{kind=link}

A remarkably widespread case in giant established enterprises is that there
are techniques that no one desires to the touch, however everybody depends upon. They run
payrolls, deal with logistics, reconcile stock, or course of buyer orders.
They’ve been in place and evolving slowly for many years, constructed on stacks no
one teaches anymore, and maintained by a shrinking pool of specialists. It’s
onerous to seek out an individual (or a crew) that may confidently say that they know
the system nicely and are prepared to offer the useful specs. This
state of affairs results in a extremely lengthy cycle of research, and lots of applications get
lengthy delayed or stopped mid means due to the Evaluation Paralysis.

These techniques typically stay inside frozen environments: outdated databases,
legacy working techniques, brittle VMs. Documentation is both lacking or
hopelessly out of sync with actuality. The individuals who wrote the code have lengthy
since moved on. But the enterprise logic they embody remains to be essential to
day by day operations of 1000’s of customers. The result’s what we name a black
field: a system whose outputs we will observe, however whose inside workings stay
opaque. For CXOs and know-how leaders, these black packing containers create a
modernization impasse
- Too dangerous to exchange with out totally understanding them
- Too pricey to take care of on life assist
- Too essential to disregard
That is the place AI-assisted reverse engineering turns into not only a
technical curiosity, however a strategic enabler. By reconstructing the
useful intent of a system,even when it’s lacking the supply code, we will
flip concern and opacity into readability. And with readability comes the arrogance to
modernize.
The System we Encountered
The system itself was huge in each scale and complexity. Its databases
throughout a number of platforms contained greater than 650 tables and 1,200 saved
procedures, reflecting many years of evolving enterprise guidelines. Performance
prolonged throughout 24 enterprise domains and was offered by means of practically 350
consumer screens. Behind the scenes, the appliance tier consisted of 45
compiled DLLs, every with 1000’s of capabilities and nearly no surviving
documentation. This intricate mesh of information, logic, and consumer workflows,
tightly built-in with a number of enterprise techniques and databases, made
the appliance extraordinarily difficult to modernize
Our process was to hold out an experiment to see if we might use AI to
create a useful specification of the prevailing system with enough
element to drive the implementation of a alternative system. We accomplished
the experiment section for an finish to finish skinny slice with reverse and ahead
engineering. Our confidence degree is greater than excessive as a result of we did a number of
ranges of cross checking and verification. We walked by means of the reverse
engineered useful spec with sys-admin / customers to substantiate the supposed
performance and in addition verified that the spec we generated is enough
for ahead engineering as nicely.
The consumer issued an RFP for this work, with we estimated would take 6
months for a crew of peak 20 individuals. Sadly for us, they determined to work
with considered one of their current most popular companions, so we can’t have the ability to see
how our experiment scales to the complete system in observe. We do, nevertheless,
assume we realized sufficient from the train to be value sharing with our
skilled colleagues.
Key Challenges
- Lacking Supply Code: legacy understanding is already complicated if you
have supply code and an SME (in some kind) to place every little thing collectively. When the
supply code is lacking and there are not any specialists it’s a fair better problem.
What’s left are some compiled binaries. These aren’t the current binaries that
are simple to decompile because of wealthy metadata (like .NET assemblies or JARs), these
are even older binaries: the type that you just may see in outdated home windows XP below
C:Home windowssystem32. Even when the database is accessible, it doesn’t inform
the entire story. Saved procedures and triggers encode many years of amassed
enterprise guidelines. Schema displays compromises made based mostly on context unknown. - Outdated Infrastructure: OS and DB reached finish of life, gone its
LTS. Utility has been in a frozen state within the type of VM resulting in
important danger to not solely enterprise continuity, additionally considerably rising
safety vulnerability, non compliance and danger legal responsibility. - Institutional Data Misplaced: whereas 1000’s of finish customers are
constantly utilizing the system, there’s hardly any enterprise data accessible
past the occasional assist actions. The stay system is the most effective supply of
data. The one dependable view of performance is what customers see on display.
However the UI captures solely the “final mile” of execution. Behind every display lies a
tangled net of logic deeply built-in to a number of different core techniques. It is a
widespread problem, and this method was no exception, having a historical past of a number of
failed makes an attempt to modernize.
Our Purpose
The target is to create a wealthy, complete useful specification
of the legacy system without having its authentic code, however with excessive
confidence. This specification then serves because the blueprint for constructing a
fashionable alternative software from a clear slate.
- Perceive total image of the system boundary and the mixing
patterns - Construct detailed understanding of every useful space
- Determine the widespread and distinctive eventualities
To make sense of a black-box system, we wanted a structured method to pull
collectively fragments from completely different sources. Our precept was easy: don’t
attempt to recuperate the code — reconstruct the useful intent.
Our Multi Lens Method
It was a 3 tier structure – Internet Tier (ASP), App Tier (DLL) and
Persistence (SQL). This structure sample gave us a soar begin even with out
supply repo. We extracted ASP recordsdata and DB schema, saved procedures from the
manufacturing system. For App Tier we solely have the native binaries. With all
this info accessible, we deliberate to create a semi-structured
description of software habits in pure language for the enterprise
customers to validate their understanding and expectations and use the validated
useful spec to do accelerated ahead engineering. For the semi-structured
description, our strategy had broadly two elements
- Utilizing AI to attach dots throughout completely different information sources
- AI assisted binary Archaeology to uncover the hidden performance from
the native DLL recordsdata
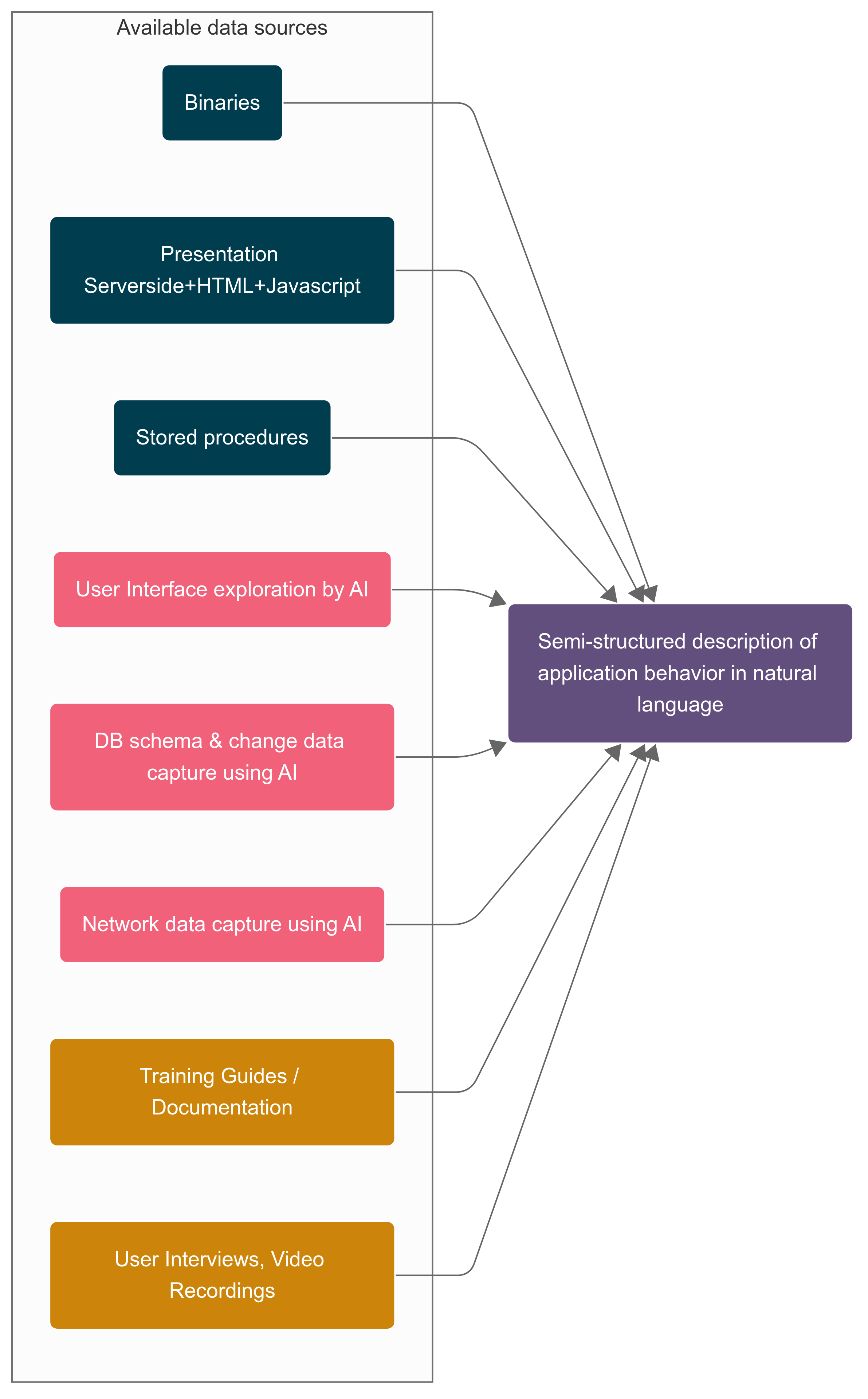
Join dots throughout completely different information sources
UI Layer Reconstruction
Looking the prevailing stay software and screenshots, we recognized the
UI components. Utilizing the ASP and JS content material the dynamic behaviour related
with the UI factor could possibly be added. This gave us a UI spec like under:
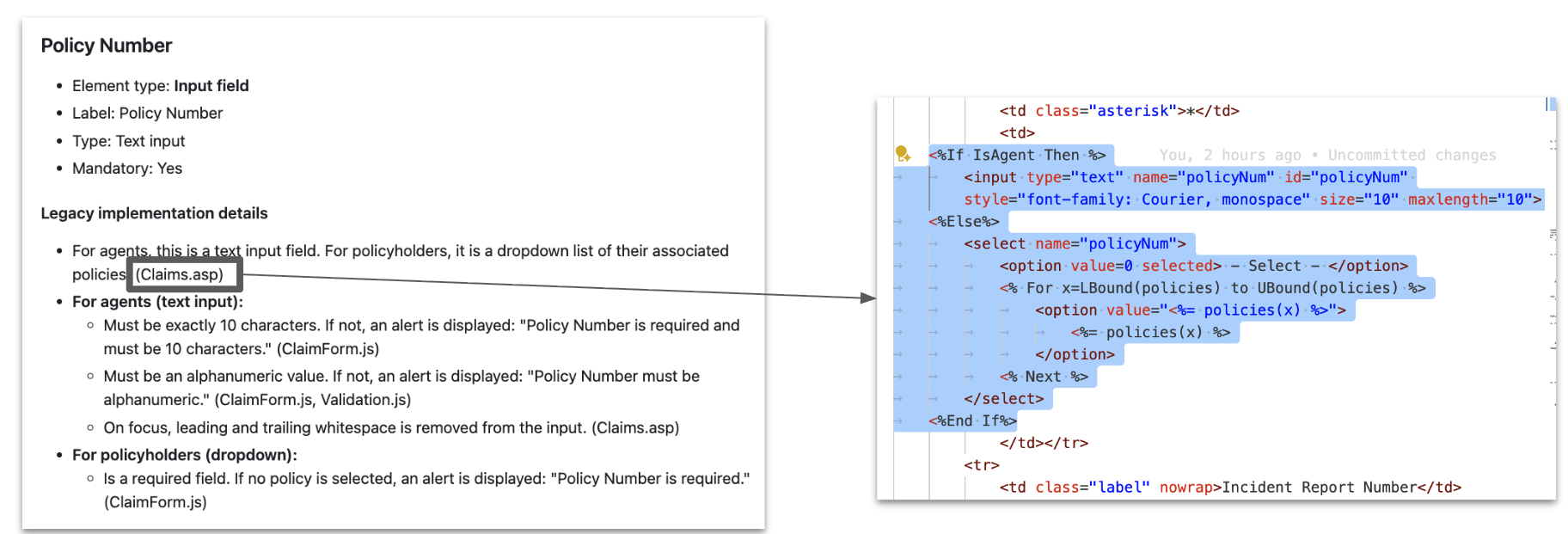
What we appeared for: validation guidelines, navigation paths, hidden fields. One
of the important thing challenges we confronted from the early stage was hallucination, each
step we added an in depth lineage to make sure that we cross verify and ensure. In
the above instance we had the lineage of the place it comes from. Following this
sample, for each key info we added the lineage together with the
context. Right here the LLM actually sped up the summarizing of enormous numbers of
display definitions and consolidating logic from ASP and JS sources with the
already recognized UI layouts and area descriptions that may in any other case take
weeks to create and consolidate.
Discovery with Change Knowledge Seize (CDC)
We deliberate to make use of Change Knowledge Seize (CDC) to hint how UI actions mapped
to database exercise, retrieving change logs from MCP servers to trace the
workflows. Atmosphere constraints meant CDC might solely be enabled partially,
limiting the breadth of captured information.
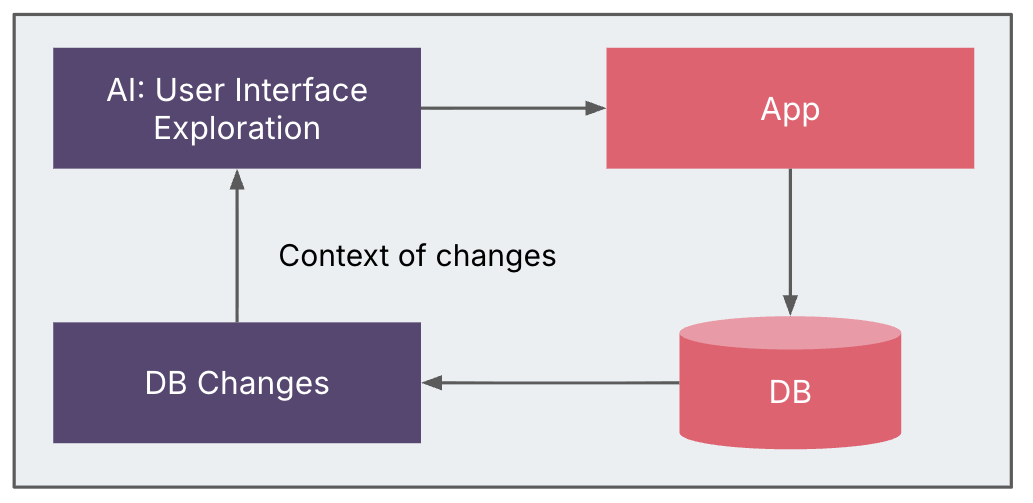
Different potential sources—corresponding to front-end/back-end community site visitors,
filesystem modifications, further persistence layers, and even debugging
breakpoints—stay viable choices for finer-grained discovery. Even with
partial CDC, the insights proved invaluable in linking UI habits to underlying
information modifications and enriching the system blueprint.
Server Logic Inferance
We then added extra context by supplying
typelibs that had been extracted from the native binaries, and saved procedures,
and schema extracted from the database. At this level with details about
structure, presentation logic, and DB modifications, the server logic will be inferred,
which saved procedures are doubtless known as, and which tables are concerned for
most strategies and interfaces outlined within the native binaries. This course of leads
to an Inferred Server Logic Spec. LLM helped in proposing doubtless relationships
between App tier code and procedures / tables, which we then validated by means of
noticed information flows.

AI assisted Binary Archaeology
Probably the most opaque layer was the compiled binaries (DLLs, executables). Right here,
we handled binaries as artifacts to be decoded somewhat than rebuilt. What we
appeared for: name bushes, recurring meeting patterns, candidate entry factors.
AI assisted in bulk summarizing disassembled code into human-readable
hypotheses, flagging possible perform roles — at all times validated by human
specialists.
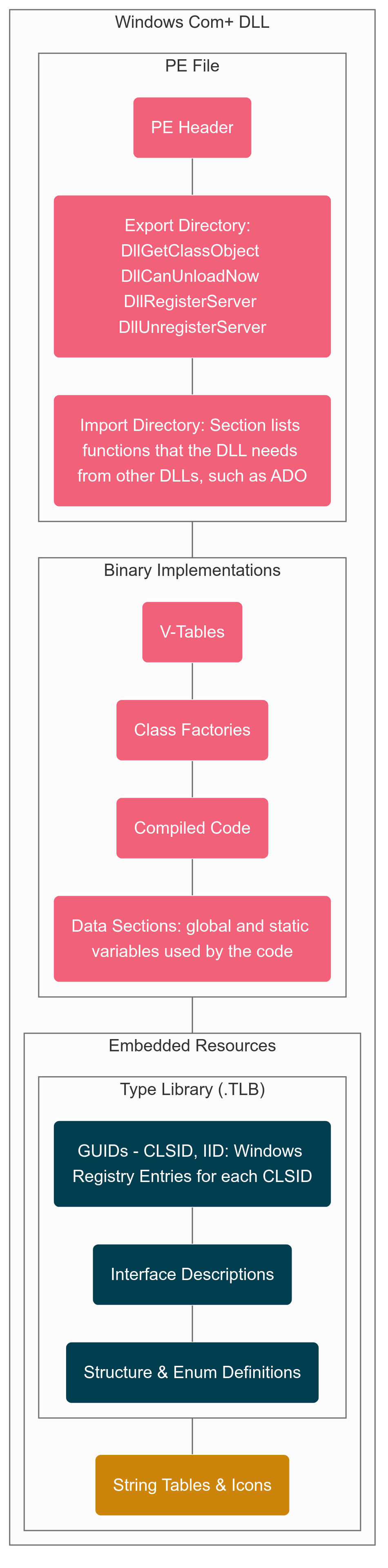
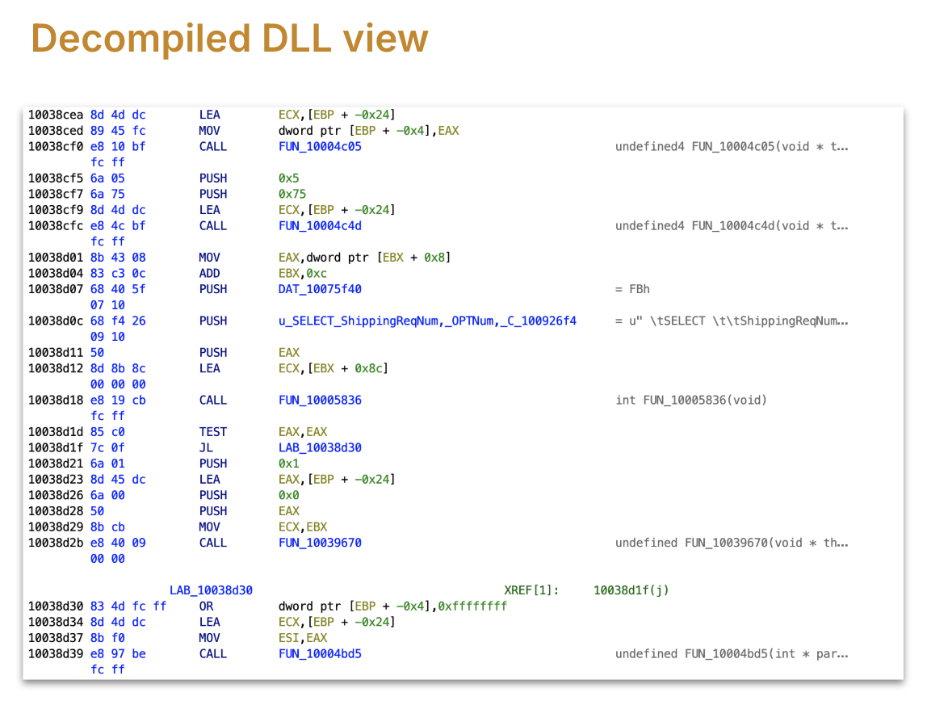
The influence of not having good deployment practices was evident with the
Manufacturing machine having a number of variations of the identical file with file names
used to determine completely different variations and complicated names. Timestamps offered
some clues. Finding the binaries was additionally achieved utilizing the home windows registry.
There have been additionally proxies for every binary that handed calls to the precise binary
to permit the App tier to run on a unique machine than the online tier. The
proven fact that proxy binaries had the identical title as goal binaries provides to
confusion.
We did not have to have a look at binary code of DLL. Instruments like Ghidra assist to
decompile binary to a giant set of ASM capabilities. A few of these instruments even have
the choice to transform ASM into C code however we discovered that conversions aren’t
at all times correct. In our case decompilation to C missed an important lead.
Every DLL had 1000s of meeting capabilities, and we settled on an strategy
the place we determine the related capabilities for a useful space and decode what
that subtree of related capabilities does.
Prior Makes an attempt
Earlier than we arrived at this strategy, we tried
- brute-force technique: Added all meeting capabilities right into a workspace, and used
the LLM agent to make it humanly readable pseudocode. Confronted a number of challenges
with this. Ran out of the 1 million context window as LLM tried to finally
load all capabilities because of dependencies (references it encountered e.g. perform
calls, and different capabilities referencing present one) - Break up the set of capabilities into a number of batches, a file every with 100s of
capabilities, after which use LLM to research every batch in isolation. We confronted loads
of hallucination points, and file dimension points whereas streaming to mannequin. A couple of
capabilities had been transformed meaningfully however a variety of different capabilities did not make
any-sense in any respect, all seemed like comparable capabilities, on cross checking we
realised the hallucination impact. - The following try was to transform the capabilities one after the other, to
guarantee LLM is supplied with a contemporary slender window of context to restrict
hallucination. We confronted a number of challenges (API utilization restrict, fee
limits) – We could not confirm what LLM translation of enterprise logic
was proper or flawed. Then we could not join the dots between these
capabilities. Fascinating word, we even discovered some C++ STDLIB capabilities
like
std::vector::insert
on this strategy. We discovered loads had been truly unwind capabilities purely
used to name destructors when exception occurs (stack
unwinding)
destructors, catch block capabilities. Clearly we wanted to deal with
enterprise logic and ignore the compiled library capabilities, additionally blended
into the binary
After these makes an attempt we determined to vary our strategy to slice the DLL based mostly
on useful space/workflow somewhat than take into account the whole meeting code.
Discovering the related perform
The primary problem within the useful space / workflow strategy is to discover a
hyperlink or entry level among the many 1000s of capabilities.
One of many accessible choices was to fastidiously take a look at the constants and
strings within the DLL. We used the historic context: late Nineties or early 2000
widespread architectural sample adopted in that interval was to insert information into
the DB: was to both “choose for insert” or “insert/replace dealt with by saved
process” or by way of ADO (which is an ORM). Curiously we discovered all of the
patterns in numerous elements of the system.
Our performance was about inserting or updating the DB on the finish of the
course of however we could not discover any insert or replace queries within the strings, no
saved process to carry out the operation both. For the performance we
had been searching for, it occurred to truly use a SELECT by means of SQL after which
up to date by way of ADO (activex information object microsoft library).
We obtained our break based mostly on the desk title talked about within the
strings/constants, and this led to discovering the perform which is utilizing that
SQL assertion. Preliminary take a look at that perform did not reveal a lot, it could possibly be
in the identical useful space however a part of a unique workflow.
Constructing the related subtree
ASM code, and our disassembly device, gave us the perform name reference
information, utilizing it we walked up the tree, assuming the assertion execution is one
of the leaf capabilities, we navigated to the dad or mum which known as this to
perceive its context. At every step we transformed ASM into pseudo code to
construct context.
Earlier after we transformed ASM to pseudocode utilizing brute-force we could not
cross confirm whether it is true. This time we’re higher ready as a result of we all know
to anticipate what could possibly be the potential issues that might occur earlier than a
sql execution. And use the context that we gathered from earlier steps.
We mapped out related capabilities utilizing this name tree navigation, generally
we’ve got to keep away from flawed paths. We realized about context poisoning in a tough
means, in-advertely we handed what we had been searching for into LLM. From that
second LLM began colouring its output focused in direction of what we had been trying
for, main into flawed paths and eroding belief. We needed to recreate a clear
room for AI to work in throughout this stage.
We obtained a excessive degree define of what the completely different capabilities had been, and what
they could possibly be doing. For a given work stream, we narrowed down from 4000+
capabilities to 40+ capabilities to cope with.
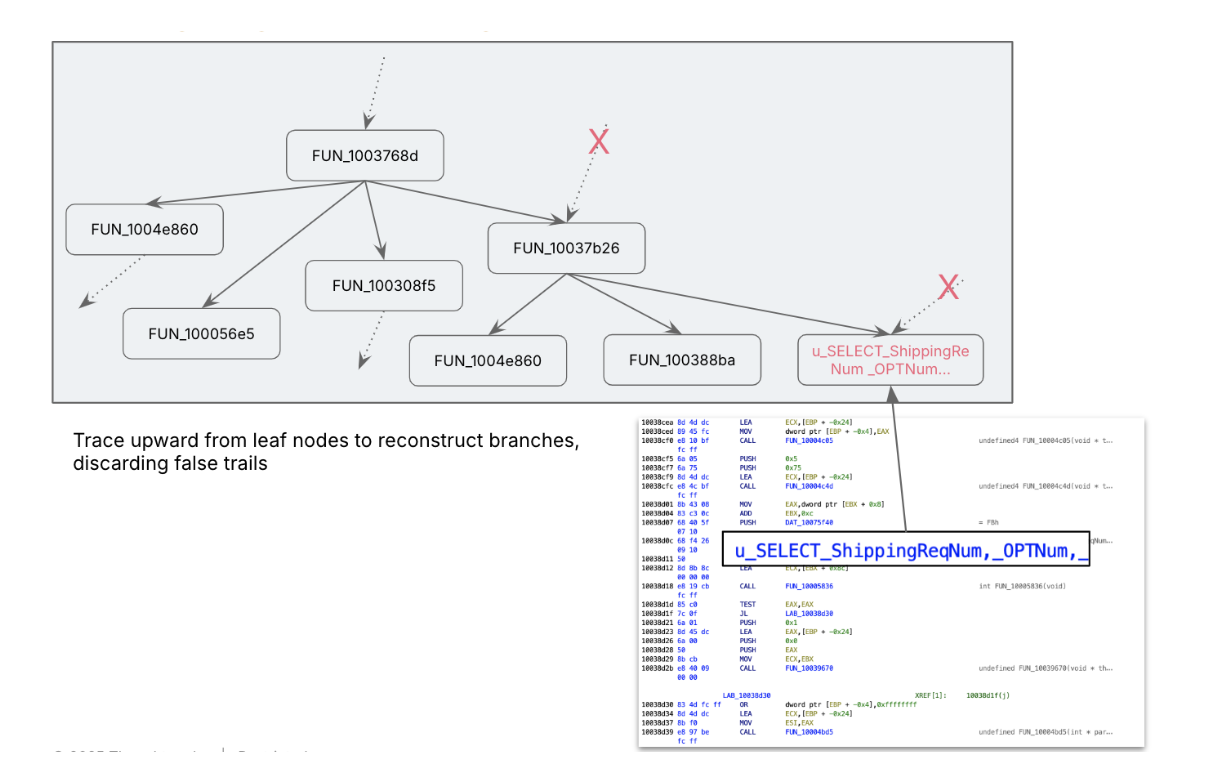
Multi-Go Enrichment
AI accelerated the meeting archaeology layer by layer, cross by cross: We
utilized multi cross enrichment. In every cross, we both navigated from leaf
node to high of the tree or reverse, in every step we enriched the context of
the perform both utilizing its dad and mom context or its youngster context. This
helped us to vary the technical conversion of pseudocode right into a useful
specification. We adopted easy methods like asking LLM to provide
significant technique names based mostly on identified context. After a number of passes we construct
out the complete useful context.
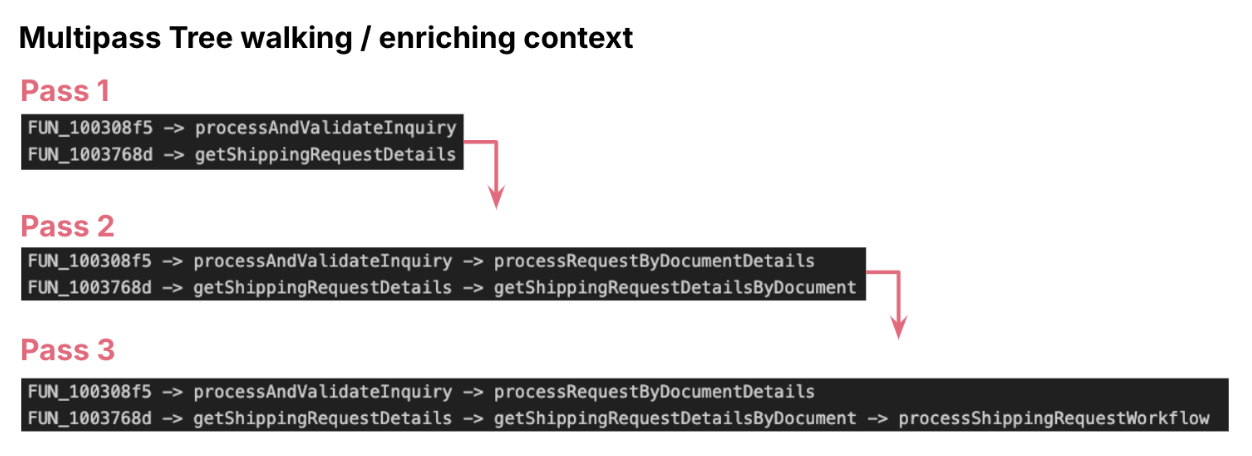
Validating the entry level
The final and significant problem was to substantiate the entry perform. Typical
to C++, digital capabilities made it more durable to hyperlink entry capabilities in school
definition. Whereas performance appeared full beginning with the basis node,
we weren’t certain if there’s some other further operation occurring in a
dad or mum perform or a wrapper. Life would have been simpler if we had debugger
enabled, a easy break level and assessment of the decision stack would have
confirmed it.
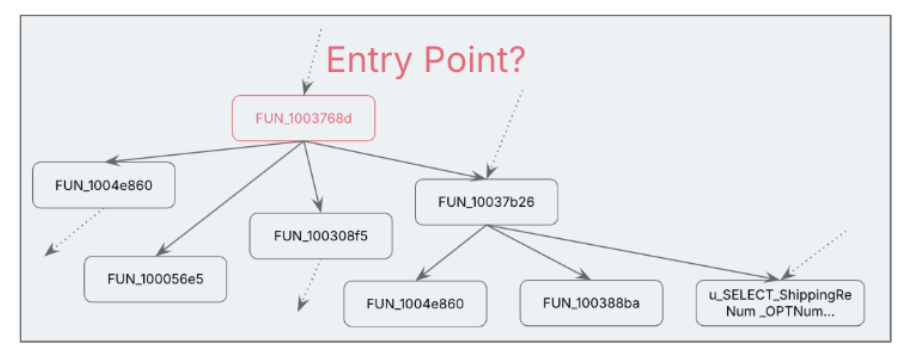
Nevertheless with triangulation methods, like:
- Name stack evaluation
- Validating argument signatures and the the return signature within the
stack - Cross-checking with UI layer calls (e.g., associating technique signature
with the “submit” name from Internet tier, checking parameter sorts and utilization, and
validating towards that context)
Constructing the Spec from Fragments to Performance
By integrating the reconstructed components from the earlier phases:UI Layer
Reconstruction, Discovery with CDC, Server Logic Inference, and Binary
evaluation of App tier, a whole useful abstract of the system is recreated
with excessive confidence. This complete specification types a traceable and
dependable basis for enterprise assessment and modernization/ahead engineering
efforts.
From our work, a set of repeatable practices emerged. These aren’t
step-by-step recipes — each system is completely different — however guiding patterns that
form how you can strategy the unknown.
- Begin The place Visibility is Highest: Start with what you’ll be able to see and belief:
screens, information schemas, logs. These give a basis of observable habits
earlier than diving into opaque binaries. This avoids evaluation paralysis by anchoring
early progress in artifacts customers already perceive. - Enrich in Passes: Don’t overload AI or people with the entire system at
as soon as. Break artifacts into manageable chunks, extract partial insights, and
progressively construct context. This reduces hallucination danger, reduces
assumptions, scales higher with giant legacy estates. - Triangulate The whole lot: By no means depend on a single artifact. Affirm each
speculation throughout no less than two unbiased sources — e.g., a display stream matched
towards a saved process, then validated in a binary name tree. It creates
confidence in conclusions, exposes hidden contradictions. - Protect Lineage: Observe the place every bit of inferred data comes
from — UI display, schema area, binary perform. This “audit path” prevents
false assumptions from propagating unnoticed. When questions come up later, you
can hint again to authentic proof. - Preserve People within the Loop: AI can speed up evaluation, nevertheless it can not
substitute area understanding. All the time pair AI hypotheses with professional validation,
particularly for business-critical guidelines. Helps to keep away from embedding AI errors
immediately into future modernization designs.
Conclusion and Key Takeaways
Blackbox reverse engineering, particularly when supercharged with AI, presents
important benefits for legacy system modernization:
- Accelerated Understanding: AI accelerates legacy system understanding from
months to weeks, reworking complicated duties like changing meeting code into
pseudocode and classifying capabilities into enterprise or utility classes. - Diminished Worry of Undocumented Techniques: organizations not have to
concern undocumented legacy techniques. - Dependable First Step for Modernization: reverse engineering turns into a
dependable and accountable first step towards modernization.
This strategy unlocks Clear Useful Specs even with out
supply code, Higher-Knowledgeable Choices for modernization and cloud
migration, Perception-Pushed Ahead Engineering whereas transferring away from
guesswork.
The long run holds a lot quicker legacy modernization because of the
influence of AI instruments, drastically decreasing steep prices and dangerous long-term
commitments. Modernization is predicted to occur in “leaps and bounds”. Within the
subsequent 2-3 years we might anticipate extra techniques to be retired than within the final 20
years. It is strongly recommended to begin small, as even a sandboxed reverse
engineering effort can uncover shocking insights