
Software program is a rising element of right now’s mission-critical techniques. As organizations turn out to be extra depending on software-driven expertise, safety and resilience dangers to their missions additionally enhance. Managing these dangers is simply too typically deferred till after deployment on account of competing priorities, reminiscent of satisfying value and schedule targets. Nonetheless, failure to deal with these dangers early within the techniques lifecycle can’t solely enhance operational impression and mitigation prices, however it might additionally severely restrict administration choices.
For Division of Protection (DoD) weapon techniques, it’s particularly necessary to handle software program safety and resilience dangers. Proactively figuring out and correcting software program vulnerabilities and weaknesses minimizes the danger of cyber-attacks, weapons system failures, and different disruptions that might jeopardize DoD missions. The GAO has recognized software program and cybersecurity as persistent challenges throughout the portfolio of DoD weapon techniques. To deal with these challenges, acquisition packages ought to begin managing a system’s safety and resilience dangers early within the lifecycle and proceed all through the system’s lifespan.
This submit introduces the Safety Engineering Framework, an in depth schema of software-focused engineering practices that acquisition packages can use to handle safety and resilience dangers throughout the lifecycle of software-reliant techniques.
Software program Assurance
Software program assurance is a stage of confidence that, all through its lifecycle, software program capabilities as meant and is freed from vulnerabilities, both deliberately or unintentionally designed or inserted as a part of the software program. Software program assurance is more and more necessary to organizations throughout all sectors due to software program’s rising affect in mission-critical techniques. Managing software program assurance is a problem due to the expansion in functionality, complexity, and interconnection amongst software-reliant techniques.
For instance, think about how the scale of flight software program has elevated over time. Between 1960 and 2000, the extent of general system performance that software program supplies to navy plane pilots elevated from 8 % to 80 %. On the identical time, the scale of software program in navy plane grew from 1,000 strains of code within the F-4A to 1.7 million strains of code (MLOC) within the F-22 and 8 million strains within the F-35. This development is predicted to proceed over time. As software program exerts extra management over complicated techniques (e.g., navy plane), the potential danger posed by vulnerabilities will enhance correspondingly.
Software program Defects and Vulnerabilities: A Lifecyle Perspective
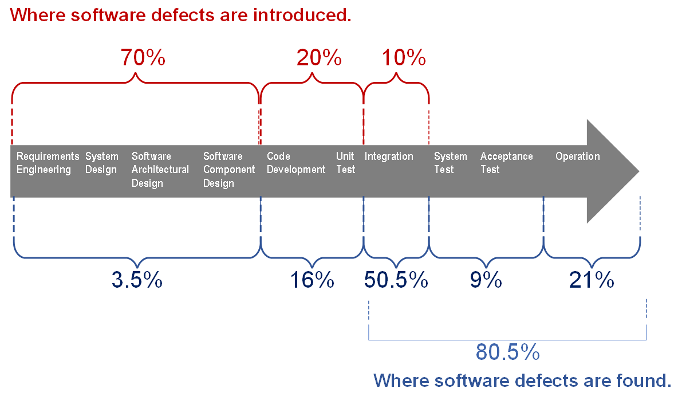
Determine 1 beneath highlights the speed of defect introduction and identification throughout the lifecycle. This was derived from knowledge introduced within the SEI report Reliability Validation and Enchancment Framework. Research of safety-critical techniques, notably DoD avionics software program techniques, present that 70 % of all errors are launched throughout necessities and structure design actions. Nonetheless, solely 20 % of the errors are discovered by the top of code growth and unit check, whereas 80.5 % of the errors are found at or after integration testing. The rework effort to appropriate necessities and design issues in later phases will be as excessive as 300 to 1,000 instances the trouble of in-phase correction. Even after the rework, undiscovered errors are prone to stay.
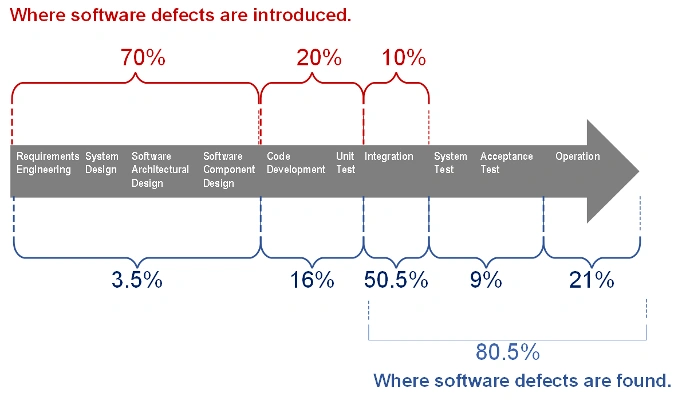
Determine 1: Fee of Defect Introduction and Identification throughout the Lifecycle
Given the complexities concerned in creating large-scale, software-reliant techniques, it’s comprehensible that no software program is freed from dangers. Defects exist even within the highest high quality software program. For instance, best-in-class code can have as much as 600 defects per MLOC, whereas average-quality code usually has round 6,000 defects per MLOC, and a few of these defects are weaknesses that may result in vulnerabilities. Analysis signifies that roughly 5 % of software program defects are safety vulnerabilities. Because of this, best-in-class code can have as much as 30 vulnerabilities per MLOC. For average-quality code, the variety of safety vulnerabilities will be as excessive as 300 per MLOC. You will need to notice that the defect charges cited listed here are estimates that present basic perception into the problem of code high quality and variety of vulnerabilities in code. Defect charges in particular initiatives can range enormously. Nonetheless, these estimates spotlight the significance of decreasing safety vulnerabilities in code throughout software program growth. Safe coding practices, code evaluations, and code evaluation instruments are necessary methods to determine and proper recognized weaknesses and vulnerabilities in code.
As illustrated in Determine 1, safety and resilience should be managed throughout the lifecycle, beginning with the event of high-level system necessities by means of operations and sustainment (O&S). Program and system stakeholders ought to apply main practices for buying, engineering, and deploying safe and resilient software-reliant techniques. In 2014, the SEI initiated an effort to doc main practices for managing safety and resilience dangers throughout the techniques lifecycle, offering an strategy for constructing safety and resilience right into a system slightly than bolting them on after deployment. This effort produced a number of cybersecurity engineering options, most notably the Safety Engineering Threat Evaluation (SERA) methodology and the Acquisition Safety Framework (ASF). Late final yr, the SEI launched the Safety Engineering Framework.
Safety Engineering Framework (SEF)
The SEF is a set of software-focused engineering practices for managing safety and resilience dangers throughout the techniques lifecycle, beginning with necessities definition and persevering with by means of O&S. It supplies a roadmap for constructing safety and resilience into software-reliant techniques previous to deployment and sustaining these capabilities throughout O&S. The SEF builds on the foundational analysis of SERA and the ASF, offering in-depth steering that elaborates on main engineering practices and methods to carry out them.
SEF practices assist be sure that engineering processes, software program, and instruments are safe and resilient, thereby decreasing the danger that attackers will disrupt program and system data and belongings. Acquisition packages can use the SEF to evaluate their present engineering practices and chart a course for enchancment, in the end decreasing safety and resilience dangers in deployed software-reliant techniques.
Safety and Resilience
At its core, the SEF is a risk-based framework that addresses each safety and resilience:
Threat administration supplies the inspiration for managing safety and resilience. In actual fact, danger administration strategies, instruments, and strategies are used to handle each. Nonetheless, safety and resilience view danger from totally different views: Safety considers dangers from a safety viewpoint, whereas resilience considers danger from a perspective of adapting to situations, stresses, assaults, and compromises. As proven in Determine 2, there’s some overlap between the danger views of safety and resilience. On the identical time, safety and resilience every have distinctive dangers and mitigations.
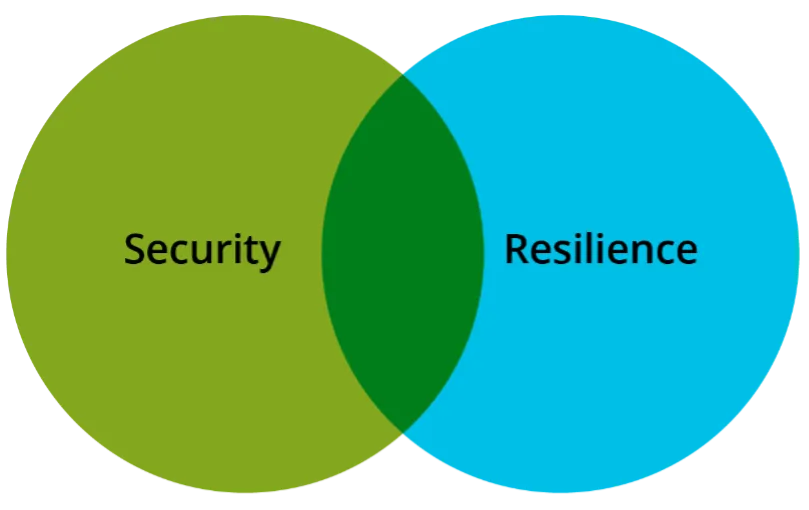
Determine 2: Threat Views: Safety Versus Resilience
The SEF specifies practices for managing safety and resilience dangers. The attitude the group adopts—safety, resilience, or a mix of the 2—influences the dangers an acquisition group considers throughout an evaluation and the set of controls which can be accessible for danger mitigation. Due to the associated nature of safety and resilience, the SEF (and the rest of this weblog submit) makes use of the time period safety/resilience all through.
SEF Construction
As illustrated in Determine 3, the SEF has a hierarchy of domains, objectives, and practices:
- Domains occupy the highest stage of the SEF hierarchy. A website captures a singular administration or technical perspective of managing safety/resilience dangers throughout the techniques lifecycle. Every area is supported by two or extra objectives, which type the following stage of the SEF hierarchy.
- Targets outline the capabilities {that a} program leverages to construct safety/resilience right into a software-reliant system. Associated objectives belong to the identical SEF area.
- Practices inhabit the ultimate and most detailed stage within the hierarchy. Practices describe actions that assist the achievement of SEF objectives. The SEF phrases practices as questions. Associated practices belong to the identical SEF purpose.
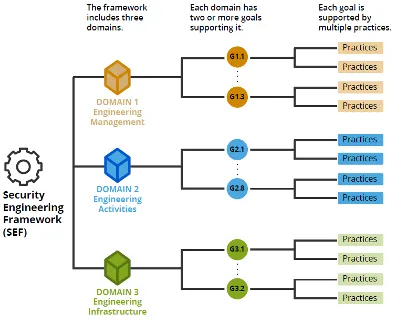
Determine 3: SEF Group and Construction
The SEF contains 3 domains, 13 objectives, and 119 practices. The following part describes the SEF’s domains and objectives.
Area 1: Engineering Administration
This area supplies a basis for fulfillment by making certain that safety/resilience actions are deliberate and managed. The target of Area 1 is to handle safety/resilience dangers successfully within the system being acquired and developed.
Program and engineering managers mix their technical experience with their enterprise and mission information to supply technical administration and organizational management for engineering initiatives. Managers are tasked with planning, organizing, and directing an acquisition program’s engineering and growth actions. Engineering administration is a specialised sort of administration that’s wanted to guide engineering or technical personnel and initiatives efficiently. Area 1 contains the next three objectives:
- Objective 1.1: Engineering Exercise Administration. Safety/resilience engineering actions throughout the lifecycle are deliberate and managed.
- Objective 1.2: Engineering Threat Administration. Safety/resilience dangers that may have an effect on the system are assessed and managed throughout system design and growth.
- Objective 1.3: Unbiased Evaluation. An unbiased evaluation of this system or system is carried out.
Area 2: Engineering Actions
This area addresses the day-to-day practices which can be important for constructing safety/resilience right into a software-reliant system. The target of Area 2 is to combine safety/resilience into this system’s present engineering practices. All techniques lifecycles tackle a standard set of engineering actions, starting with necessities specification and persevering with by means of system O&S. Area 2 expands the main focus of a program’s techniques lifecycle mannequin to incorporate safety/resilience. Area 2 contains the next eight objectives:
- Objective 2.1: Necessities. Safety/resilience necessities for the system and its software program elements are specified, analyzed, and managed.
- Objective 2.2: Structure. Safety/resilience dangers ensuing from the system and software program architectures are assessed and mitigated.
- Objective 2.3: Third-Occasion Parts. Safety/resilience dangers that may have an effect on third-party elements are recognized and mitigated.
- Objective 2.4: Implementation. Safety/resilience controls are applied, and weaknesses and vulnerabilities in software program code are assessed and managed.
- Objective 2.5: Take a look at and Analysis. Safety/resilience dangers that may have an effect on the built-in system are recognized and remediated throughout check and analysis.
- Objective 2.6: Authorization to Function. The operation of the system is permitted, and the residual danger to operations is explicitly accepted.
- Objective 2.7: Deployment. Safety/resilience is addressed in transition and deployment actions.
- Objective 2.8: Operations and Sustainment. Safety/resilience dangers and points are recognized and resolved because the system is used and supported within the operational atmosphere.
Area 3: Engineering Infrastructure
This area manages safety/resilience dangers within the engineering, growth, check, and coaching environments. The targets of Area 3 are to make use of software program, instruments, and applied sciences that assist this system’s engineering and growth actions and to handle safety/resilience dangers within the engineering infrastructure. Engineers and builders use a wide range of software program, instruments, and applied sciences to assist their design and growth actions. Safety/resilience engineering software program, instruments, and applied sciences should be procured, put in, and built-in with this system’s present engineering infrastructure.
The engineering infrastructure is the a part of the IT infrastructure that helps engineering and growth actions carried out by personnel from the acquisition program, contractors, and suppliers. Because of this, the engineering infrastructure will be an assault vector into the software-reliant system that’s being acquired and developed. IT assist groups want to make sure that they’re making use of safety/resilience practices when managing the engineering infrastructure to make sure that danger is being managed appropriately. Area 3 contains the next two objectives:
- Objective 3.1: Engineering Software program, Instruments, and Applied sciences. Safety/resilience engineering software program, instruments, and applied sciences are built-in with the engineering infrastructure.
- Objective 3.2: Infrastructure Operations and Sustainment. Safety/resilience dangers within the engineering infrastructure are recognized and mitigated.
SEF Practices and Steering
SEF domains present the organizing construction for the framework’s technical content material, which is the gathering of objectives and practices. The SEF’s in-depth steering for all objectives and practices describes the aptitude represented by every purpose, together with its function, related context, and supporting practices. SEF steering additionally defines the important thing ideas and background data wanted to know the intent of every observe.
Safety Engineering Framework (SEF): Managing Safety and Resilience Dangers Throughout the Methods Lifecycle accommodates in-depth steering for all objectives and practices.
Companion with the SEI to Handle Safety and Resilience Dangers
The SEF paperwork main engineering practices for managing safety/resilience dangers throughout the techniques lifecycle. The SEI supplies open entry to SEF steering, strategies, and supplies. Future work associated to the SEF will focus totally on transitioning SEF ideas and practices to the neighborhood. The SEI plans to work with DoD packages to pilot the SEF and incorporate classes realized into future model of the framework.
Lastly, the SEF growth crew continues to hunt suggestions on the framework, together with how it’s getting used and utilized. This data will assist affect the long run course of the SEF in addition to the SEI’s work on documenting main practices for software program safety.



{kind=link}
{kind=link}
{kind=link}