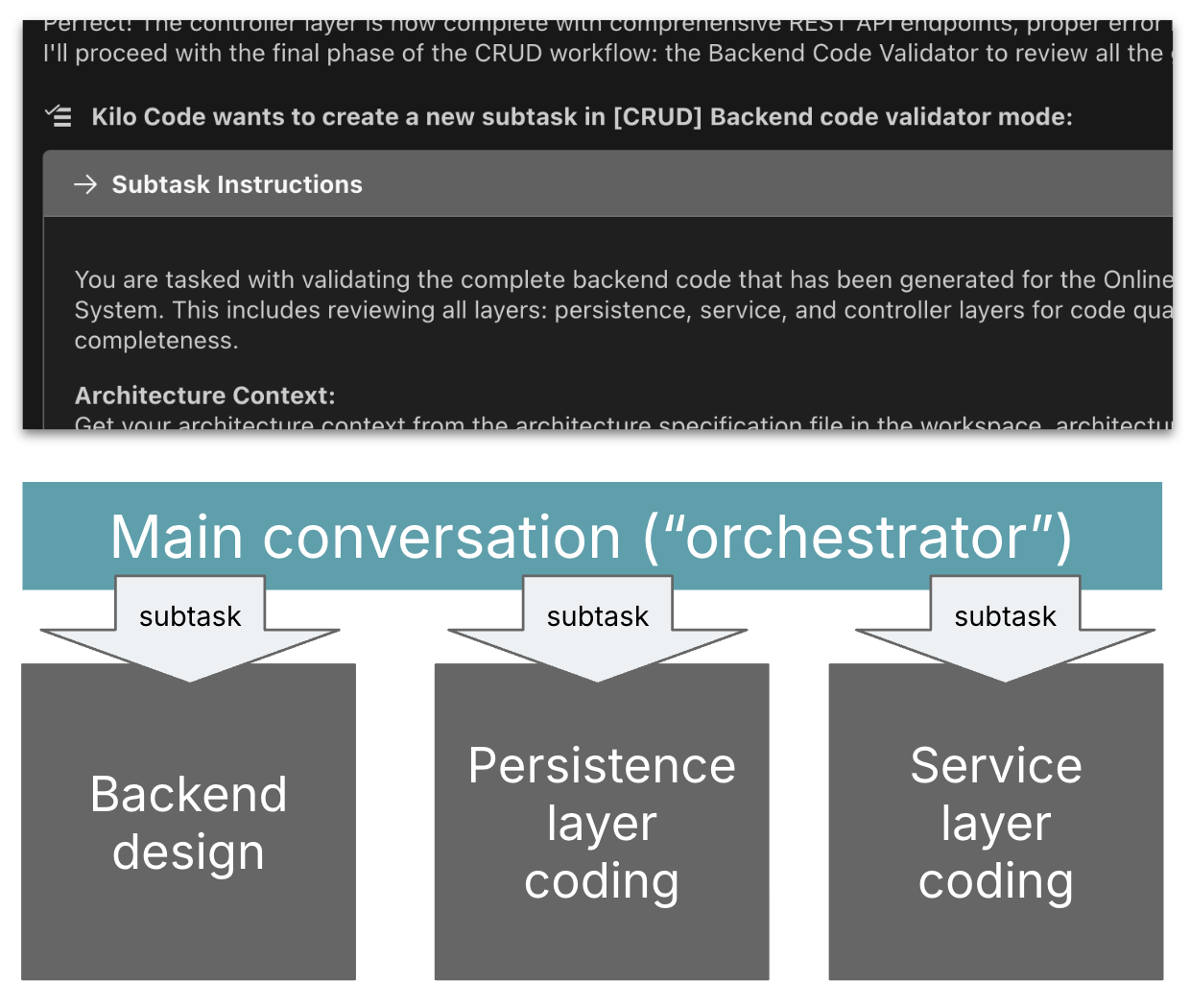
Generate-review loops
We launched a evaluation agent to double test AI’s work in opposition to the
unique prompts. This added a further security web to catch errors
and make sure the generated code adhered to the necessities and
directions.
How can this enhance the success charge?
In an LLM’s first era, it typically doesn’t observe all of the
directions accurately, particularly when there are loads of them.
Nevertheless, when requested to evaluation what it created, and the way it matches the
unique directions, it’s often fairly good at reasoning in regards to the
constancy of its work, and may repair a lot of its personal errors.
Codebase modularization
We requested the AI to divide the area into aggregates, and use these
to find out the package deal construction.
That is truly an instance of one thing that was laborious to get AI to
do with out human oversight and correction. It’s a idea that can also be
laborious for people to do effectively.
Here’s a immediate excerpt the place we ask AI to
group entities into aggregates throughout the necessities evaluation
step:
An combination is a cluster of area objects that may be handled as a
single unit, it should keep internally constant after every enterprise
operation.
For every combination:
- Title root and contained entities
- Clarify why this combination is sized the best way it's
(transaction dimension, concurrency, learn/write patterns).
We did not spend a lot effort on tuning these directions and so they can in all probability be improved,
however usually, it isn’t trivial to get AI to use an idea like this effectively.
How can this enhance the success charge?
There are a lot of advantages of code modularisation that
enhance the standard of the runtime, like efficiency of queries, or
transactionality issues. But it surely additionally has many advantages for
maintainability and extensibility – for each people and AI:
- Good modularisation limits the variety of locations the place a change must be
made, which suggests much less context for the LLM to remember throughout a change.
- You may re-apply an agentic workflow like this one to 1 module at a time,
limiting token utilization, and lowering the dimensions of a change set.
- Having the ability to clearly restrict an AI job’s context to particular code modules
opens up prospects to “freeze” all others, to cut back the prospect of
unintended adjustments. (We didn’t do this right here although.)
Outcomes
Spherical 1: 3-5 entities
For many of our iterations, we used domains like “Easy product catalog”
or “E-book monitoring in a library”, and edited down the area design carried out by the
necessities evaluation part to a most of 3-5 entities. The one logic in
the necessities had been a number of validations, aside from that we simply requested for
easy CRUD APIs.
We ran about 15 iterations of this class, with rising sophistication
of the prompts and setup. An iteration for the total workflow often took
about 25-Half-hour, and value $2-3 of Anthropic tokens ($4-5 with
“considering” enabled).
In the end, this setup might repeatedly generate a working software that
adopted most of our specs and conventions with hardly any human
intervention. It all the time bumped into some errors, however might ceaselessly repair its
personal errors itself.
Spherical 2: Pre-existing schema with 10 entities
To crank up the dimensions and complexity, we pointed the workflow at a
pared down current schema for a Buyer Relationship Administration
software (~10 entities), and likewise switched from in-memory H2 to
Postgres. Like in spherical 1, there have been a number of validation and enterprise
guidelines, however no logic past that, and we requested it to generate CRUD API
endpoints.
The workflow ran for 4–5 hours, with fairly a number of human
interventions in between.
As a second step, we supplied it with the total set of fields for the
important entity, requested it to develop it from 15 to 50 fields. This ran
one other 1 hour.
A sport of whac-a-mole
Total, we might positively see an enchancment as we had been making use of
extra of the methods. However in the end, even on this fairly managed
setup with very particular prompting and a comparatively easy goal
software, we nonetheless discovered points within the generated code on a regular basis.
It’s kind of like whac-a-mole, each time you run the workflow, one thing
else occurs, and also you add one thing else to the prompts or the workflow
to attempt to mitigate that.
These had been a few of the patterns which are notably problematic for
an actual world enterprise software or digital product:
Overeagerness
We ceaselessly acquired extra endpoints and options that we didn’t
ask for within the necessities. We even noticed it add enterprise logic that we
did not ask for, e.g. when it got here throughout a website time period that it knew how
to calculate. (“Professional-rated income, I do know what that’s! Let me add the
calculation for that.”)
Doable mitigation
Could be reigned in to an extent with the prompts, and repeatedly
reminding AI that we ONLY need what’s specified. The reviewer agent can
additionally assist catch a few of the extra code (although we have seen the reviewer
delete an excessive amount of code in its try to repair that). However this nonetheless
occurred in some form or kind in nearly all of our iterations. We made
one try at decreasing the temperature to see if that may assist, however
because it was just one try in an earlier model of the setup, we won’t
conclude a lot from the outcomes.
Gaps within the necessities can be stuffed with assumptions
A precedence: String area in an entity was assumed by AI to have the
worth set “1”, “2”, “3”. After we launched the enlargement to extra fields
later, although we did not ask for any adjustments to the precedence
area, it modified its assumptions to “low”, “medium”, “excessive”. Other than
the truth that it could be loads higher to have launched an Enum
right here, so long as the assumptions keep within the assessments solely, it won’t be
a giant situation but. However this may very well be fairly problematic and have heavy
influence on a manufacturing database if it could occur to a default
worth.
Doable mitigation
We might one way or the other must be sure that the necessities we give are as
full and detailed as attainable, and embrace a price set on this case.
However traditionally, we have now not been nice at that… We have now seen some AI
be very useful in serving to people discover gaps of their necessities, however
the danger of incomplete or incoherent necessities all the time stays. And
the purpose right here was to check the boundaries of AI autonomy, in order that
autonomy is unquestionably restricted at this necessities step.
Brute pressure fixes
“[There is a ] lazy-loaded relationship that’s inflicting JSON
serialization issues. Let me repair this by including @JsonIgnore to the
area”. Related issues have additionally occurred to me a number of instances in
agent-assisted coding classes, from “the construct is operating out of
reminiscence, let’s simply allocate extra reminiscence” to “I can not get the check to
work proper now, let’s skip it for now and transfer on to the following job”.
Doable mitigation
We have no thought find out how to stop this.
Declaring success despite purple assessments
AI ceaselessly claimed the construct and assessments had been profitable and moved
on to the following step, although they weren’t, and although our
directions explicitly said that the duty shouldn’t be carried out if construct or
assessments are failing.
Doable mitigation
This is perhaps simpler to repair than the opposite issues talked about right here,
by a extra subtle agent workflow setup that has deterministic
checkpoints and doesn’t permit the workflow to proceed except assessments are
inexperienced. Nevertheless, expertise from agentic workflows in enterprise course of
automation have already proven that LLMs discover methods to get round
that. Within the case of code era,
I might think about they might nonetheless delete or skip assessments to get past that
checkpoint.
Static code evaluation points
We ran SonarQube static code evaluation on
two of the generated codebases, right here is an excerpt of the problems that
had been discovered:
| Difficulty |
Severity |
Sonar tags |
Notes |
| Change this utilization of ‘Stream.gather(Collectors.toList())’ with ‘Stream.toList()’ and make sure that the listing is unmodified. |
Main |
java16 |
From Sonar’s “Why”: The important thing downside is that .gather(Collectors.toList()) truly returns a mutable type of Record whereas within the majority of instances unmodifiable lists are most well-liked. |
| Merge this if assertion with the enclosing one. |
Main |
clumsy |
Generally, we noticed loads of ifs and nested ifs within the generated code, specifically in mapping and validation code. On a facet word, we additionally noticed loads of null checks with `if` as an alternative of the usage of `Non-obligatory`. |
| Take away this unused methodology parameter “occasion”. |
Main |
cert, unused |
From Sonar’s “Why”: A typical code scent often called unused operate parameters refers to parameters declared in a operate however not used wherever inside the operate’s physique. Whereas this may appear innocent at first look, it may well result in confusion and potential errors in your code. |
| Full the duty related to this TODO remark. |
Information |
|
AI left TODOs within the code, e.g. “// TODO: This may be populated by becoming a member of with lead entity or separate service calls. For now, we’ll depart it null – it may be populated by the service layer” |
| Outline a continuing as an alternative of duplicating this literal (…) 10 instances. |
Important |
design |
From Sonar’s “Why”: Duplicated string literals make the method of refactoring advanced and error-prone, as any change would must be propagated on all occurrences. |
| Name transactional strategies by way of an injected dependency as an alternative of instantly by way of ‘this’. |
Important |
|
From Sonar’s “Why”: A way annotated with Spring’s @Async, @Cacheable or @Transactional annotations won’t work as anticipated if invoked instantly from inside its class. |
I might argue that each one of those points are related observations that result in
more durable and riskier maintainability, even in a world the place AI does all of the
upkeep.
Doable mitigation
It’s in fact attainable so as to add an agent to the workflow that appears on the
points and fixes them one after the other. Nevertheless, I do know from the actual world that not
all of them are related in each context, and groups typically intentionally mark
points as “will not repair”. So there’s nonetheless some nuance